Experience replay is a critical component of Deep Q-Network (DQN), but it is difficult to analyze
the various parameters of experience replay as they are intertwined. The authors study the effect of
varying the maximum size of the replay buffer (replay capacity) and the number of gradient steps
taken for the oldest transition in the buffer (age of the oldest policy). Empirically, the
performance of the Rainbow agent increases as the replay capacity increases and as the age of the
oldest policy decreases.
However, unlike the Rainbow agent, the DQN agent does not improve as the replay capacity increases.
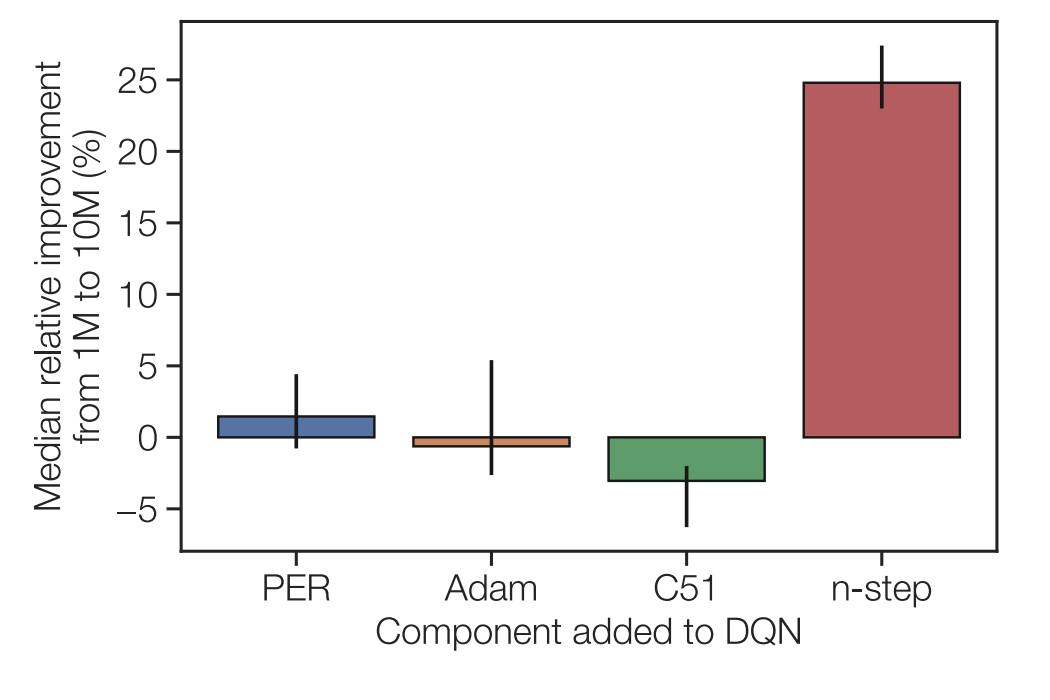
Through an additive and an ablative study of each component of the Rainbow (prioritized experience
replay, C51, Adam optimizer, and $n$-step returns), the authors find that $n$-step returns is the
component responsible for the discrepancy between DQN and Rainbow as the replay capacity increases.
Through a few testable hypotheses, the authors find that the effect can be partially explained by
increased replay capacity reducing the added variance of $n$-step returns. Because a bigger replay
buffer has more diverse transitions, the distribution of transitions shifts slower, mitigating the
effect of high variance $n$-step returns. However, the explanation is only partial, and that
additional causes may exist.