RL Weekly
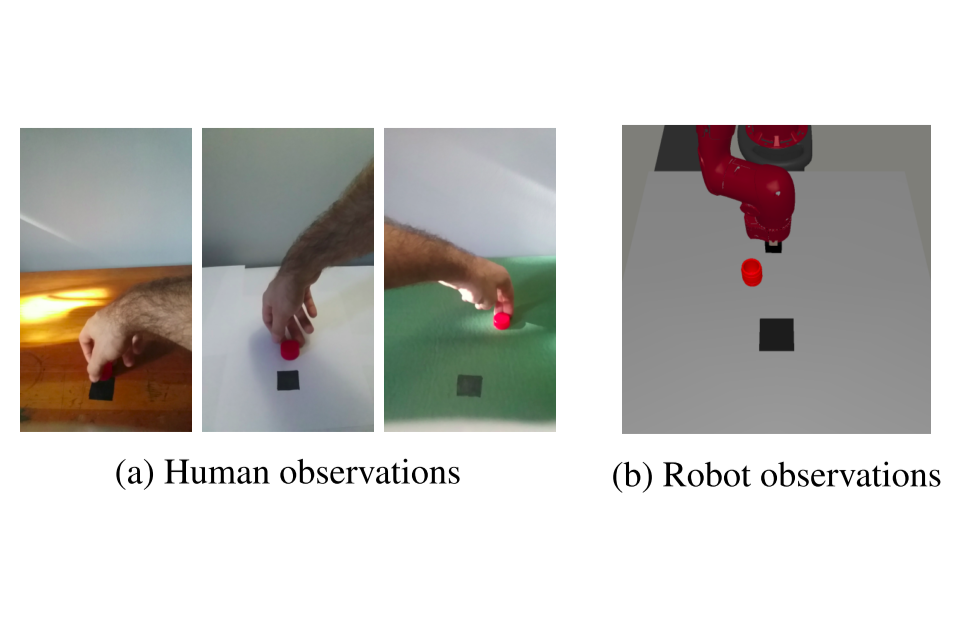
RL Weekly 44: Reinforcement Learning with Videos and Automatic Data Augmentation
In this issue, we look at using human demonstrations to help robot learn and automatically selecting data augmentation methods for RL.
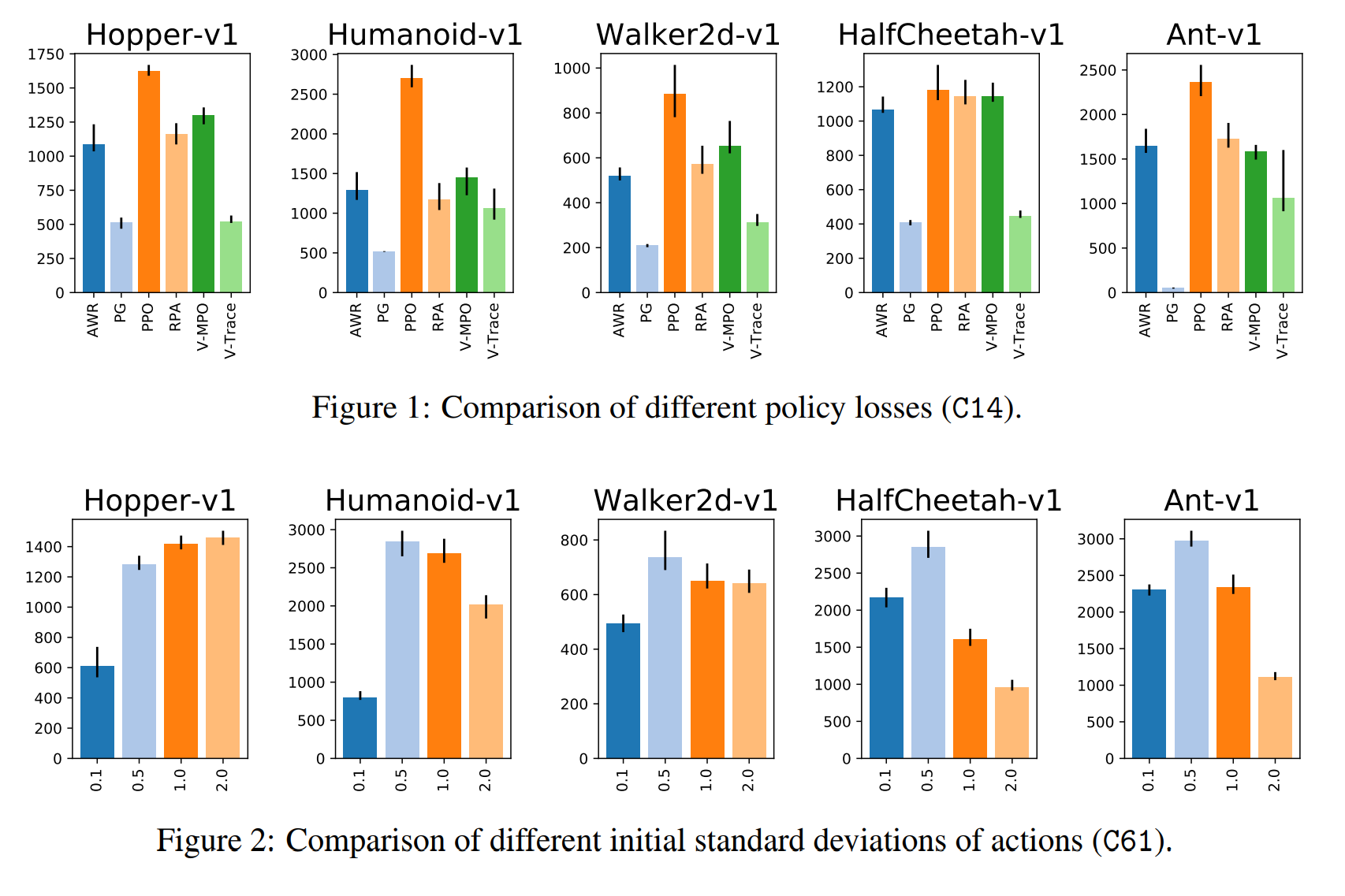
RL Weekly 43: Revisiting Experience Replay, On-Policy Methods, and Rainbow
In this issue, we examine large scale experiments that illuminate the design decisions of various components of reinforcement learning.
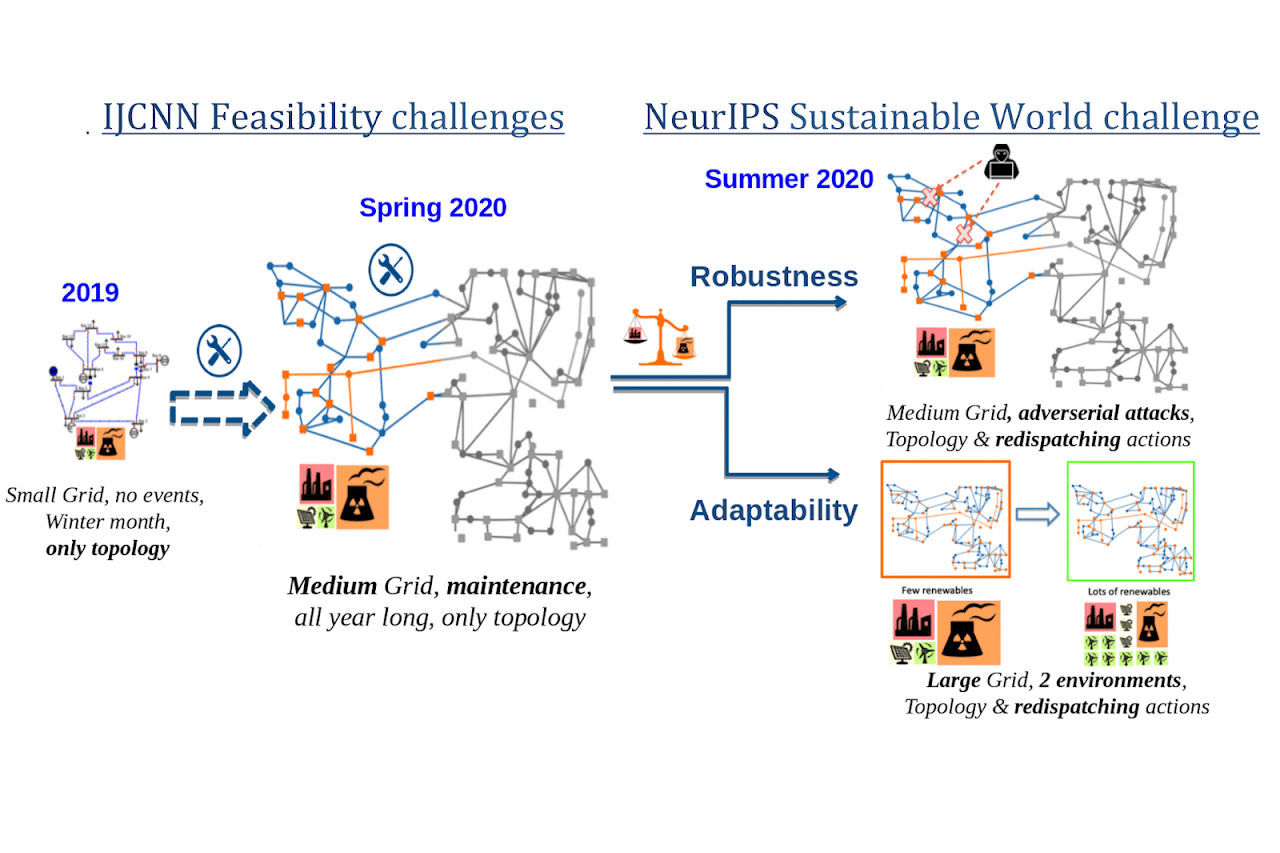
RL Weekly 42: Special Issue on NeurIPS 2020 Competitions
In this special issue, we look at the four RL competitions that is a part of NeurIPS 2020.
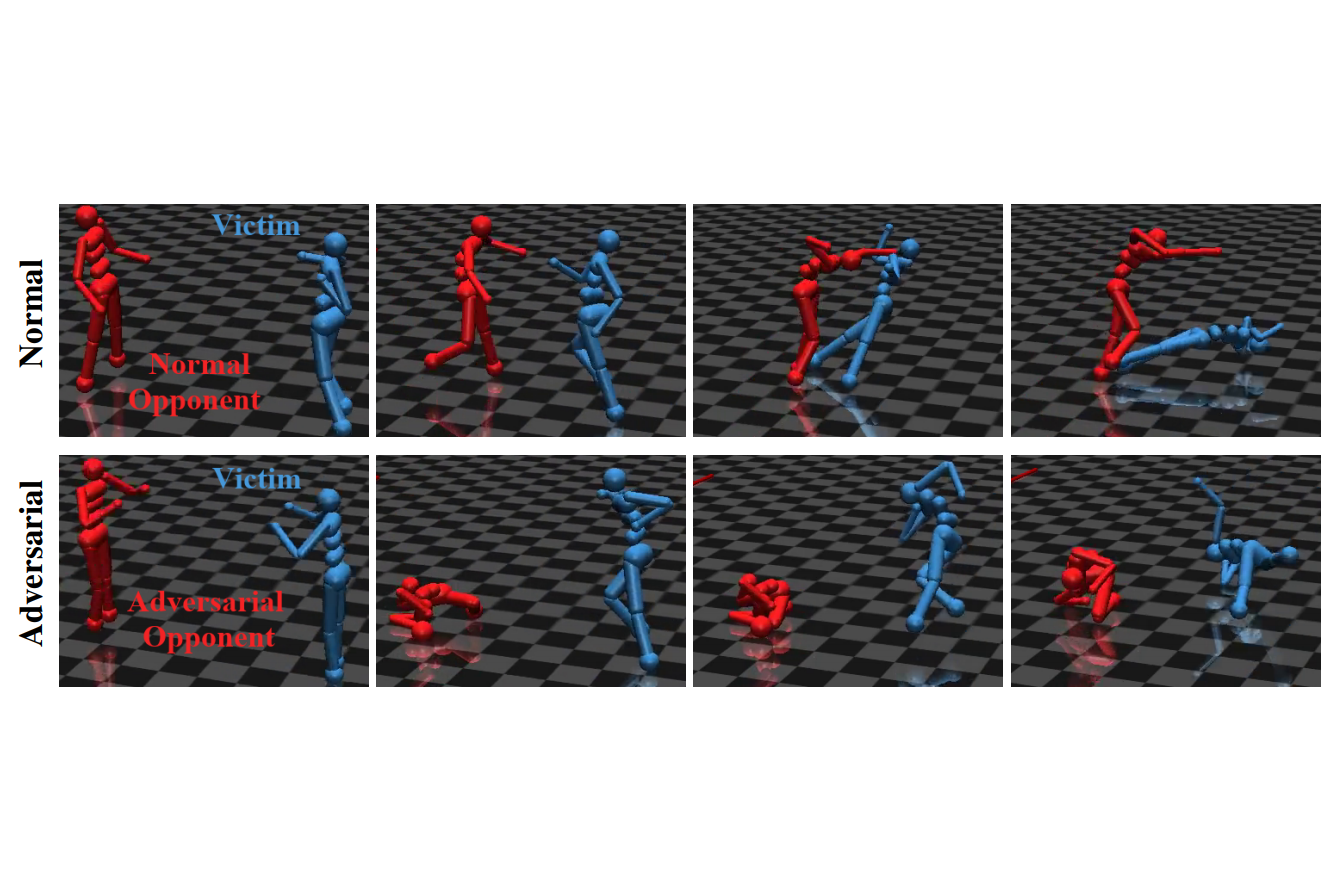
RL Weekly 41: Adversarial Policies, Image Augmentation, and Self-Supervised Exploration with World Models
In this issue, we look at adversarial policy learning, image augmentation in RL, and self-supervised exploration through world models.
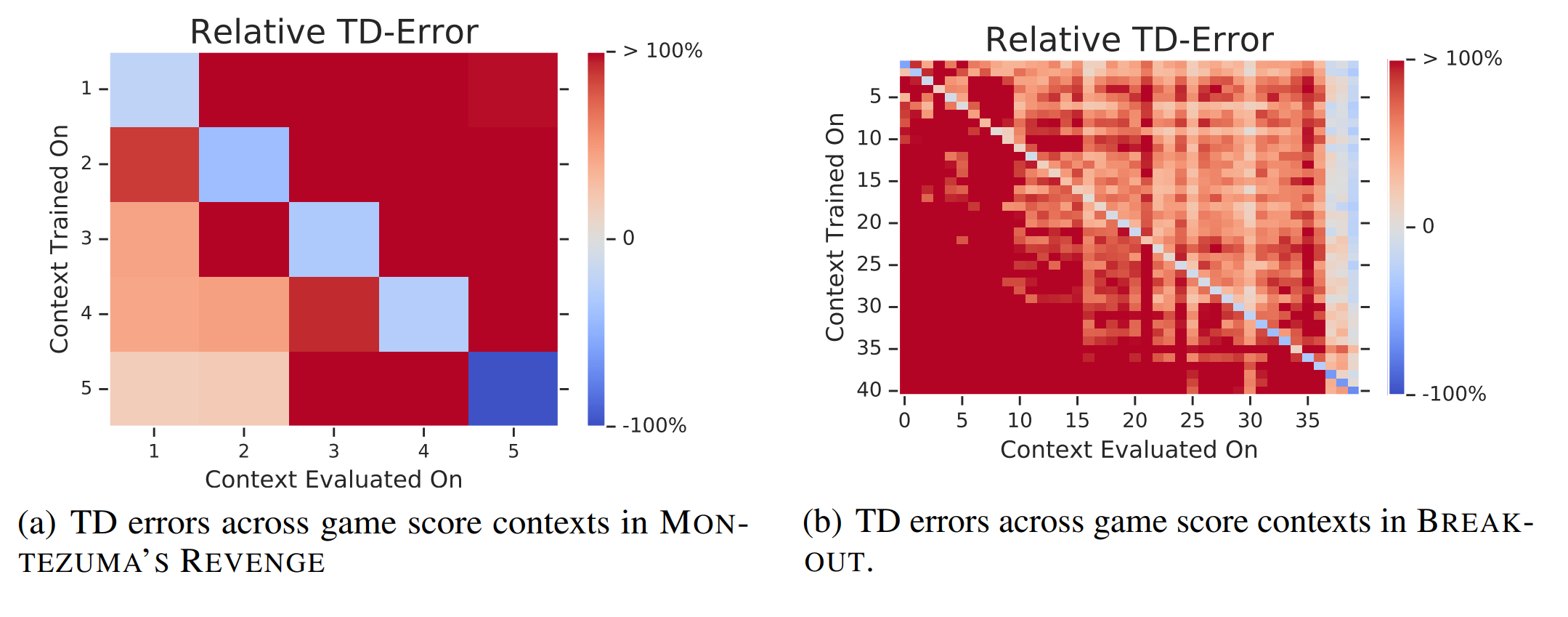
RL Weekly 40: Catastrophic Interference and Policy Evaluation Networks
In this issue, we look at two papers combating catastrophic interference. Memento combats interference by training two independent agents where the second agent takes off...
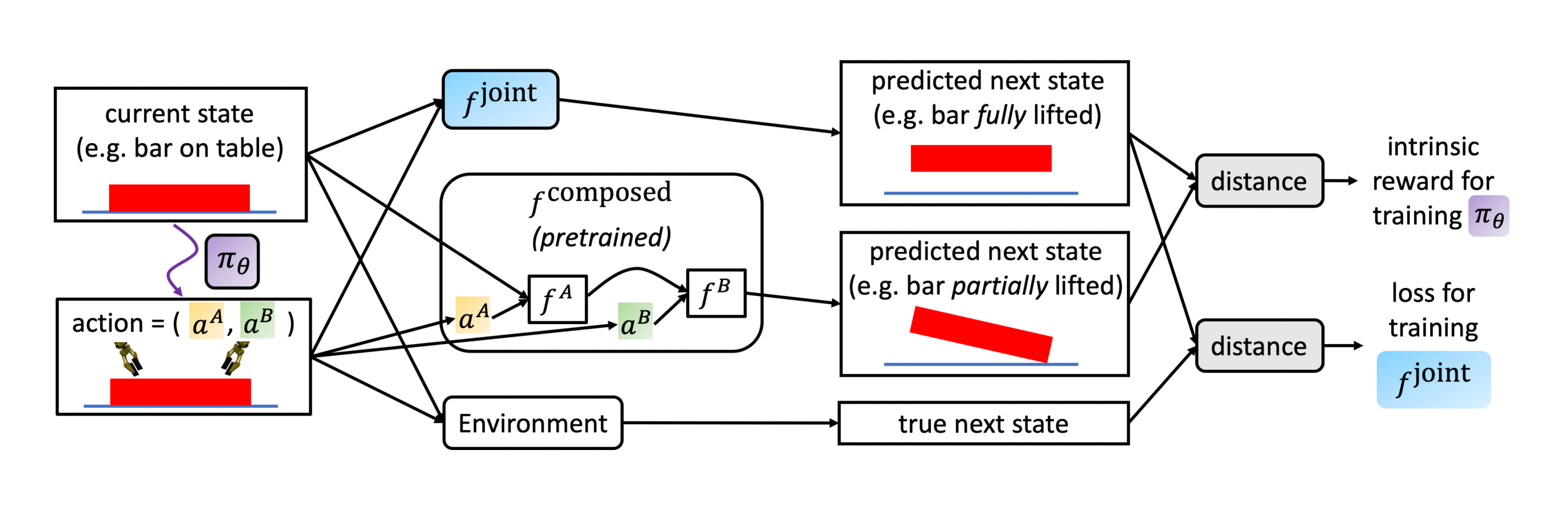
RL Weekly 39: Intrinsic Motivation for Cooperation and Amortized Q-Learning
In this issue, we look at using intrinsic rewards to encourage cooperation in two-agent MDP. We also look at replacing maximization in Q-learning over all...

RL Weekly 38: Clipped objective is not why PPO works, and the Trap of Saliency maps
In this issue, we look at the effect of PPO's code-level optimizations and the study of saliency maps in RL.

RL Weekly 37: Observational Overfitting, Hindsight Credit Assignment, and Procedurally Generated Environment Suite
In this issue, we look at Google and MIT's study on the observational overfitting phenomenon and how overparametrization helps generalization, a new family of algorithms...

RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
In this issue, we look at MuZero, DeepMind's new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves...
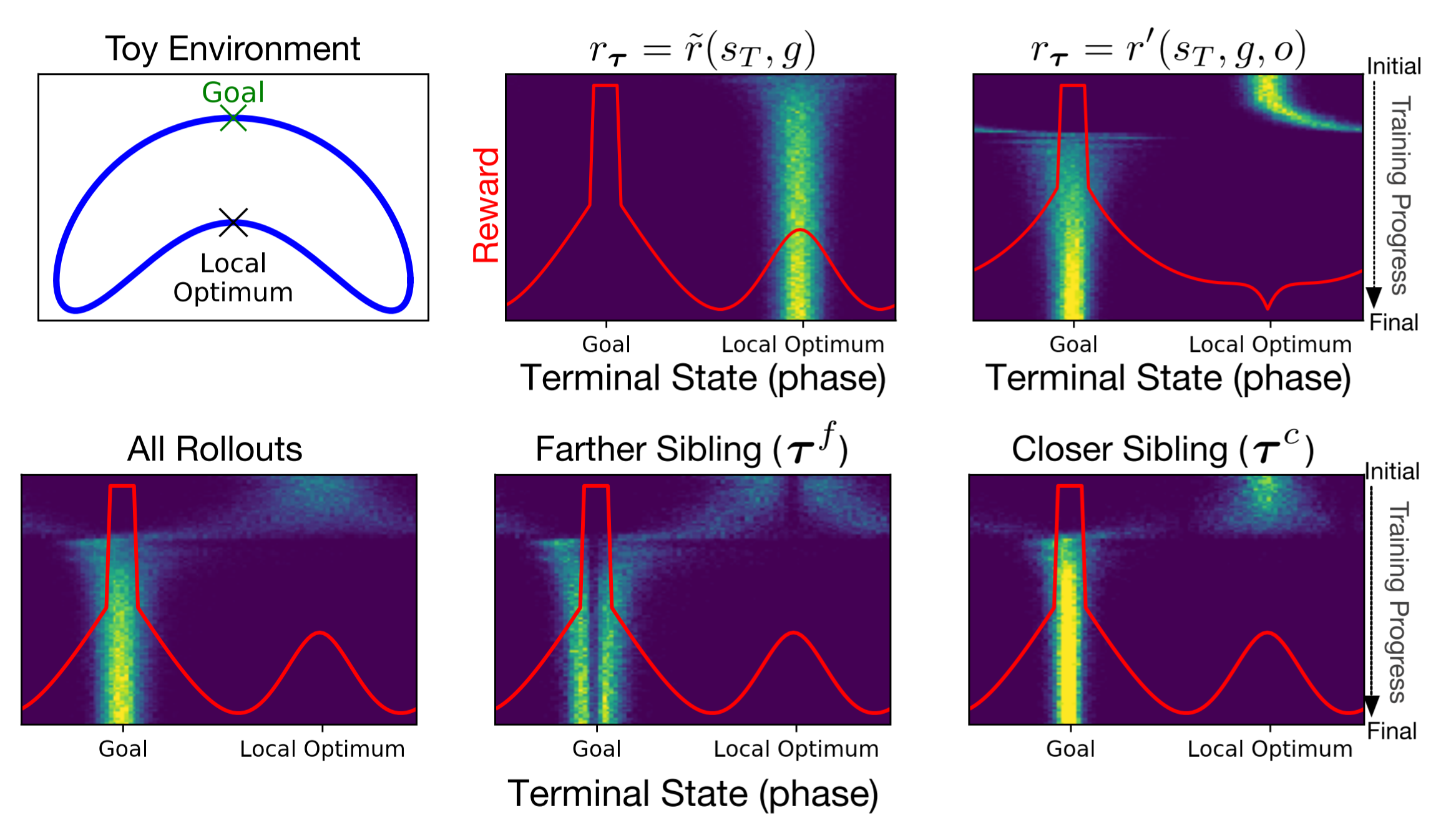
RL Weekly 35: Escaping Local Optimas in Distance-based Rewards and Choosing the Best Teacher
In this issue, we look at an algorithm that use sibling trajectories to escape local optimas in distance-based shaped rewards, and an algorithm that dynamically...

RL Weekly 34: Dexterous Manipulation of the Rubik's Cube and Human-Agent Collaboration in Overcooked
In this issue, we look at a robot hand manipulating and "solving" the Rubik's Cube. We also look at comparative performances of human-agnostic and human-aware...
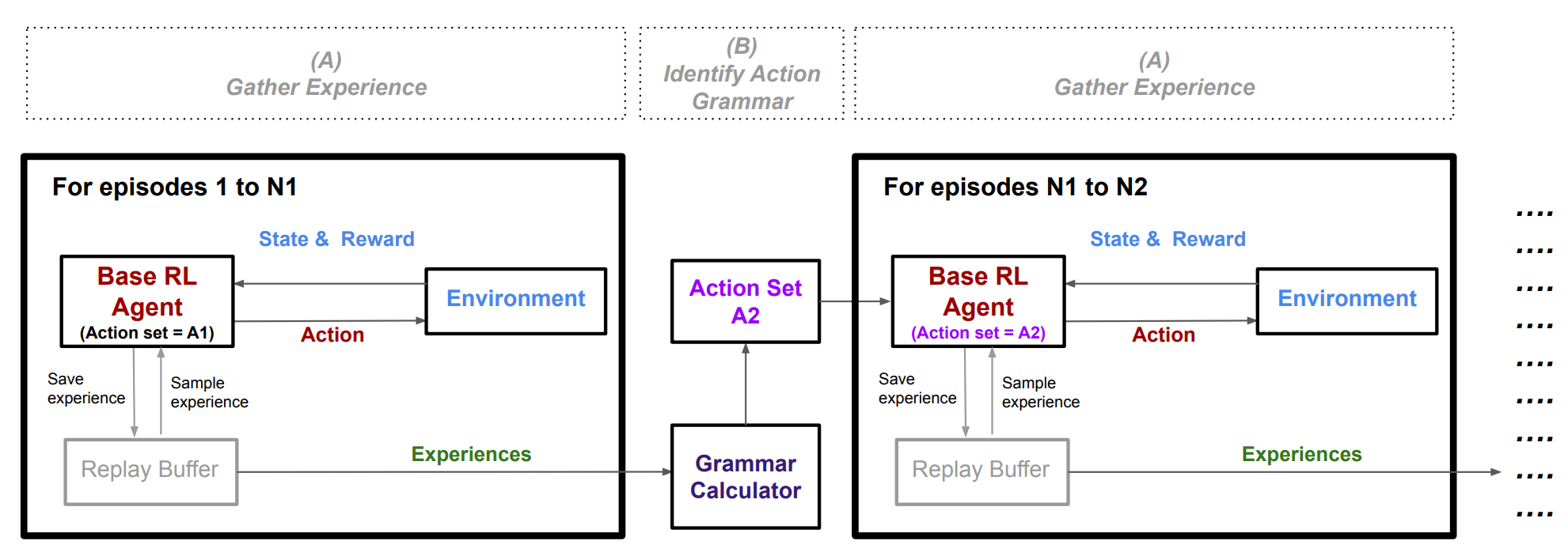
RL Weekly 33: Action Grammar, the Squashing Exploration Problem, and Task-relevant GAIL
In this issue, we look at Action Grammar RL, a hierarchical RL framework that adds new macro-actions, improving performance of DDQN and SAC in Atari...
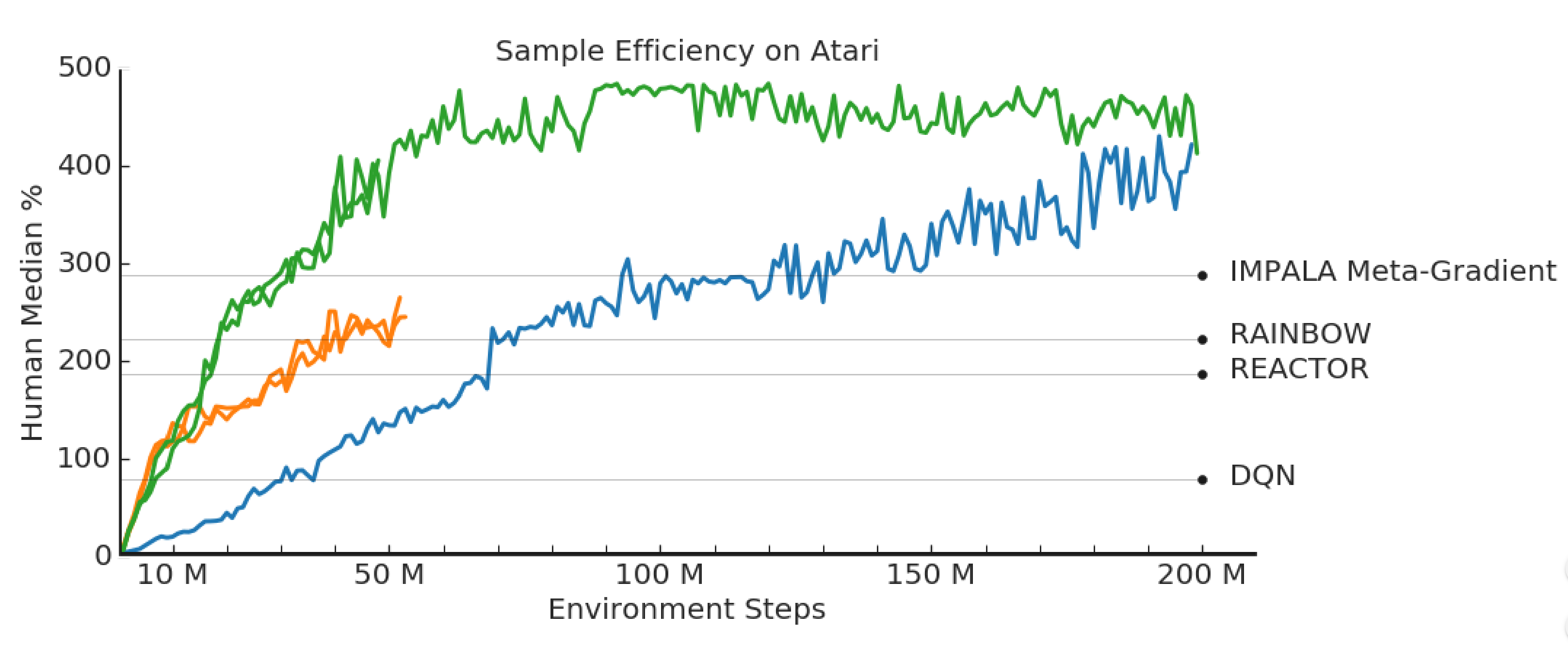
RL Weekly 32: New SotA Sample Efficiency on Atari and an Analysis of the Benefits of Hierarchical RL
In this issue, we look at LASER, DeepMind's improvement to V-trace that achieves state-of-the-art sample efficiency in Atari environments. We also look at Google AI...

RL Weekly 31: How Agents Play Hide and Seek, Attraction-Repulsion Actor Critic, and Efficient Learning from Demonstrations
In this issue, we look at OpenAI's work on multi-agent hide and seek and the behaviors that emerge. We also look at Mila's population-based exploration...
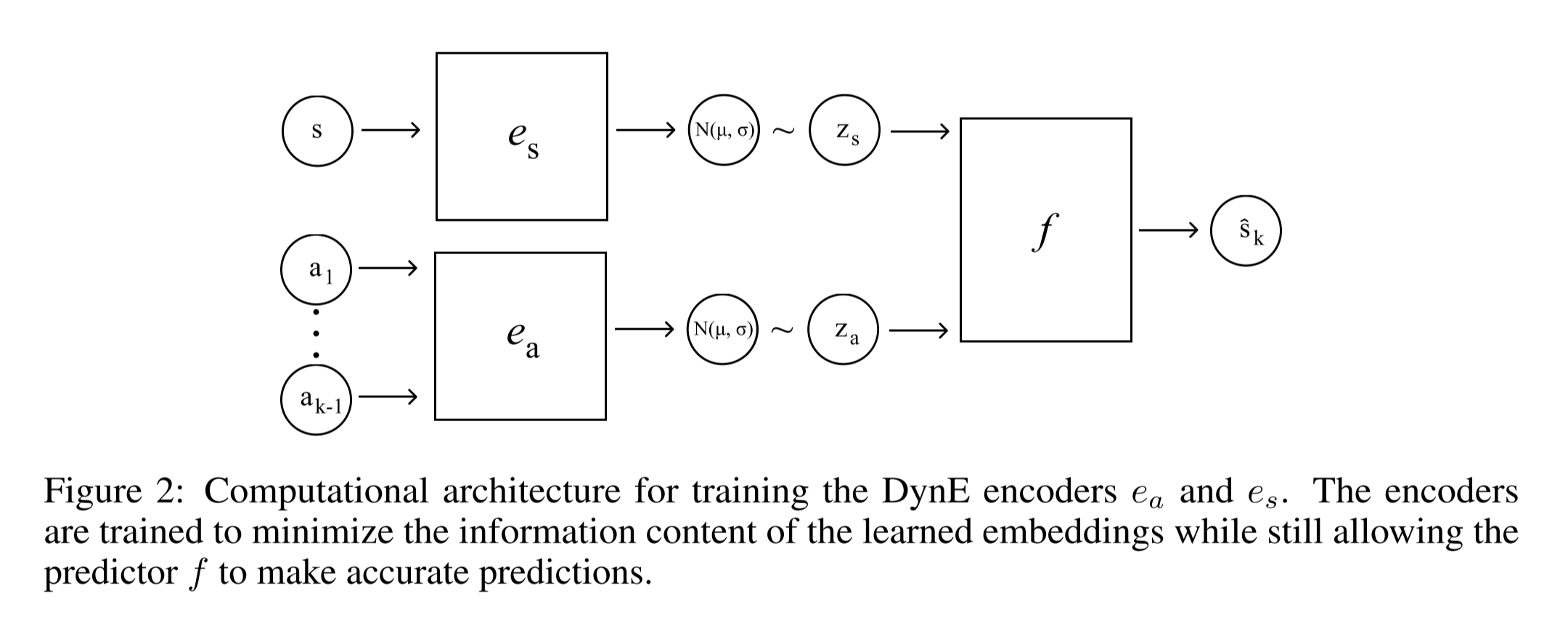
RL Weekly 30: Learning State and Action Embeddings, a New Framework for RL in Games, and an Interactive Variant of Question Answering
In this issue, we look at a representation learning method to train state and action embeddings paired with TD3. We also look at a new...
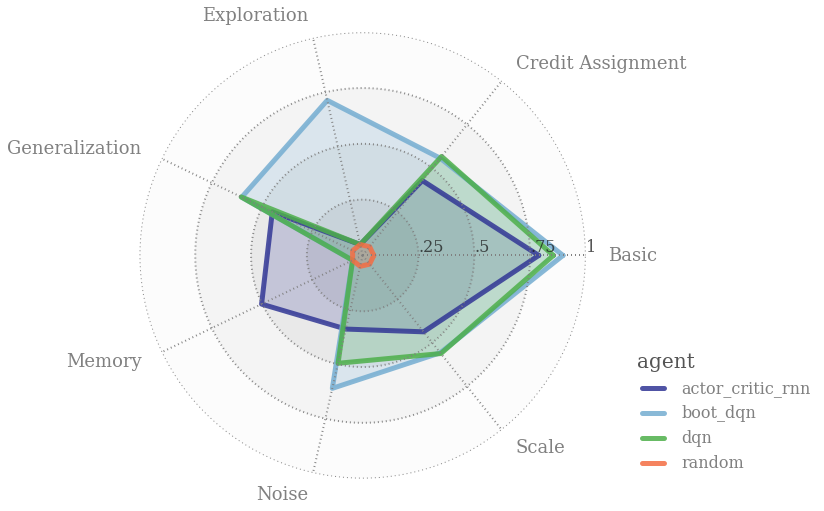
RL Weekly 29: The Behaviors and Superstitions of RL, and How Deep RL Compares with the Best Humans in Atari
In this issue, we look at reinforcement learning from a wider perspective. We look at new environments and experiments that are designed to test and...

RL Weekly 28: Free-Lunch Saliency and Hierarchical RL with Behavior Cloning
This week, we first look at Free-Lunch Saliency, a built-in interpretability module that does not deteriorate performance. Then, we look at HRL-BC, a combination of...
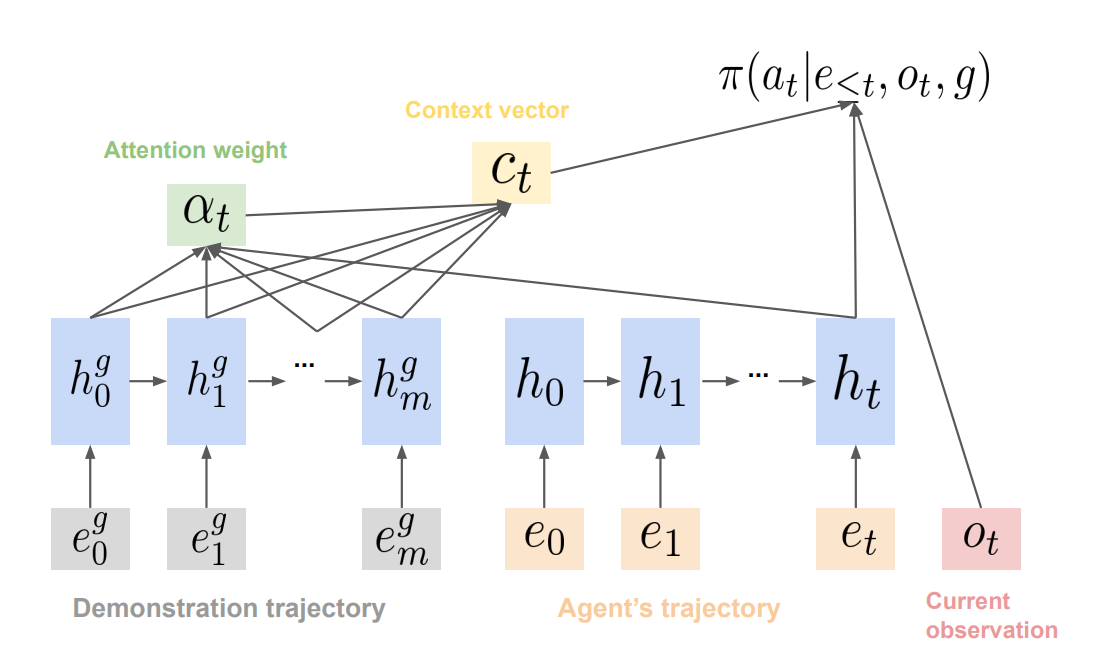
RL Weekly 27: Diverse Trajectory-conditioned Self Imitation Learning and Environment Probing Interaction Policies
This week, we look at a self imitation learning method that imitates diverse past experience for better exploration. We also summarize an environment probing policy...
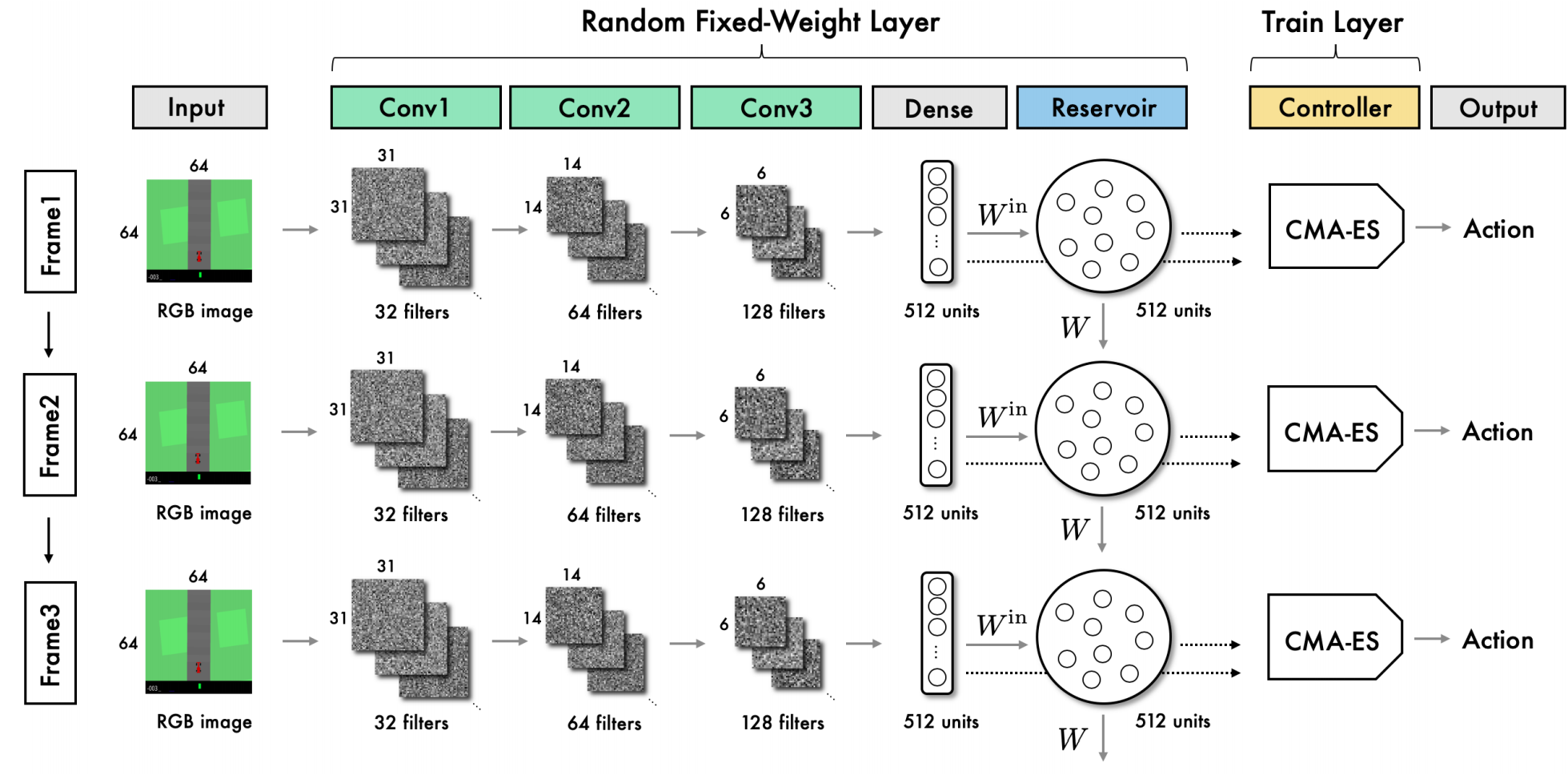
RL Weekly 26: Transfer RL with Credit Assignment and Convolutional Reservoir Computing for World Models
This week, we summarize a new transfer learning method using the Transformer reward model, and a world model controller that does not require training the...
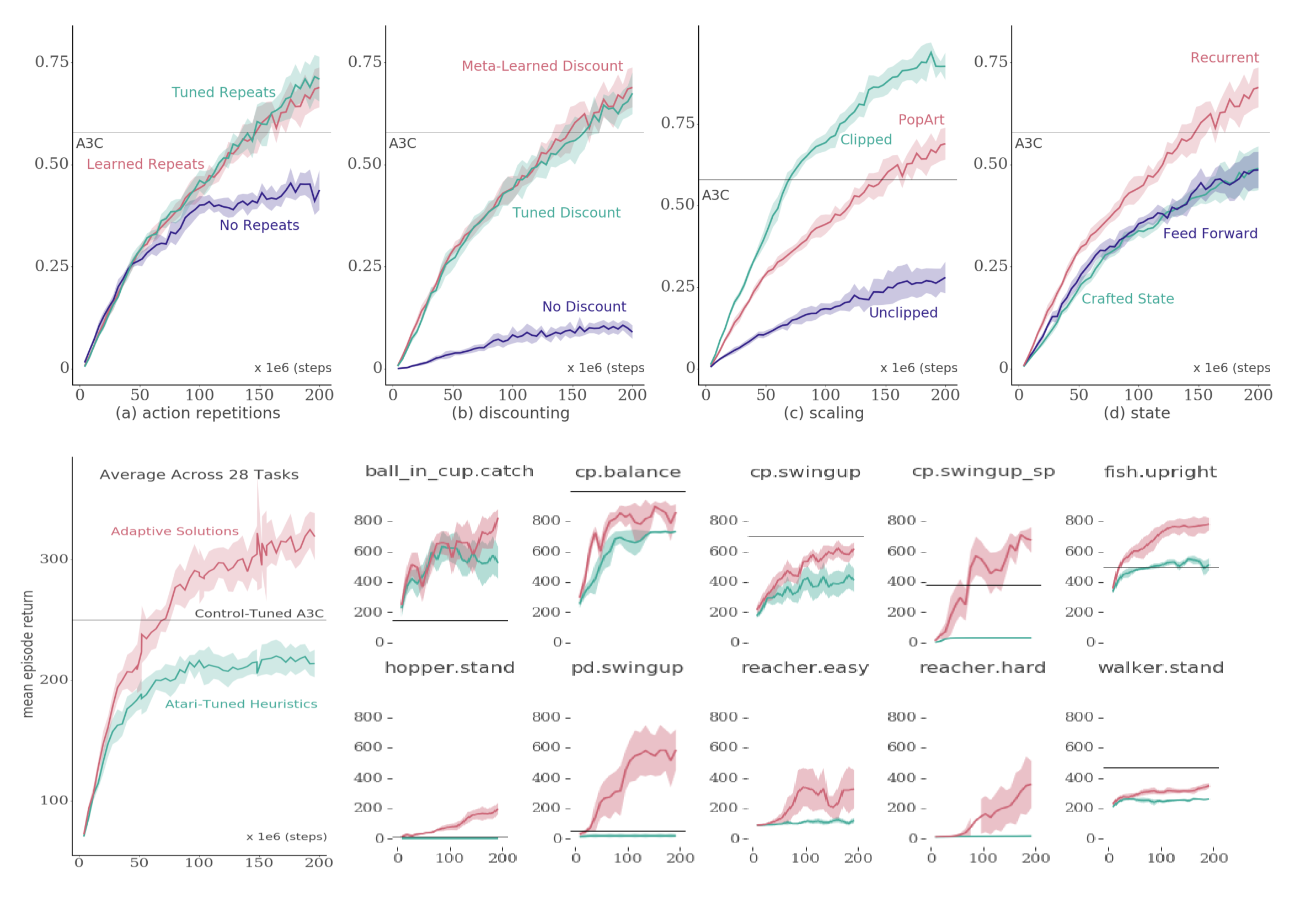
RL Weekly 25: Replacing Bias with Adaptive Methods, Batch Off-policy Learning, and Learning Shared Model for Multi-task RL
In this issue, we focus on replacing inductive bias with adaptive solutions (DeepMind), learning off-policy from expert experience (Google Brain), and learning a shared model...
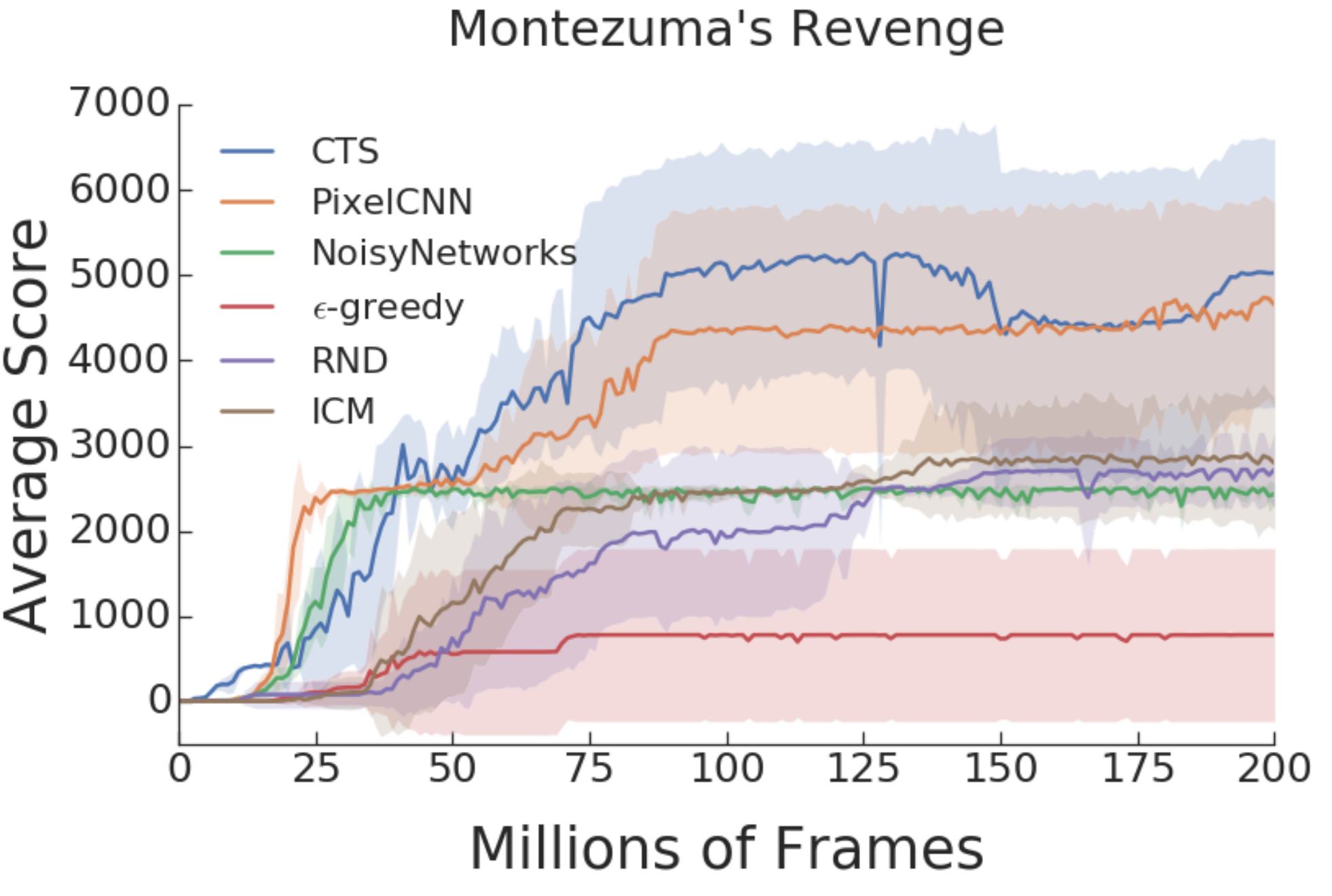
RL Weekly 24: Benchmarks for Model-based RL and Bonus-based Exploration Methods
This week, we summarize two benchmark papers. The first paper benchmarks 11 model-based RL algorithms in 18 continuous control environments, and the second paper benchmarks...
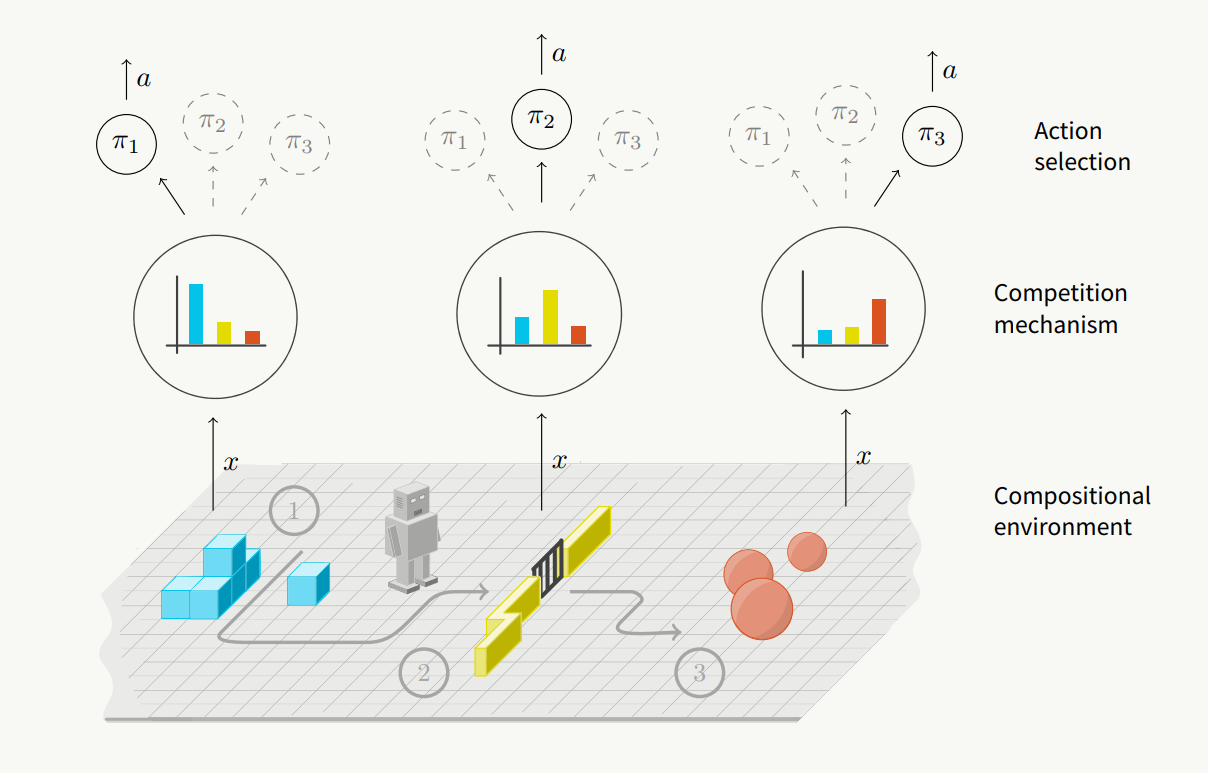
RL Weekly 23: Decentralized Hierarchical RL, Deep Conservative Policy Iteration, and Optimistic PPO
This week, we first introduce a ensemble of primitives without a high-level meta-policy that can make decentralized decisions. We then look at an deep learning...
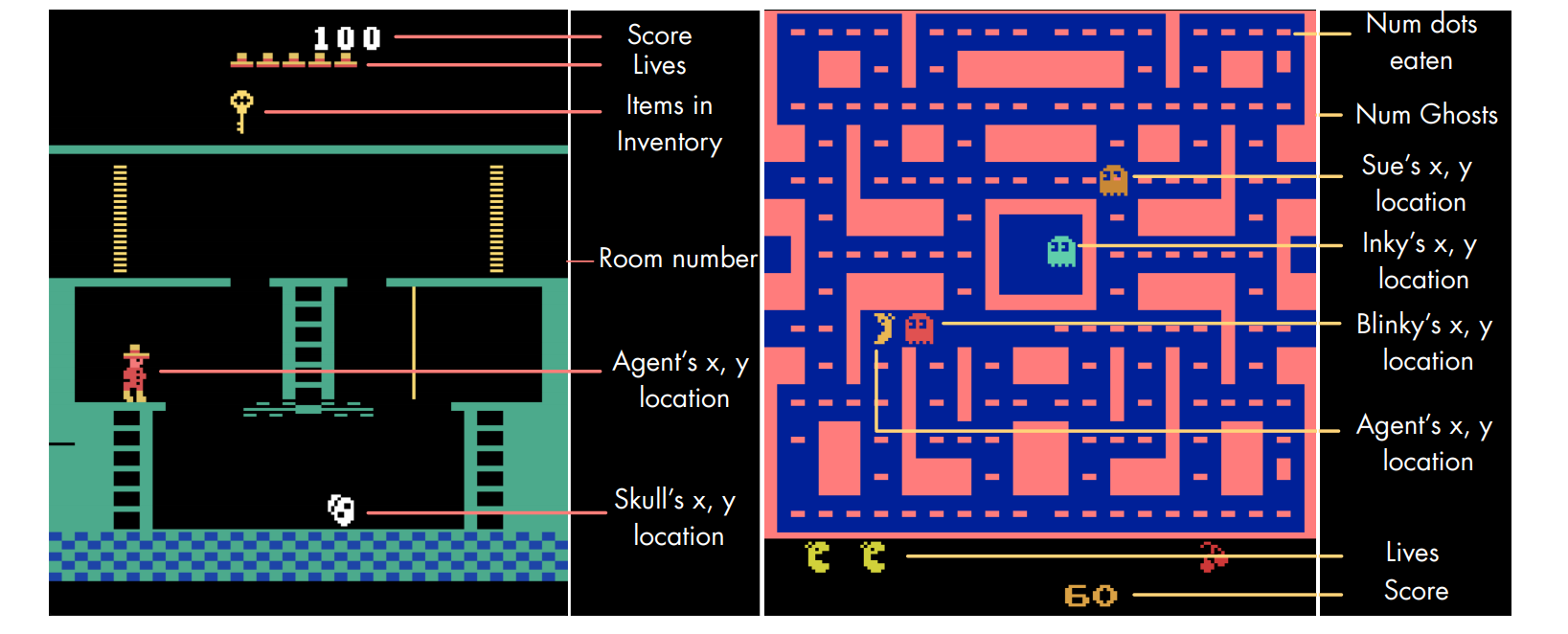
RL Weekly 22: Unsupervised Learning for Atari, Model-based Policy Optimization, and Adaptive-TD
This week, we first look at ST-DIM, an unsupervised state representation learning method from MILA and Microsoft Research. We also check UC Berkeley's new policy...
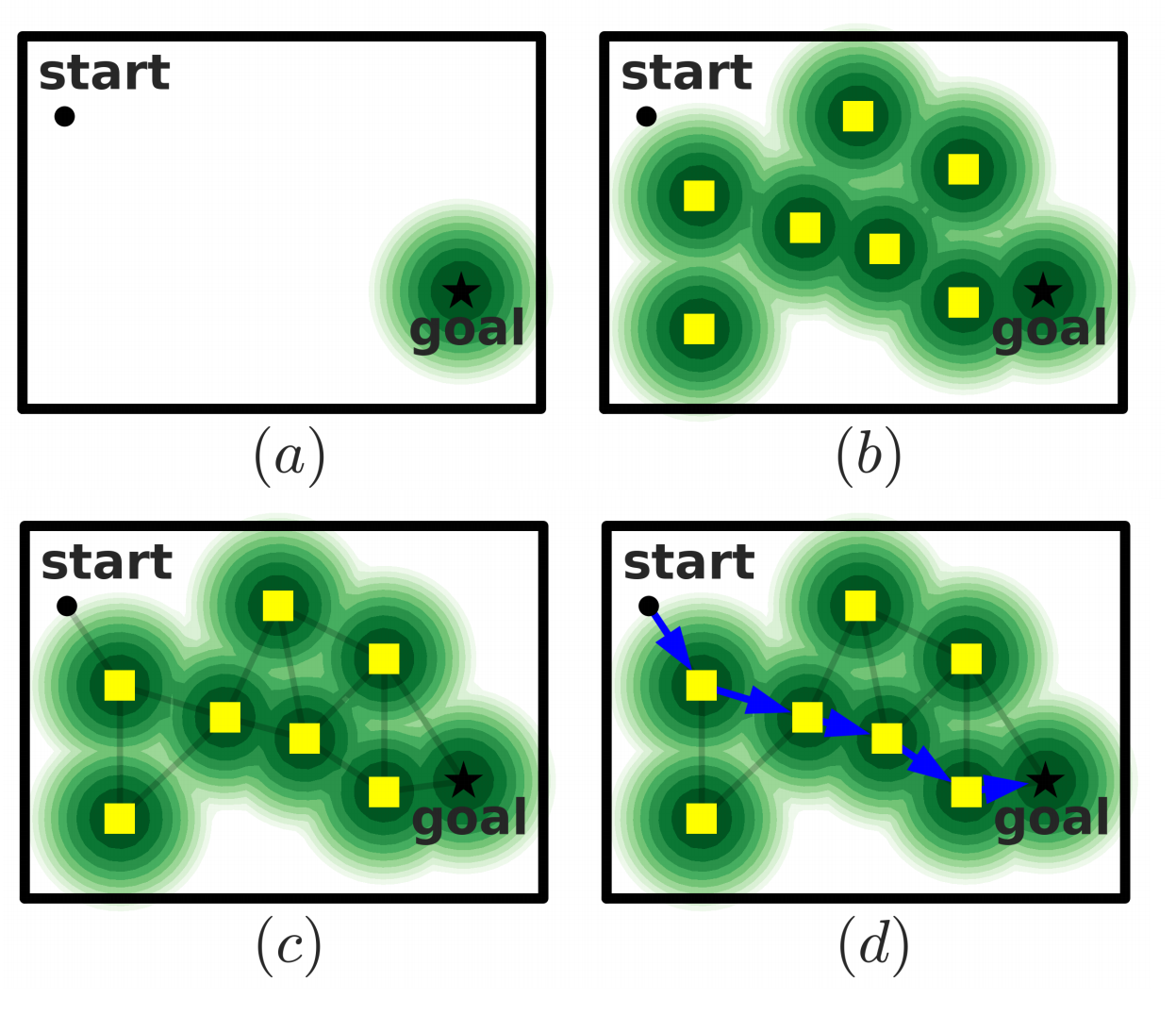
RL Weekly 21: The interplay between Experience Replay and Model-based RL
This week, we introduce three papers on replay-based RL and model-based RL. The first paper introduces SoRB, a way to combine experience replay and planning....
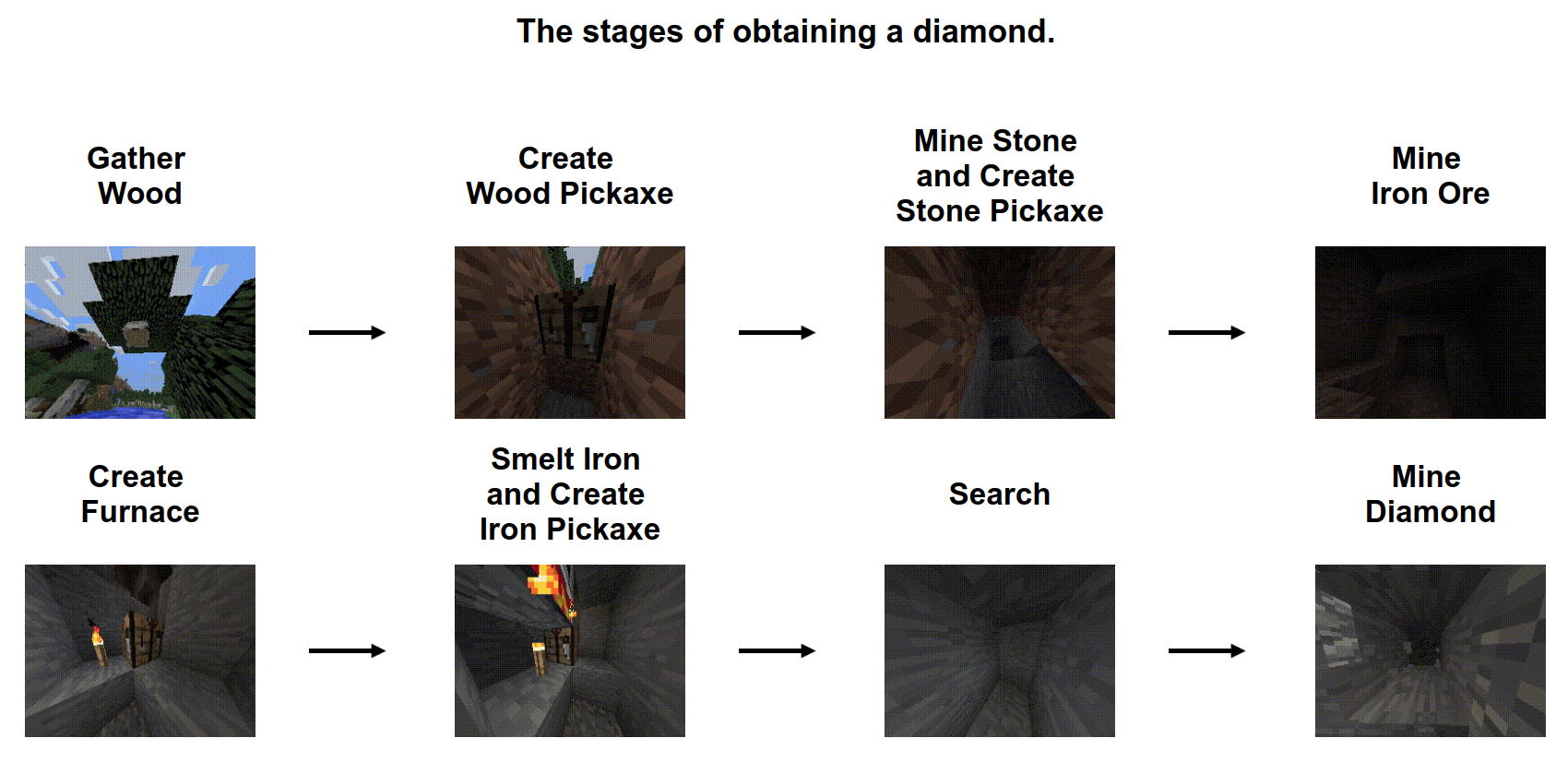
RL Weekly 20: Minecraft Competition, Off-policy Policy Evaluation via Classification, and Soft-attention Agent for Interpretability
This week, we introduce MineRL, a new RL competition using human priors to solve Minecraft. We also introduce OPE, a method of off-policy evaluation through...
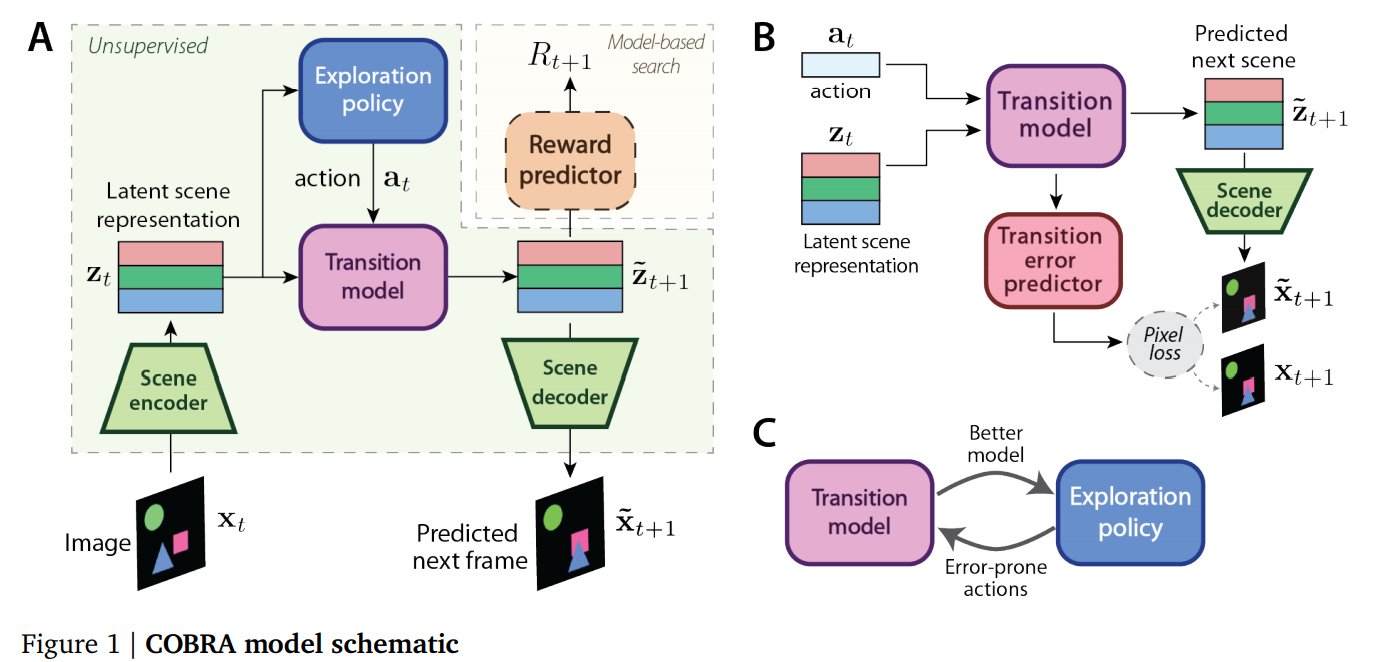
RL Weekly 19: Curious Object-Based Search Agent, Multiplicative Compositional Policies, and AutoRL
This week, we introduce combining unsupervised learning, exploration, and model-based RL; learning composable motor skills; and evolving rewards.
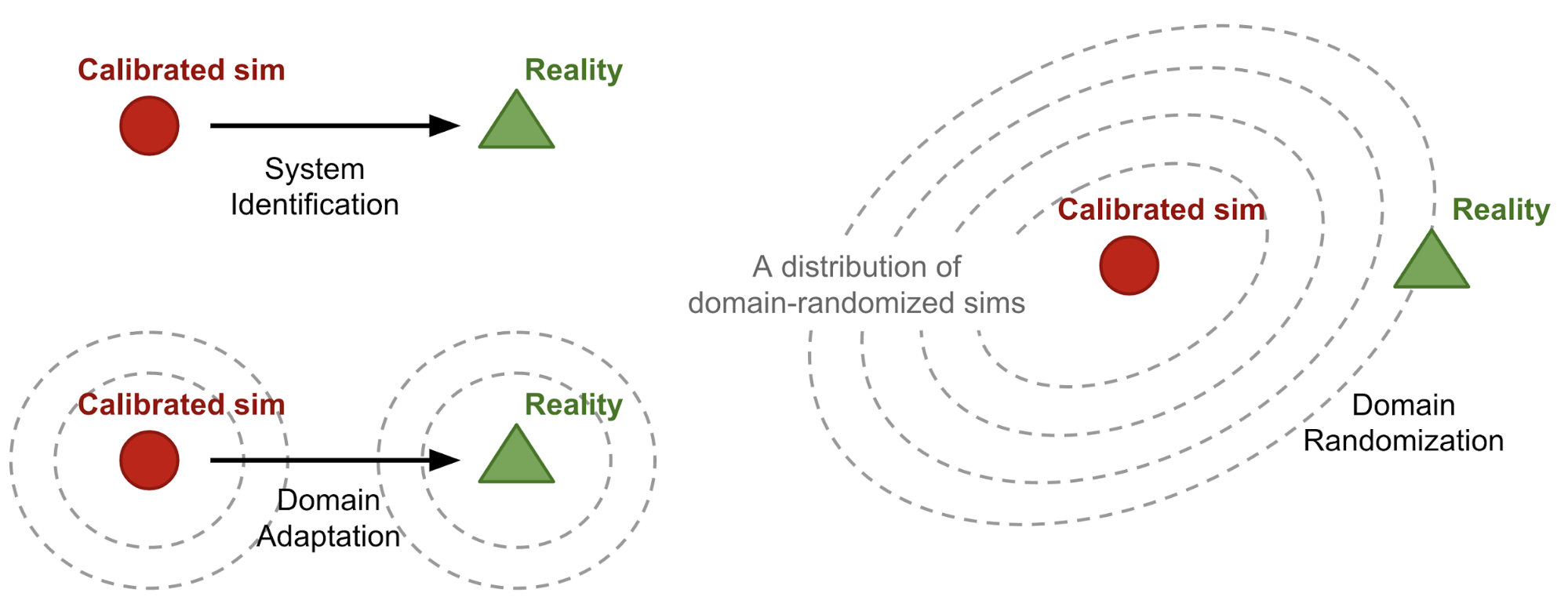
RL Weekly 18: Survey of Domain Randomization Techniques for Sim-to-Real Transfer, and Evaluating Deep RL with ToyBox
This week, we introduce a survey of Domain Randomization Techniques for Sim-to-Real Transfer and ToyBox, a suite of redesigned Atari Environments for experimental evaluation of...
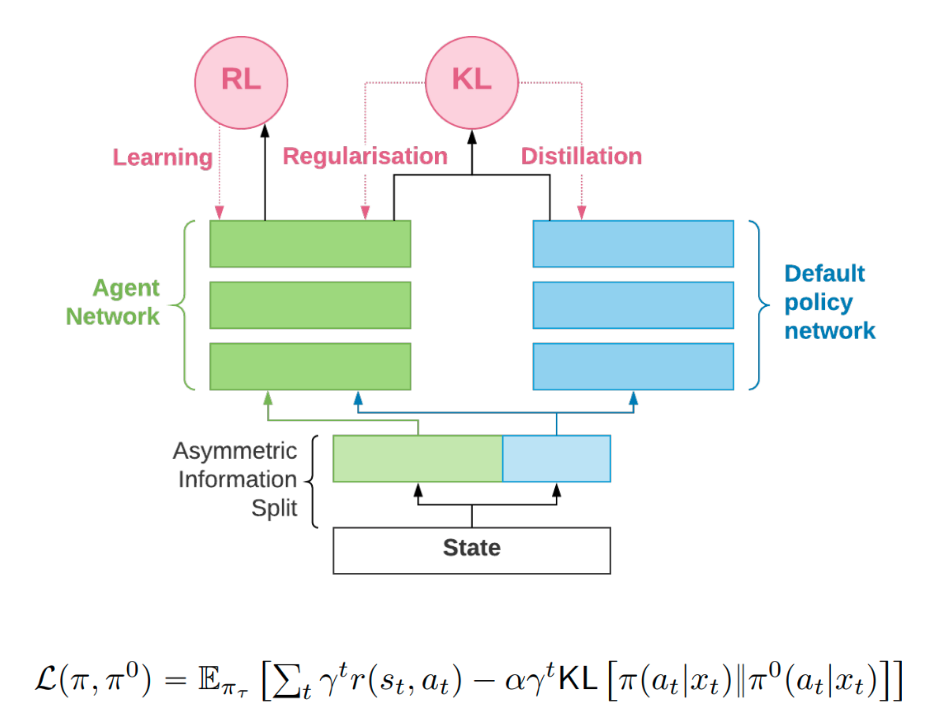
RL Weekly 17: Information Asymmetry in KL-regularized Objective, Real-world Challenges to RL, and Fast and Slow RL
In this issue, we summarize the use of information asymmetry in KL regularized objective to regularize the policy, the challenges of deploying deep RL into...
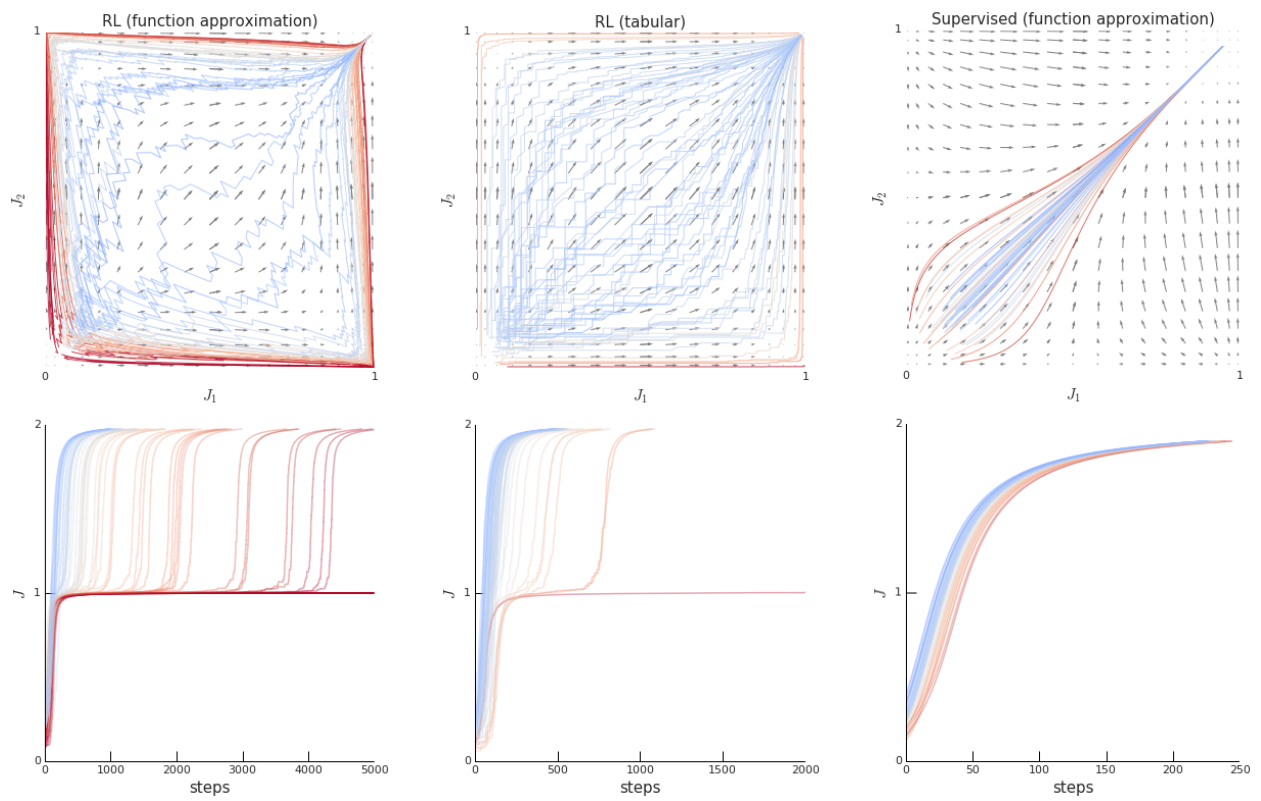
RL Weekly 16: Why Performance Plateaus May Occur, and Compressing DQNs
In this issue, we introduce 'ray interference,' a possible cause of performance plateaus in deep reinforcement learning conjectured by Google DeepMind. We also introduce a...
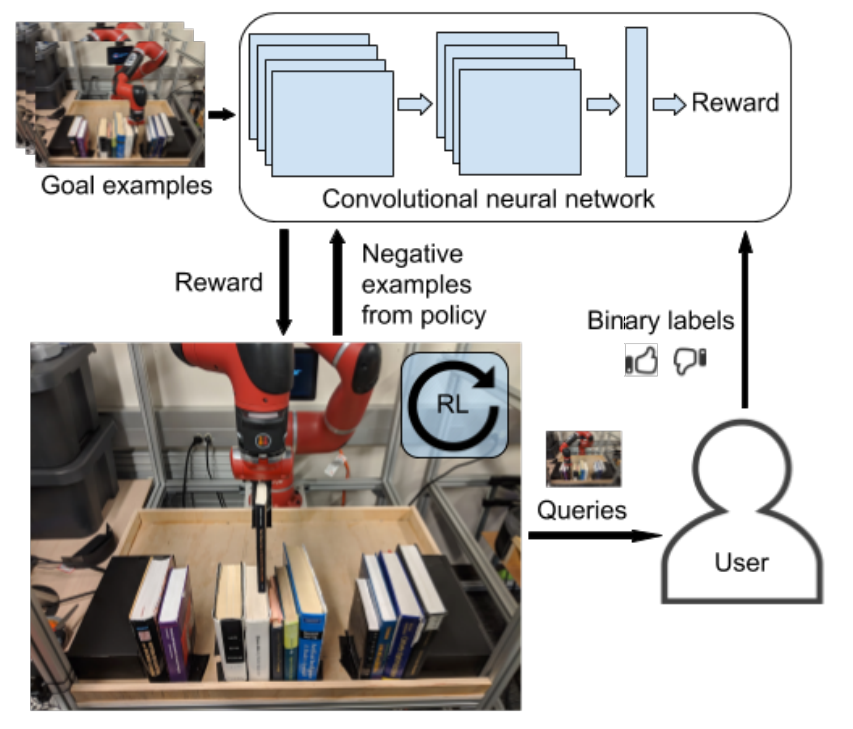
RL Weekly 15: Learning without Rewards: from Active Queries or Suboptimal Demonstrations
In this issue, we introduce VICE-RAQ by UC Berkeley and T-REX by UT Austin and Preferred Networks. VICE-RAQ trains a classifier to infer rewards from...

RL Weekly 14: OpenAI Five and Berkeley Blue
In this week's issue, we summarize the Dota 2 match between OpenAI Five and OG eSports and introduce Blue, a new low-cost robot developed by...

RL Weekly 13: Learning to Toss, Learning to Paint, and How to Explain RL
In this week's issue, we summarize results from Princeton, Google, Columbia, and MIT on training a robot arm to throw objects. We also look at...
RL Weekly 12: Atari Demos with Human Gaze Labels, New SOTA in Meta-RL, and a Hierarchical Take on Intrinsic Rewards
This week, we look at a new demo dataset of Atari games that include trajectories and human gaze. We also look at PEARL, a new...
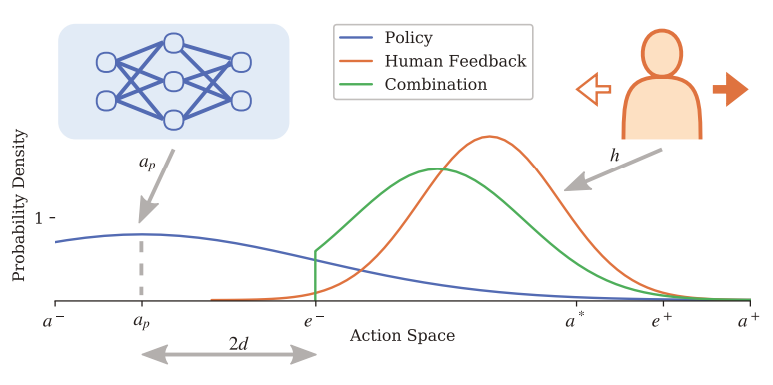
RL Weekly 11: The Bitter Lesson by Richard Sutton, the Promise of Hierarchical RL, and Exploration with Human Feedback
In this issue, we first look at a diary entry by Richard S. Sutton (DeepMind, UAlberta) on Compute versus Clever. Then, we look at a...

RL Weekly 10: Learning from Playing, Understanding Multi-agent Intelligence, and Navigating in Google Street View
In this issue, we look at Google Brain's algorithm of learning by playing, DeepMind's thoughts on multi-agent intelligence, and DeepMind's new navigation environment using Google...
RL Weekly 9: Sample-efficient Near-SOTA Model-based RL, Neural MMO, and Bottlenecks in Deep Q-Learning
In this issue, we look at SimPLe, a model-based RL algorithm that achieves near-state-of-the-art results on Arcade Learning Environments (ALE). We also look at Neural...
RL Weekly 8: World Discovery Models, MuJoCo Soccer Environment, and Deep Planning Network
In this issue, we introduce World Discovery Models and MuJoCo Soccer Environment from Google DeepMind, and PlaNet from Google.
RL Weekly 7: Obstacle Tower Challenge, Hanabi Learning Environment, and Spinning Up Workshop
This week, we introduce the Obstacle Tower Challenge, a new RL competition by Unity, Hanabi Learning Environment, a multi-agent environment by DeepMind, and Spinning Up...

RL Weekly 6: AlphaStar, Rectified Nash Response, and Causal Reasoning with Meta RL
This week, we look at AlphaStar, a Starcraft II AI, PSRO_rN, an evaluation algorithm encouraging diverse population of well-trained agents, and a novel Meta-RL approach...
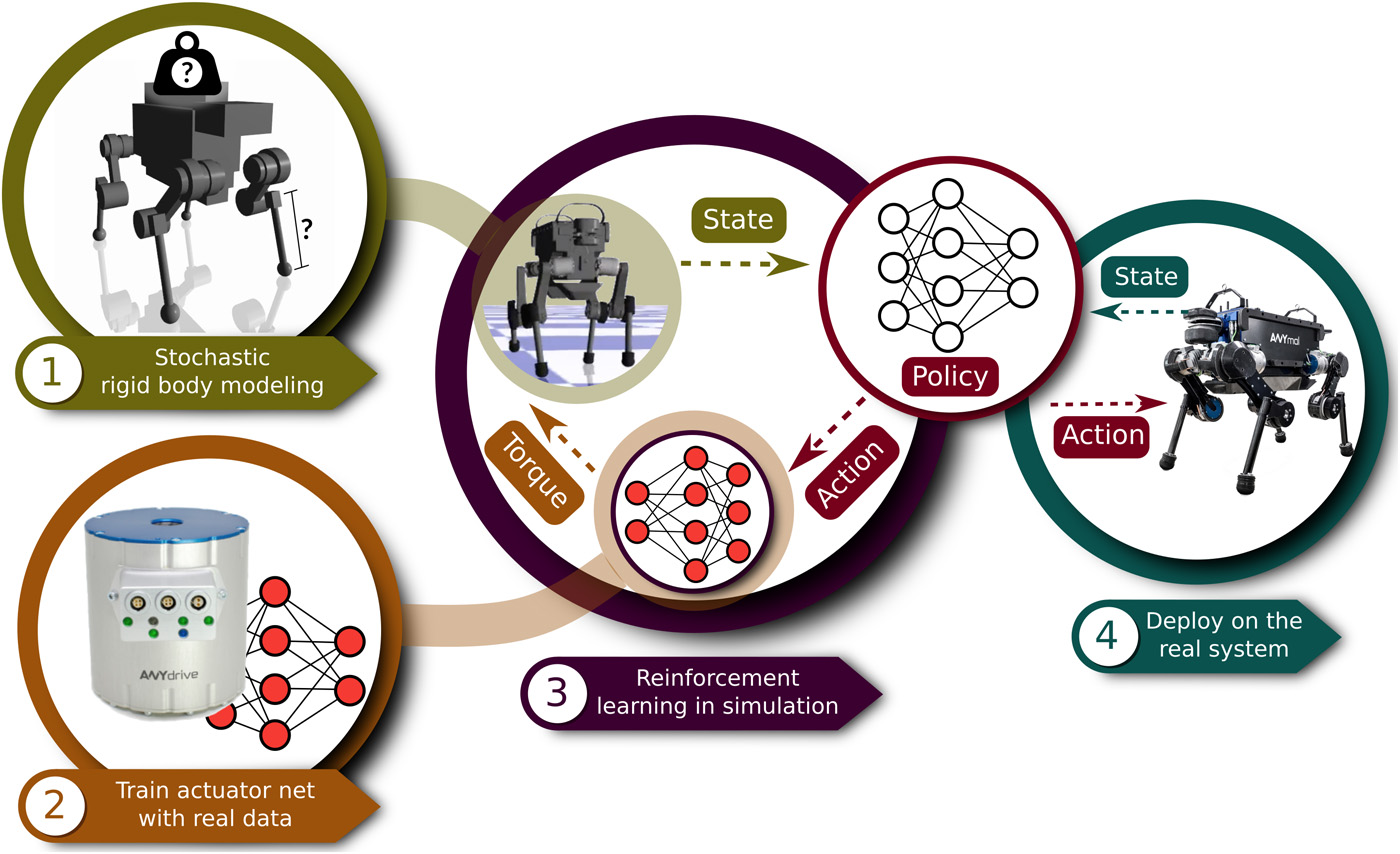
RL Weekly 5: Robust Control of Legged Robots, Compiler Phase-Ordering, and Go Explore on Sonic the Hedgehog
This week, we look at impressive robust control of legged robots by ETH Zurich and Intel, compiler phase-ordering by UC Berkeley and MIT, and a...
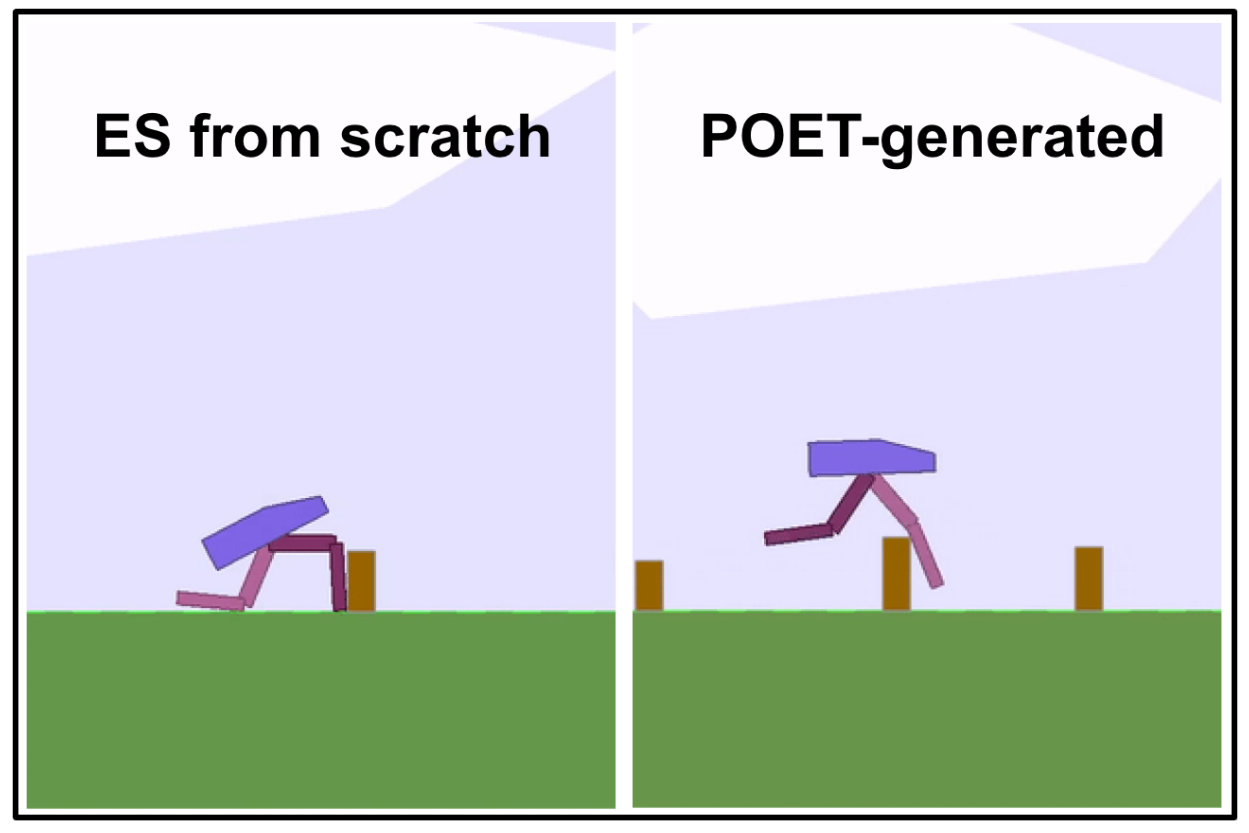
RL Weekly 4: Generating Problems with Solutions, Optical Flow with RL, and Model-free Planning
In this issue, we introduce new curriculum learning algorithm by Uber AI Labs, model-free planning algorithm by DeepMind, and optical-flow based control algorithm by Intel...

RL Weekly 3: Learning to Drive through Dense Traffic, Learning to Walk, and Summarizing Progress in Sim-to-Real
In this issue, we introduce the DeepTraffic competition from Lex Fridman's MIT Deep Learning for Self-Driving Cars course. We also review a new paper on...
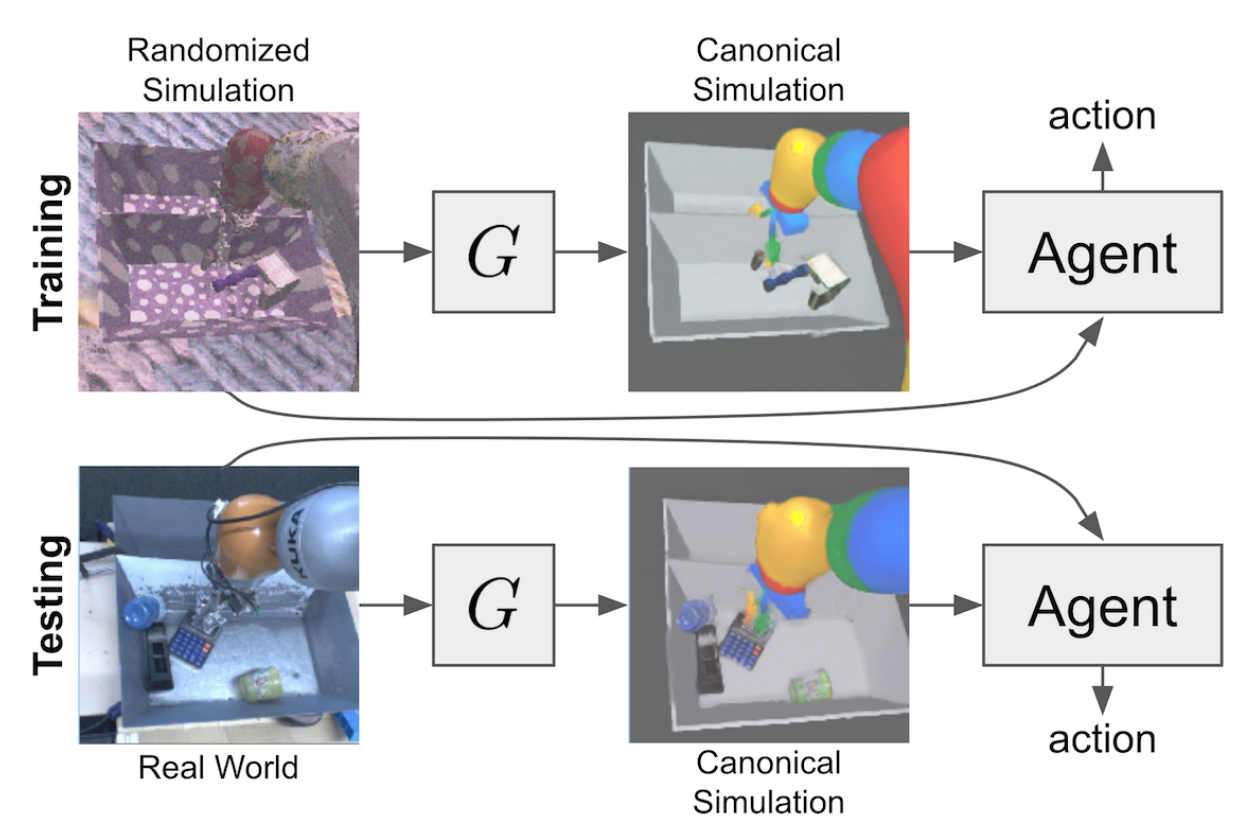
RL Weekly 2: Tuning AlphaGo, Macro-strategy for MOBA, Sim-to-Real with conditional GANs
In this issue, we discuss hyperparameter tuning for AlphaGo from DeepMind, Hierarchical RL model for a MOBA game from Tencent, and GAN-based Sim-to-Real algorithm from...
