RL Weekly 42: Special Issue on NeurIPS 2020 Competitions
Published
Dear readers,
This is a special issue of RL Weekly! The NeurIPS 2020 competitions have been announced, and there are four (4) competitions that explicitly mention reinforcement learning: ProcGen, L2RPN, MineRL, and Flatland. I hope you find this special issue informative, and perhaps participate in one of them.
This week, I received a very kind email that made my day from one of my subscribers. I am sincerely grateful for all your support, and I hope that RL Weekly has been a helpful resource for following the latest trends of reinforcement learning. I will continue to work hard to improve the content of each issue.
This is my first special issue, so I would love to hear your feedback! If you have anything to say, please email me.
- Ryan
MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors

What it is
The MineRL project offers OpenAI Gym-style Minecraft environments. In the MineRL Competition environment, the agent’s goal is to obtain diamonds, a rare item in Minecraft that only exists deep underneath the surface. To obtain a diamond, the agent must craft an iron pickaxe, an item required to mine the diamond. Similarly, the agent must perform different subtasks to craft an iron pickaxe. Therefore, obtaining a diamond is a very complex task. To make this task more tractable, small rewards are also given when such prerequisite items are obtained. However, even with such rewards, this task is a very difficult one.
The goal of this competition is to develop algorithms that can “effectively leverage human demonstrations to drastically reduce the number of samples.” The organizers only allow 8 million samples from the simulator and 4 days of training on a single GPU machine (P100). Instead, they provide the MineRL-v0 dataset which has over 60 million frames of human demonstrations. To be successful, the agent must utilize the demonstrations, perhaps through imitation learning or offline RL.
In a previous competition, the observation and actions were human-readable hashmaps (dictionaries) that allowed participants to apply Minecraft-specific human priors. To limit such behavior, this year’s competition environment has obfuscated observation and action space.
The competition has two rounds, with the first round from July to September and the second round from September to November.
What I think
In last year’s competition, no agent was able to obtain a diamond. I wonder if the winner will be able to find one this time!
Read more
- MineRL Website
- Competition Website (AICrowd)
- Competition Starter Kit (GitHub Repository)
- SlidesLive Presentation of 2019 Competition
- MineRL Project Documentation
- MineRL-v0 Dataset
- ArXiv Preprint (2019)
ProcGen Challenge

What it is
The ProcGen benchmark consists of 16 OpenAI Gym environments that are procedurally generated. Procedurally generated environments generate new levels for every episode, testing the agent’s ability to generalize to unseen events. In this competition, the agent’s performance is measured in both the 16 public ProcGen environments and the 4 secret unreleased ProcGen environments. For each environment, an environment-specific agent is trained for 8 million timesteps for a maximum of 2 hours on a machine with 16 vCPUs and a P100 GPU. The trained agent is then evaluated with 200 procedurally generated levels.
The competition has three rounds: warm-up round, general round, and final round. The warm-up round lasts until July 6th. Round 1 is from July 7th to August 31st, and Round 2 is from September 1st to October 19th.
What I think
The organizers (OpenAI) hosted another competition in 2018 called the Retro Contest, which tested the agents in similar settings on Sonic the Hedgehog environments. It will be interesting to see how similar or different the winners’ algorithms of the two competitions are.
Read more
- Competition Website (AICrowd)
- ProcGen Benchmark (ArXiv Preprint)
- ProcGen Benchmark (GitHub Repo)
- Retro Contest Website
Learning To Run a Power Network Challenge
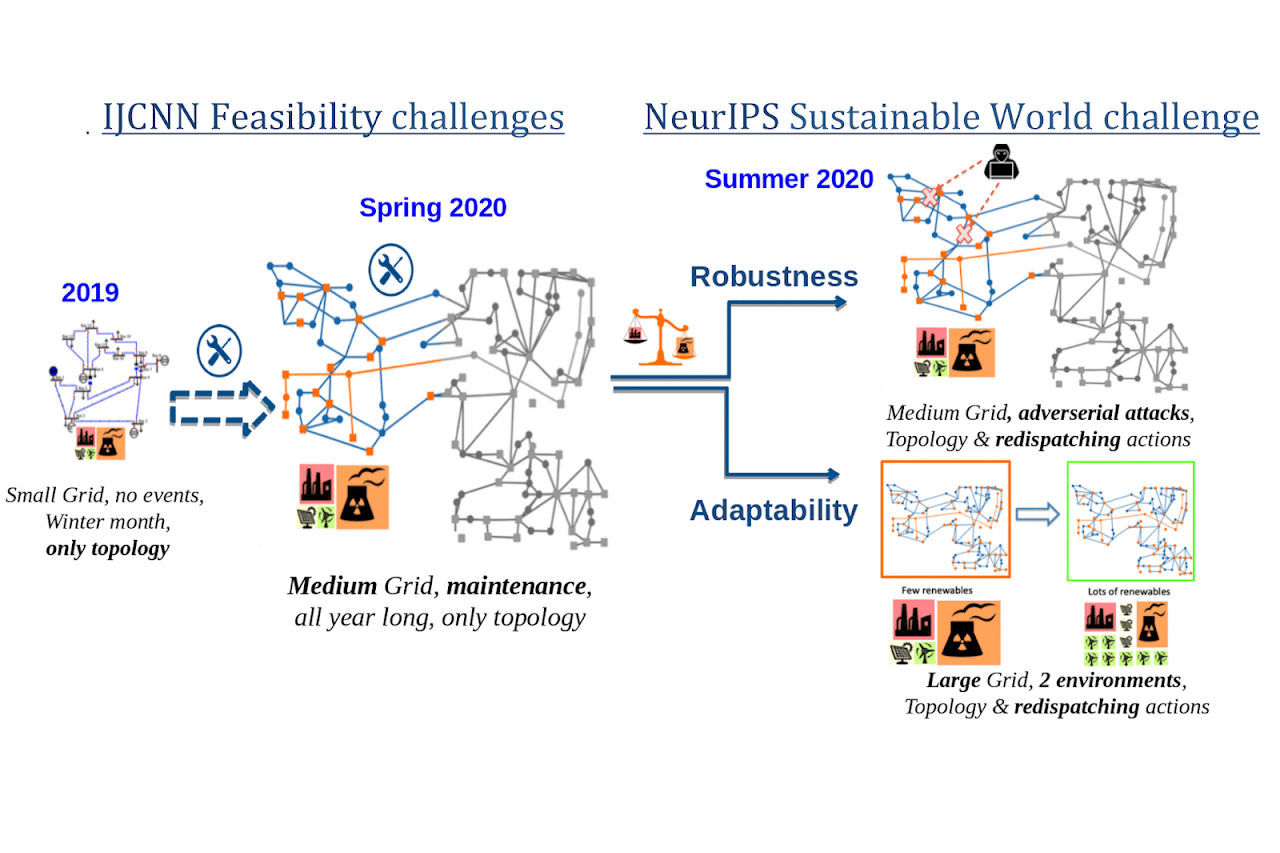
What it is
Power networks (grid) transport and distribute electricity across states, countries, and continents. Since electricity is used in all parts of modern societies, power networks play an important role in the modern world. However, managing the power grid requires constant monitoring and control, and a single mistake can lead to electricity blackouts that halt many services. Therefore, there is great interest in developing “smart” grids that are adaptable, sustainable, and robust.
In this competition, the agent is trained on a series of predefined scenarios on Grid2Operate, a power network simulator. The agent will then be evaluated on hidden scenarios with “the same grid layout but with different weather, production, consumption conditions and events.”
Before this NeurIPS competition, similar competitions were also held in IJCNN 2019 and WCCI 2020. This competition is a continuation of those competitions with a larger grid, larger action size, and more realistic scenarios such as out-of-distribution adversarial attacks or non-stationary environments.
The competition starts on July 8th, 2020, and ends on October 20th.
What I think
This challenge is fascinatingly different from other competitions in that the agent must be reliable. I am excited to see what methods will be used to enhance the agent’s robustness.
Read more
- Competition Website
- Challenge Design Document PDF
- GitHub Repository of Geirina Team (IJCNN 2019 1st Place)
- GitHub Repository of Learning_RL Team (IJCNN 2019 2nd Place)
Flatland Challenge
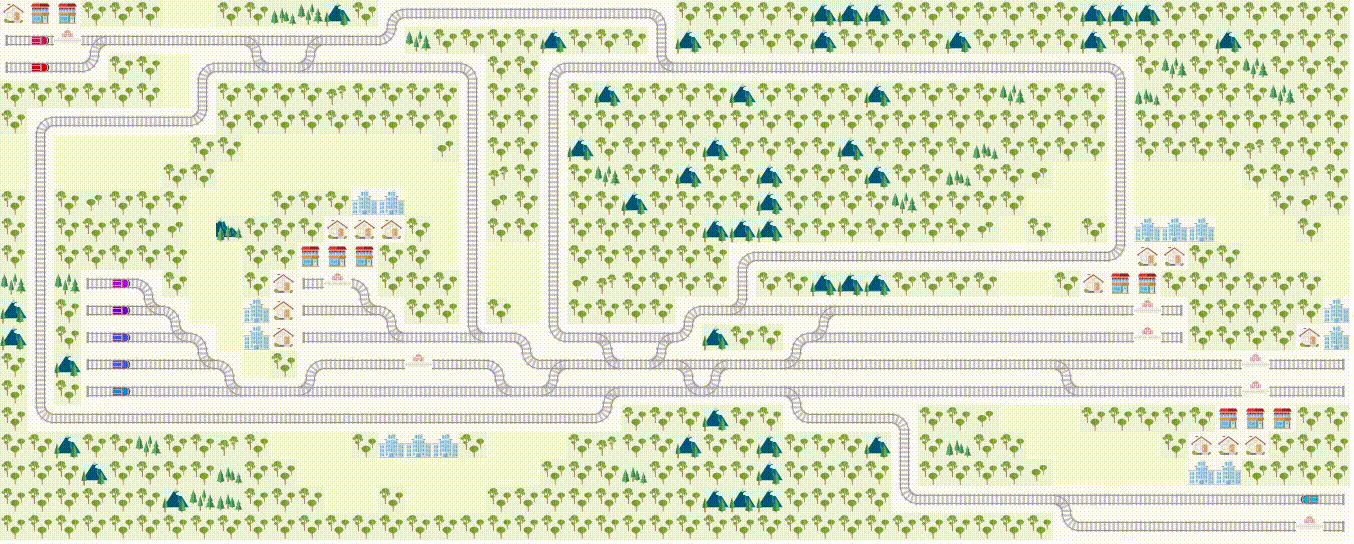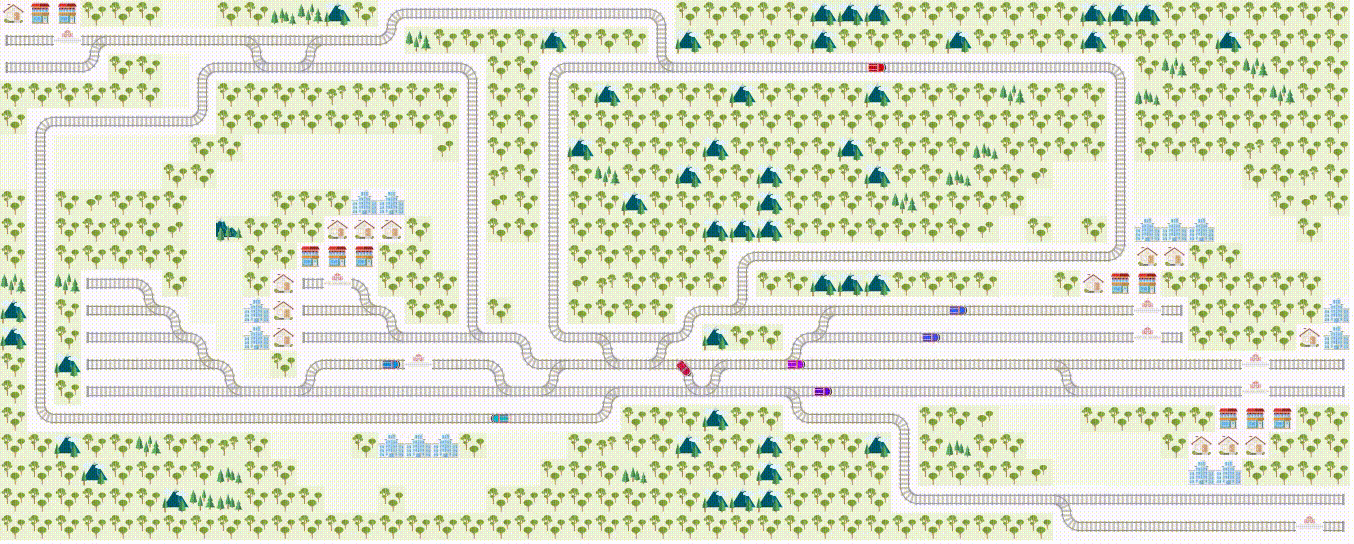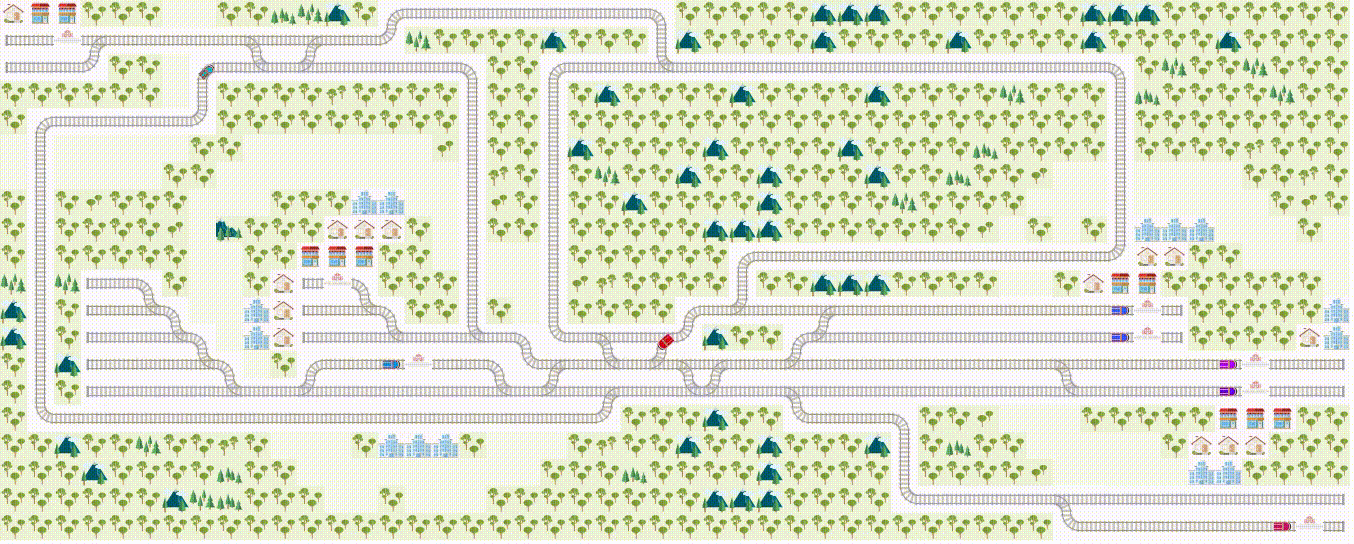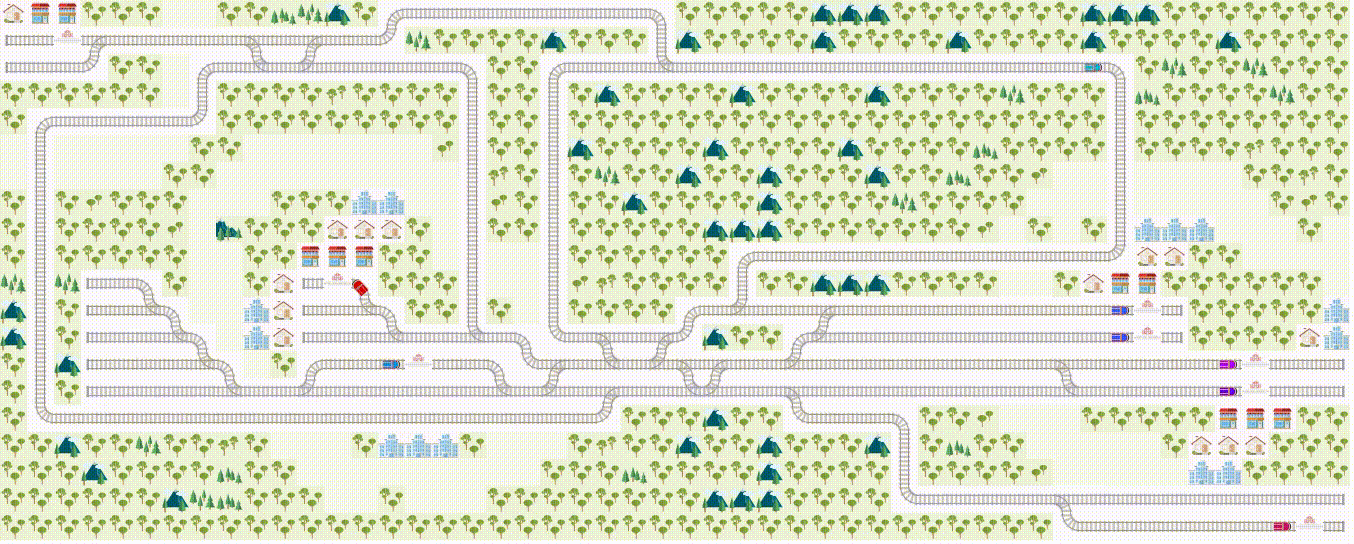
What it says
This challenge addresses the train scheduling problem in a multi-agent setting. The Flatland environment is a grid world environment with railroads and trains, where each agent controls one train to make limited movements following the railroad. The goal is to “make all the trains arrive at their target destinations at minimal travel time,” so the agent receives a constant negative reward until it reaches its target location.
To “efficiently manage dense traffic on complex railway networks,” the agents must be able to plan ahead. The agents are given 5 minutes of initial planning time, and once the environment starts, the agents have 5 seconds per time step.
The competition has a warm-up round until July 7th. The first round that immediately follows the warm-up round lasts until July 31st and the second round starts on August 1st and ends on October 19th.
What I think
This competition clearly states the importance of planning for success. It will be interesting to see how well RL algorithms fare against other non-RL algorithms.
Read more
- Competition Website (AICrowd)
- Flatland Docs
- Flatland Docs: Environment
- Flatland Docs: Getting Started
- Flatland Docs: 2019 Solutions
Here is some more exciting news in RL:
Agent57: Outperforming the human Atari benchmark
DeepMind developed Agent57, an agent that outperforms the human baseline on all 57 Atari 2600 environments. Agent57 is a collection of numerous incremental improvements made to DQN, short-term memory, episodic memory, exploration, and meta-controller.
Enhanced POET: Open-Ended Reinforcement Learning through Unbounded Invention of Learning Challenges and their Solutions
Uber AI Labs improved POET to be “more effectively generate and exploit diversity” through four innovations.
Robotic Table Tennis with Model-Free Reinforcement Learning
Google and DeepMind successfully trained a multi-modal model-free RL agent that can control a simulated table tennis robot through reward shaping and curriculum learning.