Notes from the ai.x 2018 Conference: Faster Reinforcement Learning via Transfer
Published
Overview of Reinforcement Learning and Policy Gradient Methods
Reinforcement Learning (RL) is the study of maximizing cumulative reward through trial and error. This talk focuses on Deep reinforcement learning, where neural networks are used to approximate functions in RL algorithms.
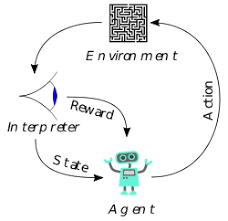
Policy is a function that chooses action based on recent observations. Policy gradient methods are a class of RL algorithms that directly optimize the policy iteratively by estimating which actions were good and bad and increasing the probability of good actions through gradient update. Policy gradient methods have a long history: the first paper dates back to 1992.
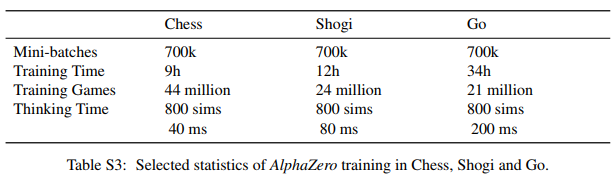
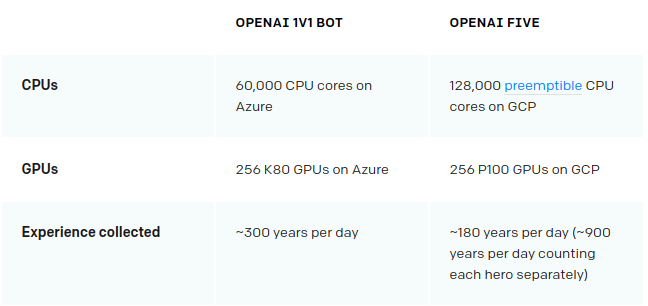
Policy gradient methods have had many success stories. Most notably, the Lee Sedol version of AlphaGo used REINFORCE, a primitive policy gradient method. Also, OpenAI Five used Proximal Policy Optimization (PPO) method to compete against professional Dota 2 players. However, despite such potential, it requires a lot of trial and error for reinforcement learning agents to perform at superhuman levels. AlphaZero played millions of games, and OpenAI Five used thousands of years of training. In contrast, humans can master the gameplay in one or two years.
Meta Reinforcement Learning
However, it is somewhat unfair to compare how long a human needs to master a task against the AI system, since humans bring a lot of prior knowledge to learning. Through millions of years of evolution and decades of experience, humans have adapted to solve relevant tasks quickly.
Then, a natural question would be whether this can be applied to AI systems. We want to train the AI system with some related tasks to accelerate learning on a new task. To distinguish the idea of incoprorating prior knowledge to an AI system with previous reinforcement learning attempts, we label them as “Classical RL” and “Meta RL” tasks. In “Classical RL”, the goal is to maximize reward in a single task, training from scratch. A “Classical RL” task might be learning to navigate a single maze as fast as possible. The learner can completely overfit to the maze, since its goal is to solve this one maze. In contrast, Meta RL is the paradigm of developing a system that can quickly learn new tasks. A “Meta RL” task could be learning to navigate a random maze $K$ times as fast as possible. In this task, the learner cannot overfit to a single maze. Instead, the agent must find a good exploration strategy for the first episode on a new maze, and it should remember the exit after the first episode.
This Meta RL framework can actually just be thought of as a special case of reinforcement learning. A Meta RL episode now consists of $K$ classical RL episodes, with each “Meta RL” episode starting with a new random task. Then, the goal of the agent can naturally be formulated as maximizing the cumulative reward for each random task over $K$ classical RL episodes.
This idea is called $RL^2$, or Fast Reinforcement Learning via Slow Reinforcement Learning. In $RL^2$, a recurrent neural network (RNN) is used to learn how to solve a new random task. The “Fast RL” algorithm is the algorithm learned by the LSTM network to solve a maze, and the “slow RL” algorithm is the algorithm used to train the LSTM network for random mazes.
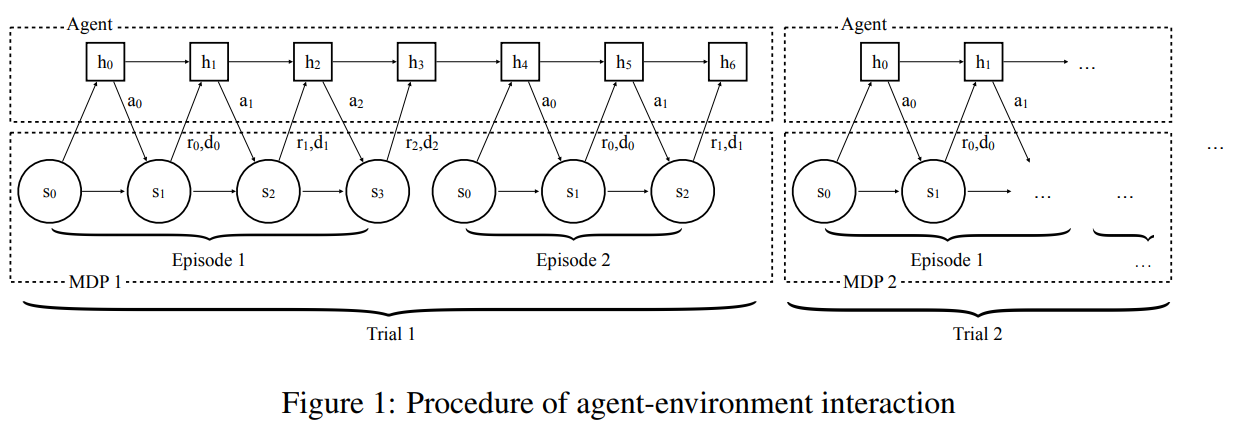
In the maze example, the $RL^2$ agent can successfully remember the experience of the first episode and can walk straight to the goal on the next episode.
At a larger scale, meta RL has been used to train a object manipulation to a robot hand. Learning in-hand manipulation is by itself a complex task with high degrees of freedom (DOF). Furthermore, the physical robotic arm is costly to run and susceptible to breakages, making it difficult to gather sufficient experience for successful learning. Dactyl was trained successfully despite such challenges through a meta learning approach.

To overcome the challenge, instead of training on the real world, the agent was trained in simulations. The simulation had lots of parameters that could be randomized, including frictions, robot dimensions, and visual appearances. The LSTM was trained from these heavily randomized simulations, where every episode for the LSTM policy occured in a randomly sampled “world.” Thus, for the LSTM to maximize its cumulative reward, it must learn to quickly adapt to the parameter settings of the “new world.” Then, the real world will simply be another “new world,” and the policy will hopefully master the dynamics of the real world quickly.
Although these meta RL approaches seem very promising, they still have crucial limitations. Both the maze example and the in-hand manipulation example assume infinite data, where the agent can randomly sample tasks. Furthermore, both examples rely on the “real task” being covered by the distribution of the training task. If the maze or the parameters of the real world is not covered by the distribution of training tasks, the performance will heavily drop. In this sense, this approach does not emphasize generalization to “new” tasks, but just learning on a broad but finite training set. Also, in both examples, the learning is done through RNN state updates without updating the weights of the neural network. Although it sufficed for these two examples, it might not be powerful enough to handle more complex systems, since it learns very few things about the environment from short hoirzons.
Gym Retro
To address these shortcomings, we can reformulate the problem and explicitly split the training tasks and the test tasks. Gym Retro is a test suite of over 1000 games created for this new problem formulation. Unlike previous RL efforts where the focus was achieving superhuman results on individual games, the focus of Gym Retro is solving previously unseen game as fast as a human given prior experience with similar games.
The Retro Contest earlier this year addressed a simplified, easier version of the challenge. Instead of creating an agent that can solve previously unseen games quickly, the goal was to create an agent that can solve previously unseen levels of Sonic the Hedgehog quickly. In this contest, the agents could train on the training levels as much as possible, but the agent could only train for a million steps (about 18 hours) on the hidden test levels. State-of-the-art methods such as Rainbow and PPO had subhuman performance. Joint PPO, a technique of training the agent in training levels and finetuning it in test levels, performed better, but still had a large performance gap from humans.
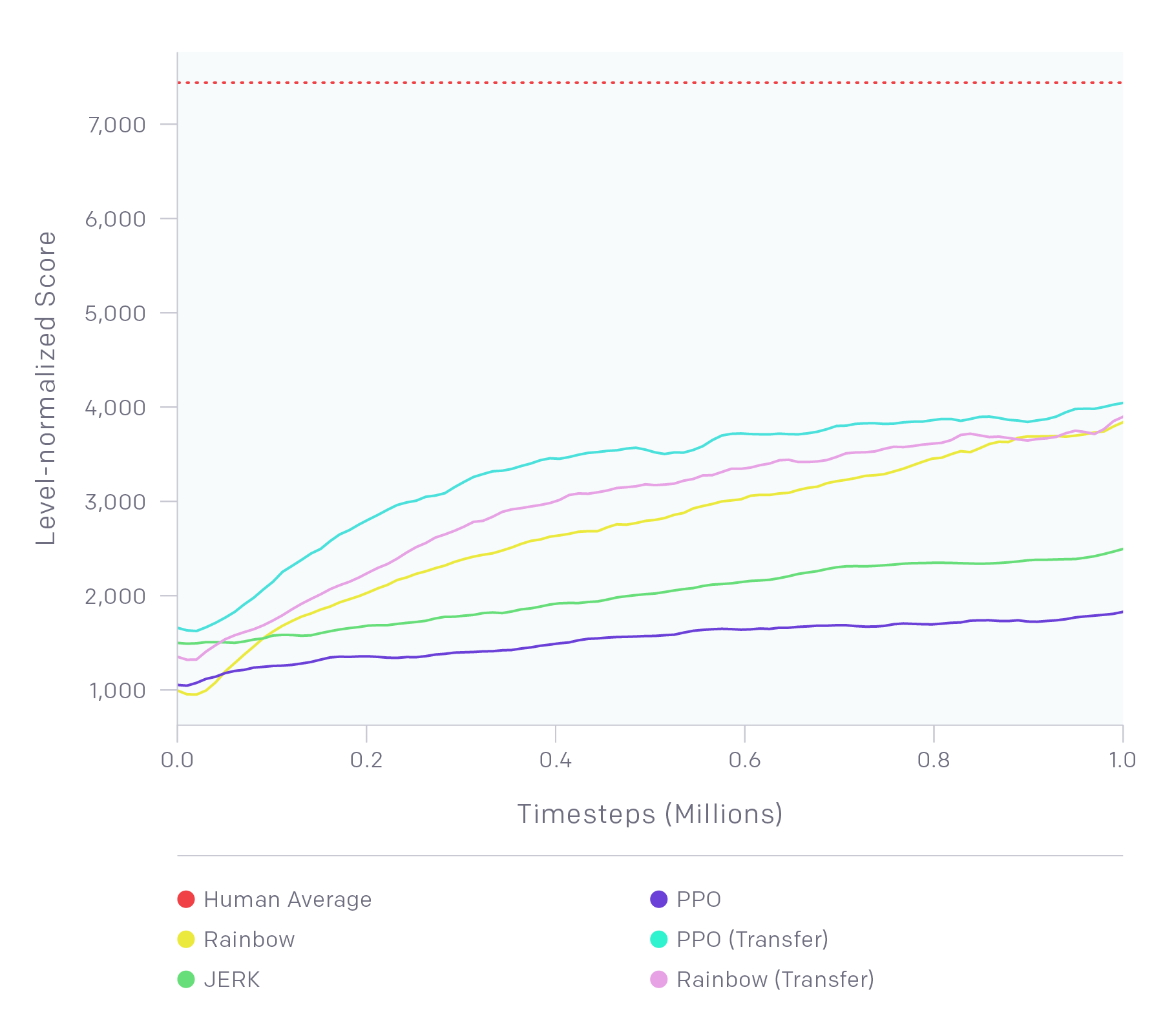
The top agents showed some interesting results. Some levels were solved in just 60 minutes of training (in wall-clock time).
Visualizing the solutions of the top 3 agents was also insightful. Red dots show earlier episodes on the test level, and the blue dots show later episodes.
Future Work
A big challenge for Gym Retro is on successful transfer between games rather than just levels. Some promising techniques include better exploration techniques, unsupervised learning, or hierarchy. The RNN-based meta learning could also be improved to deal with long-time horizons.
It was great seeing so many participants of the Retro Contest coming up with creative solutions. We are excited to run more contests like the Retro Contest.