RL Weekly 40: Catastrophic Interference and Policy Evaluation Networks
Published
Dear readers,
With COVID-19, we are going through difficult times, both as individuals and as members of society. Personally, I had to fly back to Korea and self-isolate. I sincerely wish that you, your family and your friends all stay safe.
On a more positive note, I am glad to say that RL Weekly reached 1000 subscribers. When I was writing my first issue, I did not imagine that 1000 people would read what I wrote. I will continue to collect exciting news in RL and summarize them to the best of my abilities. I hope you will stay with me on this wonderful journey!
In this issue, we look at two papers combating catastrophic interference. Memento combats interference by training two independent agents where the second agent takes off when the first agent is finished. D-NN and TC-NN reduce interference by mapping the input space to a higher-dimensional space. We also look at Policy Evaluation Network, a network that predicts the expected return given a policy.
I would love to hear your feedback! If you have anything to say, please email me.
- Ryan
On Catastrophic Interference in Atari 2600 Games
William Fedus*12, Dibya Ghosh*1, John D. Martin13, Marc G. Bellemare14, Yoshua Bengio25, Hugo Larochelle14
1Google Brain 2MILA, Université de Montréal 3Stevens Institute of Technology 4CIFAR Fellow 5CIFAR Director
What it says
Catastrophic forgetting (or catastrophic interference) is a term that describes the phenomenon where learning from one experience results in the agent “forgetting” what it has learned previously with different experiences. It has commonly been discussed in multitask learning where the agent must learn different tasks, but the authors show that this can also happen in a single environment.
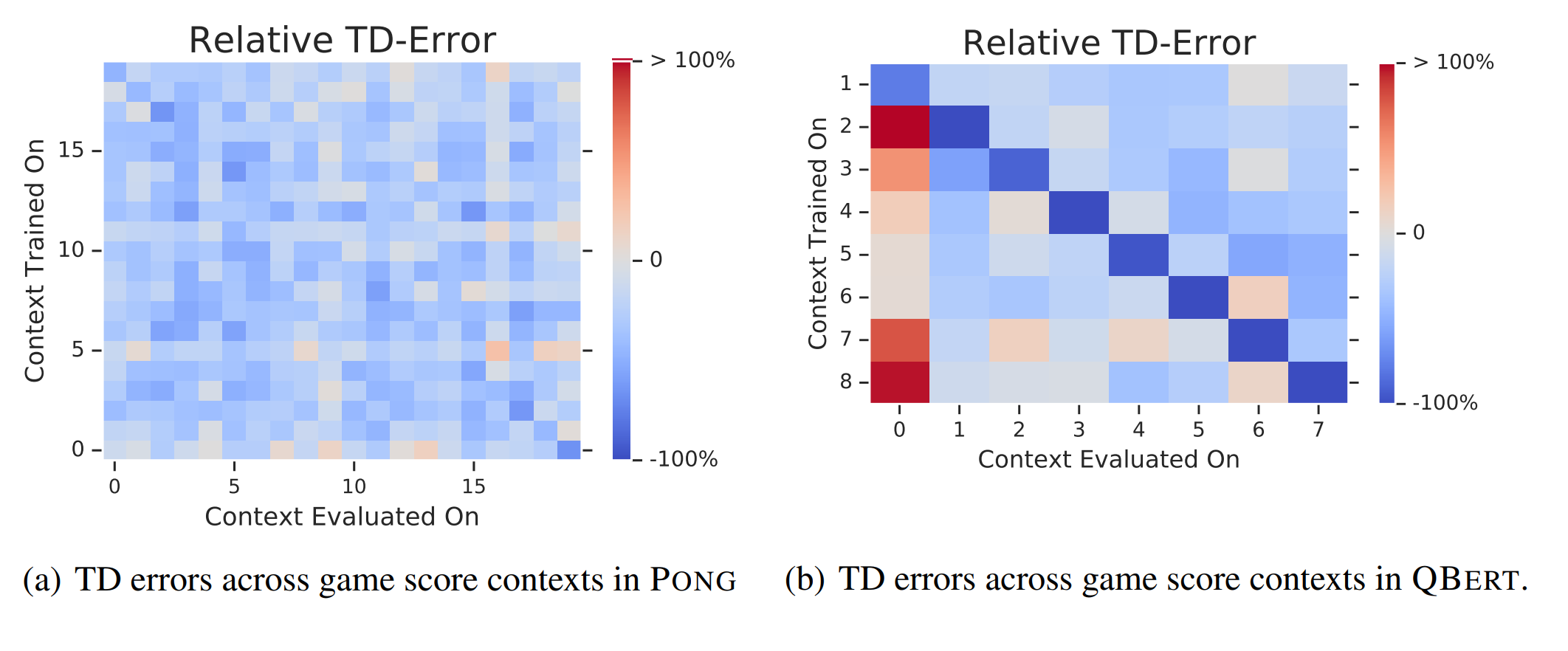
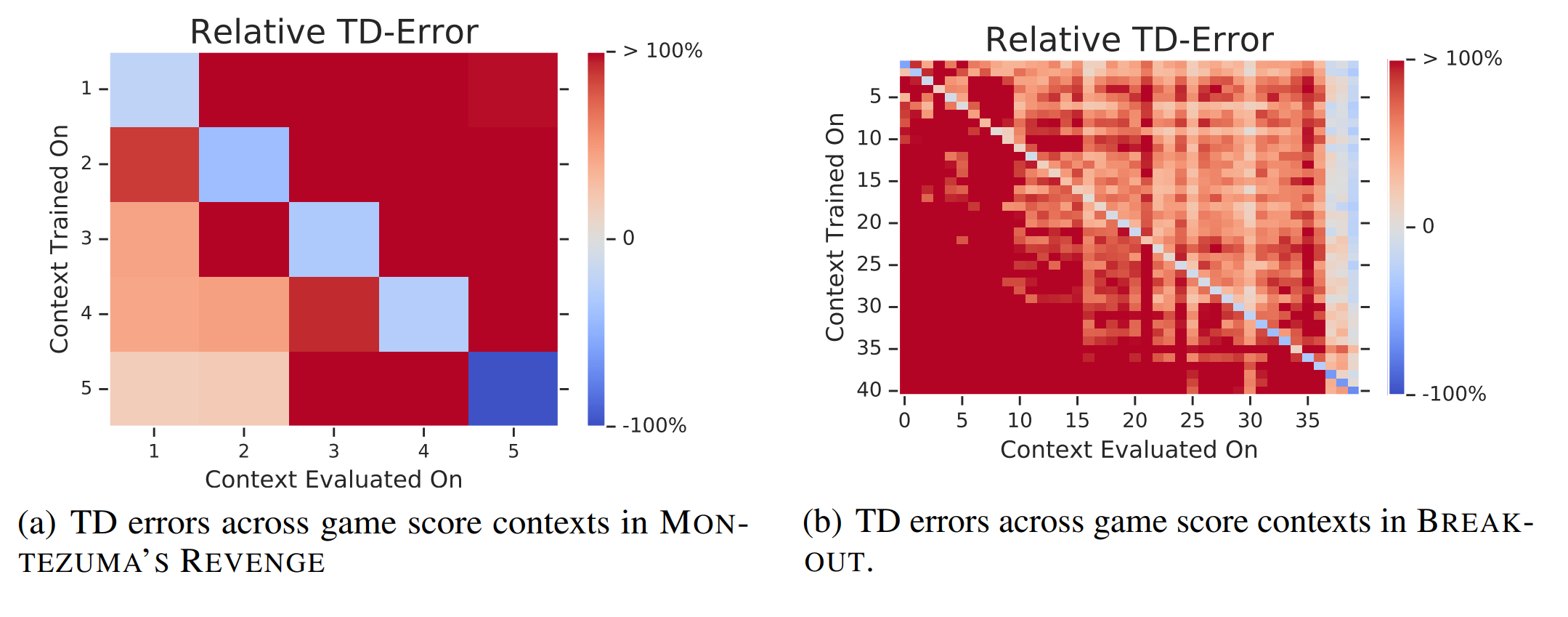
The authors establish game “context” in Arcade Learning Environment (ALE) using the game scores. Then, the authors visualize catastrophic interference by measuring the TD-errors across all contexts after training for a fixed number of steps with one of the contexts in the replay buffer. The top figures show that for Pong and Qbert, learning generalizes well between contexts, as training in one context reduces the TD-error for most of the other contexts. (Blue color denotes reduced TD-error, and red color denotes increased TD-error) However, the bottom figures show that for Montezuma’s Revenge and Breakout, learning does not generalize well between contexts. In fact, the only blue regions are the diagonal lines, so the agent learning in one context only learns about that context and “forgets” all the other contexts.
To combat this interference, the authors propose Memento, an idea of initializing a second independent agent that “begins each of its episode from the final position of the last.” Since the two agents are independent, there cannot be any interference. Using DQN and Rainbow, the authors show that Memento performs well on hard exploration Atari games such as Gravitar, Venture, and Private Eye. Furthermore, they also show that simply training one agent for twice the duration or with twice the model capacity does not perform as well as Memento, allowing them to attribute Memento’s enhanced performance to reducing interference.
Read more
Improving Performance in Reinforcement Learning by Breaking Generalization in Neural Networks
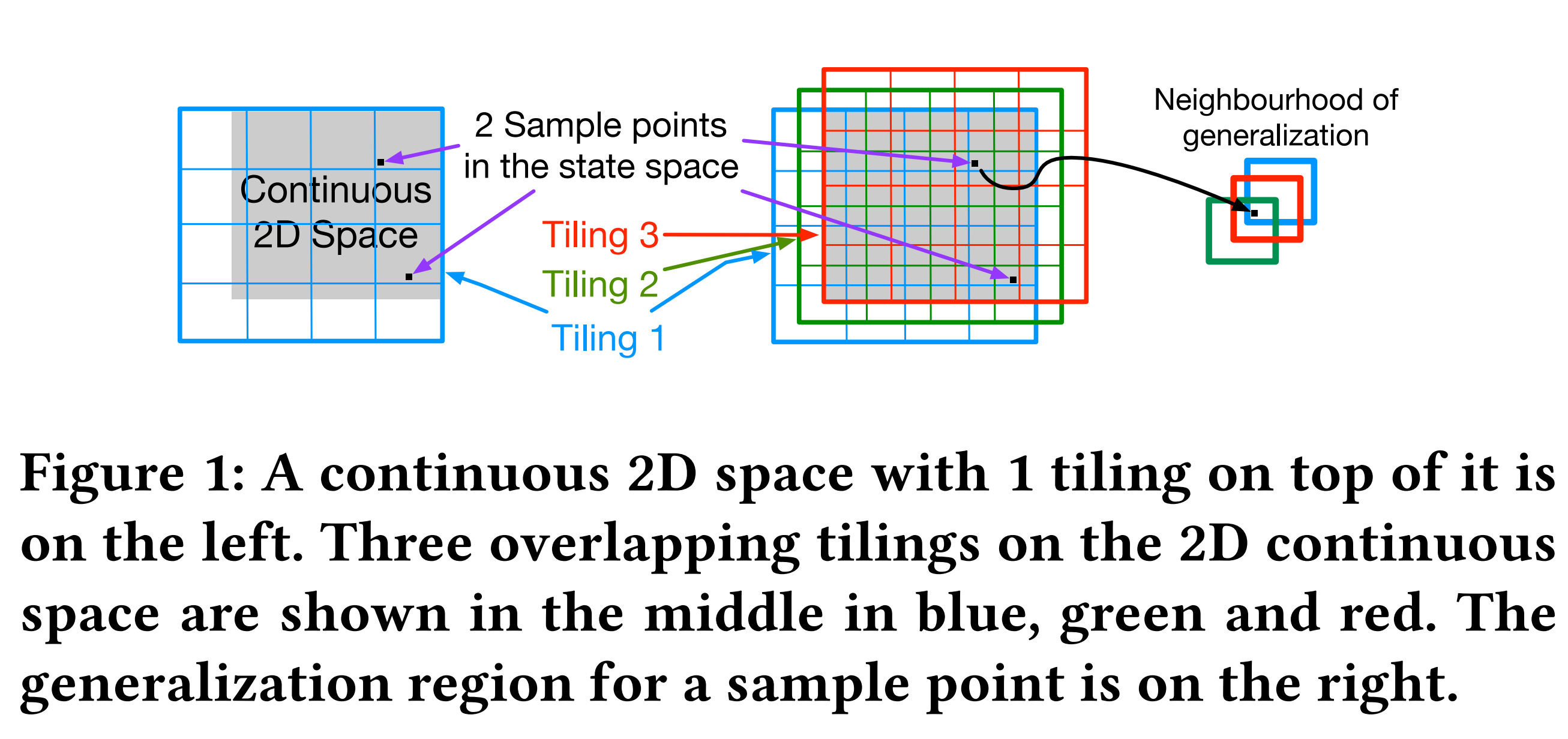
What it says
Catastrophic interference is a phenomenon where “later training decreases performance by overriding previous learning.” The authors suggest that this phenomenon could be one of the causes of deep RL algorithms being sensitive to hyperparameters and architecture choices. The authors claim that although generalization is a powerful ability, there can be “inappropriate generalization” of the inputs. For example, for Mountain Car environment where the observations are the position and the velocity of the car, “ the value function exhibits significant discontinuities.” Therefore, the authors suggest reducing this harmful generalization by mapping the observations to a higher-dimensional space. The authors test two methods: (1) “binning to discretize each dimension of the input separately,” (D-NN) and (2) tile coding as shown in the figure above (TC-NN).
The authors test their algorithm on 1 prediction problem on Mountain Car and 2 control problems on Mountain Car and Acrobot. The results show that such methods improve performance (Section 5.1, Figure 3), are generally less sensitive to step-size (Section 5.2, Figure 4), and have reduced interference (Section 5.3, Figure 5).
Read more
Policy Evaluation Networks
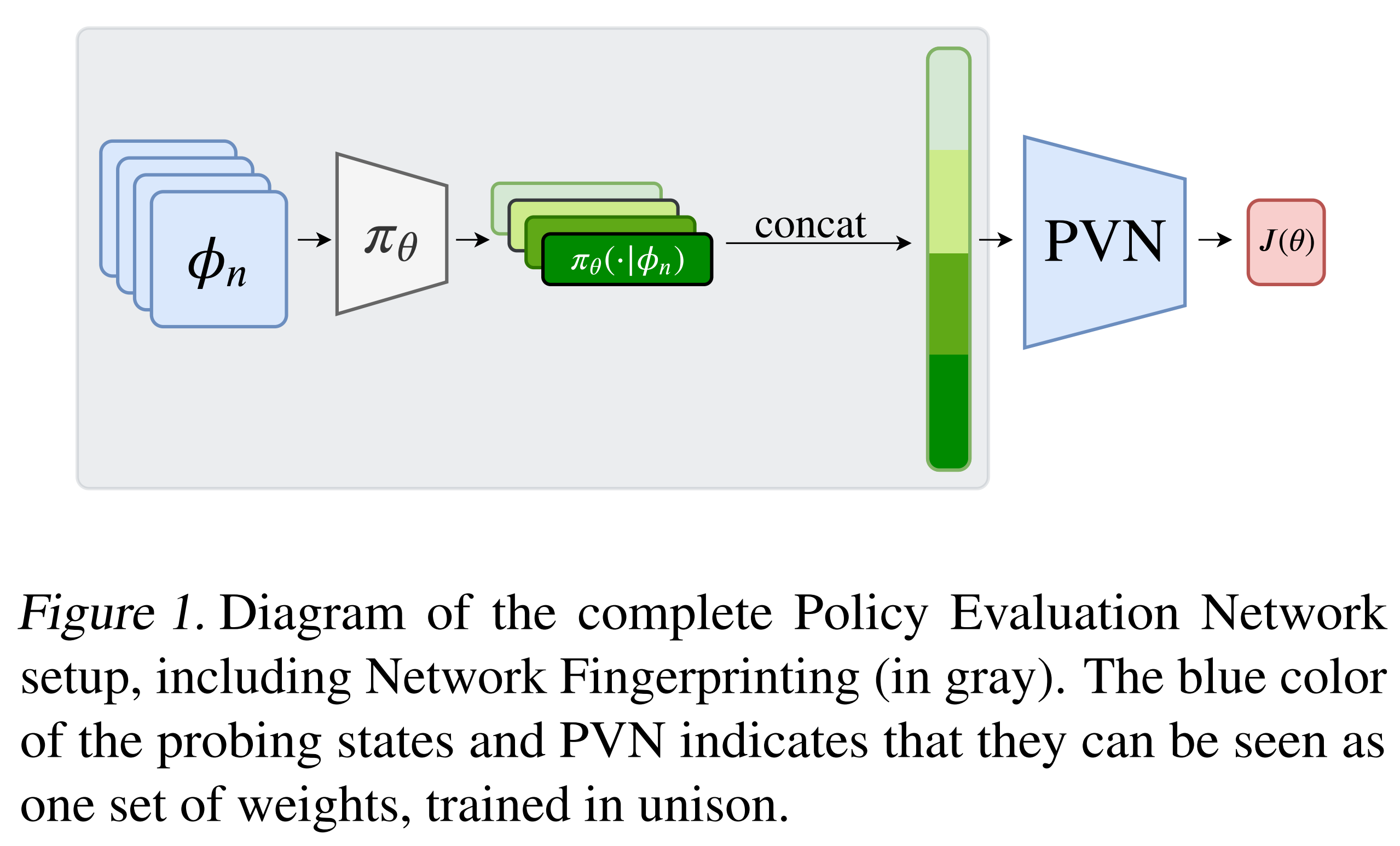

What it says
In most RL algorithms, value functions play a central role in finding a good policy, and thus it is trained with a lot of transitions. The transitions that are used to train this value function are dependent on the current policy, so the value function estimate is “influenced by previously seen policies, possibly in an unpredictable way.” To “generalize the value function among different policies” authors suggest giving some description of the policy as an input. The authors propose Policy Evaluation Network (PVN), a neural network that predicts the expected cumulative reward of a given policy. PVN is fully differentiable and can be trained with supervised learning. The PVN can be trained with a dataset of pairs of randomly initialized policies and corresponding expected returns obtained through Monte-Carlo rollouts. After training, the policy can be improved with gradient ascent in the space of parametrized policies without environment interaction.
To represent a policy to give as the input to the PVN, simply flattening and concatenating layers of the policy network may lose valuable information on the dependencies between layers. Therefore, the authors propose “network fingerprinting,” where the policy is characterized by the outputs when it is given a set of “probing states.” These probing states synthetic inputs with the purpose of accurately representing the policy. To choose the probing states, the authors randomly initialize them and train them using backpropagation along PVN. (This is possible since the entire PVN is differentiable.)
The authors test PVN on 2-state MDP, CartPole, and MuJoCo Swimmer. The results in CartPole show that network fingerprinting is necessary for multilayered policy networks, and the results in Swimmer show that PVN can perform better than DDPG, TD3, and SAC.
Read more
Here is some more exciting news in RL:
Maxmin Q-learning: Controlling the Estimation Bias of Q-learning
Reduce the overestimation bias by maintaining multiple estimates of the action value and using the minimum of them as the Q-learning target.
Estimating Q(s,s’) with Deep Deterministic Dynamics Gradients
Create a value function that estimates the return when transitioning from one state to another. This “decouples actions from values” and allows (1) off-policy learning with observations from suboptimal or random policies and (2) learning on environments with redundant action spaces.
TWIML: Advancements in Reinforcement Learning with Sergey Levine
This is a 42-minute TWIML AI Podcast with Sergey Levine.
TWIML: Upside-Down Reinforcement Learning with Jürgen Schmidhuber
This is a 33-minute TWIML AI Podcast with Jürgen Schmidhuber.
Self-Tuning Deep Reinforcement Learning
Use metagradients to self-tune important hyperparameters of IMPALA such as discount factor, bootstrapping parameter, and loss weights, resulting in better performance.
Jelly Bean World: A Testbed for Never-Ending Learning
A new 2D gridworld environment for lifelong learning with vision and “scent” observations.