RL Weekly 41: Adversarial Policies, Image Augmentation, and Self-Supervised Exploration with World Models
Published
Dear readers,
In this issue, we look at adversarial policy learning, image augmentation in RL, and self-supervised exploration through world models.
I would love to hear your feedback! If you have anything to say, please email me.
- Ryan
Adversarial Policies: Attacking Deep Reinforcement Learning
Adam Gleave1, Michael Dennis1, Cody Wild1, Neel Kant1, Sergey Levine1, Stuart Russell1
1UC Berkeley
What it says
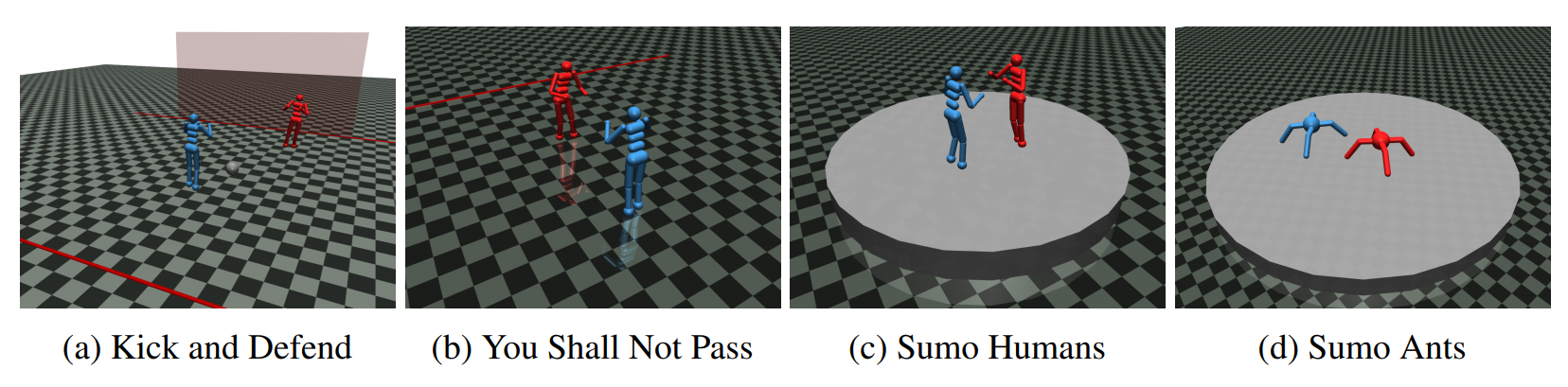
In one-player RL benchmarks Atari or MuJoCo, the environment does not actively try to make agents fail. In contrast, in zero-sum games such as Chess or Go, the opponent strives to crush the agent. Such a setting requires the agent to be robust against diverse opponent strategies, and many researchers have used self-play to ensure robustness. However, what happens if an adversarial opponent is directly trained against the agent?
The authors show that the adversarially trained opponents could reliably beat the “victims”, not by becoming better at the task, but by creating adversarial observations. Four two-player robotics games shown above are used as environments, and the adversaries are trained with Proximal Policy Optimization (PPO) with a sparse reward for match results. The video above shows the “You Shall Not Pass” environment, where the runner’s goal is to reach the finish line, and the blocker’s goal is to prevent that. In the video, the trained adversary (red humanoid) never stands up, yet the victim (blue humanoid) struggles to reach the finish line.
The authors offer further analysis of this phenomenon. Against humanoid with random actions and one with no actions, the victim consistently wins, showing that the victim policies are “robust to off-distribution observations that are not adversarially optimized.” The authors also test “masked” victims that cannot observe the adversary’s position and find that the masked victim can reliably win against the adversary, although it struggles against normally trained opponents. Finally, the authors show that victims that are fine-tuned against an adversary is robust against that particular adversary, but is still vulnerable to a different adversary trained with this same method against the fine-tuned victim.
Read more
Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels
Ilya Kostrikov1*, Denis Yarats12*, Rob Fergus1
1New York University 2Facebook AI Research

What it says
Data Augmentation is widely used in vision and speech domains, but it is not often used in RL, especially in non-robotics domains. (In robotics, OpenAI used extensive data augmentation for dexterous in-hand manipulation, and Hindsight Experience Replay can also be seen as a type of data augmentation.) To justify the need for data augmentation, the authors train Soft Actor-Critic (SAC) on the DeepMind control suite using image encoder architectures of various sizes while keeping the policy network architecture the same. The performance decreases as the parameter count of the encoder network increases, indicating that there is an overfitting problem. The authors propose Data-regularized Q (DrQ), an algorithm that uses image augmentation in RL to perturb input observations and regularize the Q-function.
DrQ can be divided into three parts, denoted Orange, Green, and Blue in the pseudocode above. The first augmentation is performed on the observations sampled from the replay buffer by shifting the 84-by-84 image by 4 pixels. The second augmentation is done on target Q-function by estimating Q-values of augmented observations and taking the mean of those values to reduce the variance. Similarly, the third augmentation is done on the Q-function.
In DeepMind control suite, DrQ with SAC achieves equal or better performance compared to CURL, PlaNet, SAC-AE, and SLAC, with scores comparable to SAC trained with internal states.
Read more
Planning to Explore via Self-Supervised World Models
Ramanan Sekar1*, Oleh Rybkin1*, Kostas Daniilidis1, Pieter Abbeel2, Danijar Hafner34, Deepak Pathak56
1University of Pennsylvania 2UC Berkeley 3Google Research, Brain Team 4University of Toronto 5Carnegie Mellon University 6Facebook AI Research
What it says
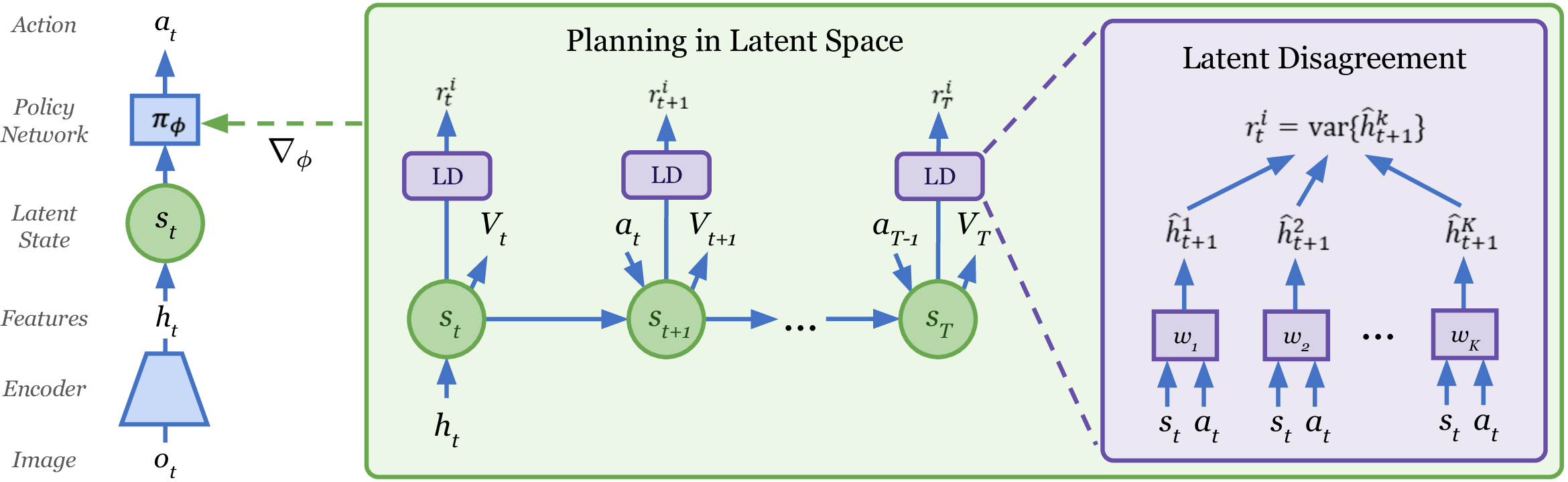
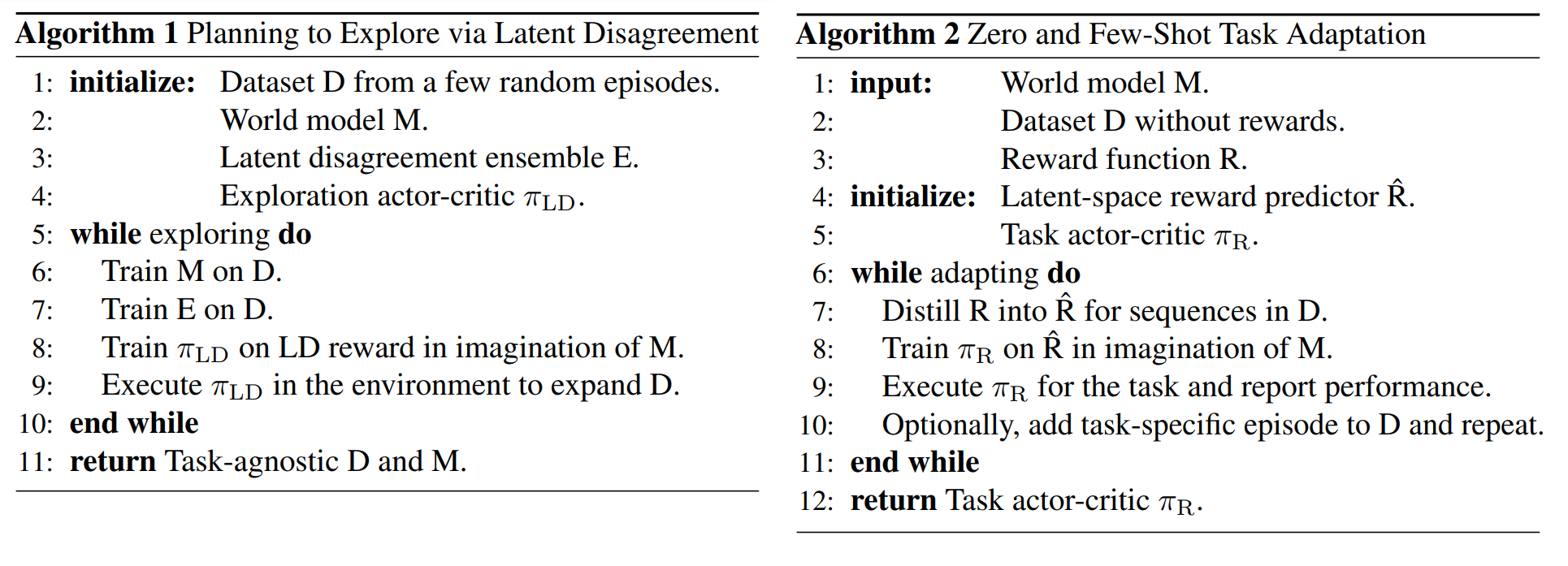
Most RL agents are specialists: they excel at one pre-specified task but fail to generalize between tasks. To develop a task-agnostic agent, the authors propose training the agent in an environment without specifying a task. Since a task is defined by the reward function, the agent must learn without any rewards through self-guided exploration. The authors address this exploration problem by learning a world model to estimate “the expected novelty of future situations” without actual environment interactions.
The learning occurs in two phases: the model learning phase and the task adaptation phase. In the first phase, the agent gathers trajectories to train both the world model and the latent disagreement ensemble. The agent is then trained using the world model with latent disagreement rewards to encourage exploration. The trained agent is then deployed to the real environment again to gather more trajectories and the process is repeated. In the second phase, the policy is fine-tuned using the world model with a reward function distilled to the latent space. The trained agent collects task-specific trajectories that are added to the dataset, and the process is repeated.
The Plan2Explore algorithm is tested in the DeepMind control suite in two settings: zero-shot learning and few-shot learning. For zero-shot learning, the agent cannot collect task-specific trajectories in the adaptation phase and must be trained without reward supervision. Plan2Explore achieves better performance than other unsupervised RL agents such as Curiosity and Model-based Active Exploration (MAX). For few-shot learning, Plan2Explore also achieves better performance than other unsupervised RL agents and is able to achieve scores competitive to RL agent with task supervision (Dreamer) after just a few episodes.
Read more
Here is some more exciting news in RL:
Chip Design with Deep Reinforcement Learning
The Google Brain team published a preprint and a blog post on using RL to generate chip placements that “are superhuman or comparable on modern accelerator netlists.”
David Silver: AlphaGo, AlphaZero, and Deep Reinforcement Learning | AI Podcast #86 with Lex Fridman
Lex Friedman’s 2-hour conversation with David Silver (DeepMind) is available on YouTube.
Introduction to Multi-Armed Bandits
A book on multi-armed bandits by Aleksandrs Slivkins (Microsoft Research) is available online.
ML-Agents v1.0
Unity released version 1.0 of ML-Agents, an open-source project for training agents in games and simulations made with Unity.
NetHack Learning Environment
Facebook Research released a new RL environment based on NetHack, a roguelike dungeon exploration game.
RL Theory Seminar
Seminars on reinforcement learning theory are being held virtually every Tuesday. The next one is by Nan Jiang (UIUC) on “Information-Theoretic Considerations in Batch Reinforcement Learning.”
Suphx: Mastering Mahjong with Deep Reinforcement Learning
Microsoft Research Asia built Suphx, a Mahjong AI trained with deep RL, which achieved rank above most (99.99%) human players.
TalkRL: The Reinforcement Learning Podcast
The TalkRL Podcast has new podcasts with interviews with Danijar Hafner (U. Toronto), Csaba Szepesvari (DeepMind), and Ben Eysenbach (CMU).