RL Weekly 43: Revisiting Experience Replay, On-Policy Methods, and Rainbow
Published
Dear readers,
Yesterday, DeepMind’s AlphaFold 2 made a major breakthrough for the protein folding problem. It is an exciting work that shows just how much impact AI can have in the real world. Reinforcement learning also has great potential to help make such scientific discoveries, and I hope to see such results in the next few years.
You may have noticed that RL Weekly went on a long hiatus. With this issue, the newsletter will be published again at a steady pace. However, I am contemplating whether to decrease the frequency to once per two weeks or once a month to further polish each issue. If you have any suggestions or feedback on this issue, feel free to email me.
In this issue, we examine large scale experiments that illuminate the design decisions of various components of reinforcement learning. Notably, we see (1) the surprising connection between experience replay and $n$-step returns, (2) the effect of various hyperparameters in on-policy reinforcement learning algorithms, and (3) the effect of components of Rainbow in environments with lower computational requirements.
- Ryan
Revisiting Fundamentals of Experience Replay
William Fedus*12, Prajit Ramachandran*1, Rishabh Agarwal1, Yoshua Bengio23, Hugo Larochelle14, Mark Rowland5, Will Dabney5
*Equal contribution 1Google Brain 2MILA, Universite de Montreal 3CIFAR Director 4CIFAR Fellow 5DeepMind
Summary
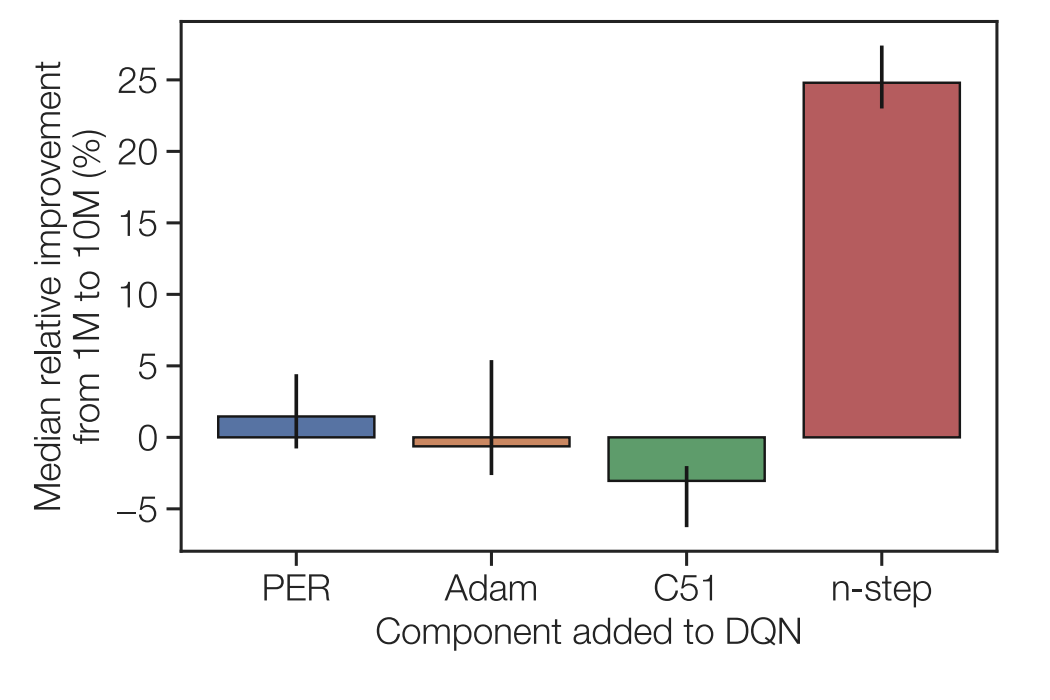
Experience replay is a critical component of Deep Q-Network (DQN), but it is difficult to analyze the various parameters of experience replay as they are intertwined. The authors study the effect of varying the maximum size of the replay buffer (replay capacity) and the number of gradient steps taken for the oldest transition in the buffer (age of the oldest policy). Empirically, the performance of the Rainbow agent increases as the replay capacity increases and as the age of the oldest policy decreases.
However, unlike the Rainbow agent, the DQN agent does not improve as the replay capacity increases. Through an additive and an ablative study of each component of the Rainbow (prioritized experience replay, C51, Adam optimizer, and $n$-step returns), the authors find that $n$-step returns is the component responsible for the discrepancy between DQN and Rainbow as the replay capacity increases.
Through a few testable hypotheses, the authors find that the effect can be partially explained by increased replay capacity reducing the added variance of $n$-step returns. Because a bigger replay buffer has more diverse transitions, the distribution of transitions shifts slower, mitigating the effect of high variance $n$-step returns. However, the explanation is only partial, and that additional causes may exist.
Thoughts
Rainbow is a great baseline that achieves great performance by incorporating multiple improvements to the DQN algorithm. However, the multiple components make it difficult to understand the causes of various properties of Rainbow, as combinations of these components produce phenomena that do not appear when individual components are tested. This paper is great as it showcases one method to narrow the cause of the effect through additive and ablation studies.
Read more
What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study
Marcin Andrychowicz1, Anton Raichuk1, Piotr Stańczyk1, Manu Orsini1, Sertan Girgin1, Raphael Marinier1, Léonard Hussenot1, Matthieu Geist1, Olivier Pietquin1, Marcin Michalski1, Sylvain Gelly1, Olivier Bachem1
1Google Research, Brain Team
Summary
On-policy algorithms have been used widely in control tasks, both in simulations and in reality. Since REINFORCE, many algorithms have been invented by multiple researchers, and each algorithm came with different design decisions, from neural network architectures to regularization methods. Unfortunately, recent works show that such design decisions can impact performance, making it nearly impossible to correctly attribute performance gain. To demystify this problem, the authors conducted a large-scale empirical study, training more than 250000 agents.
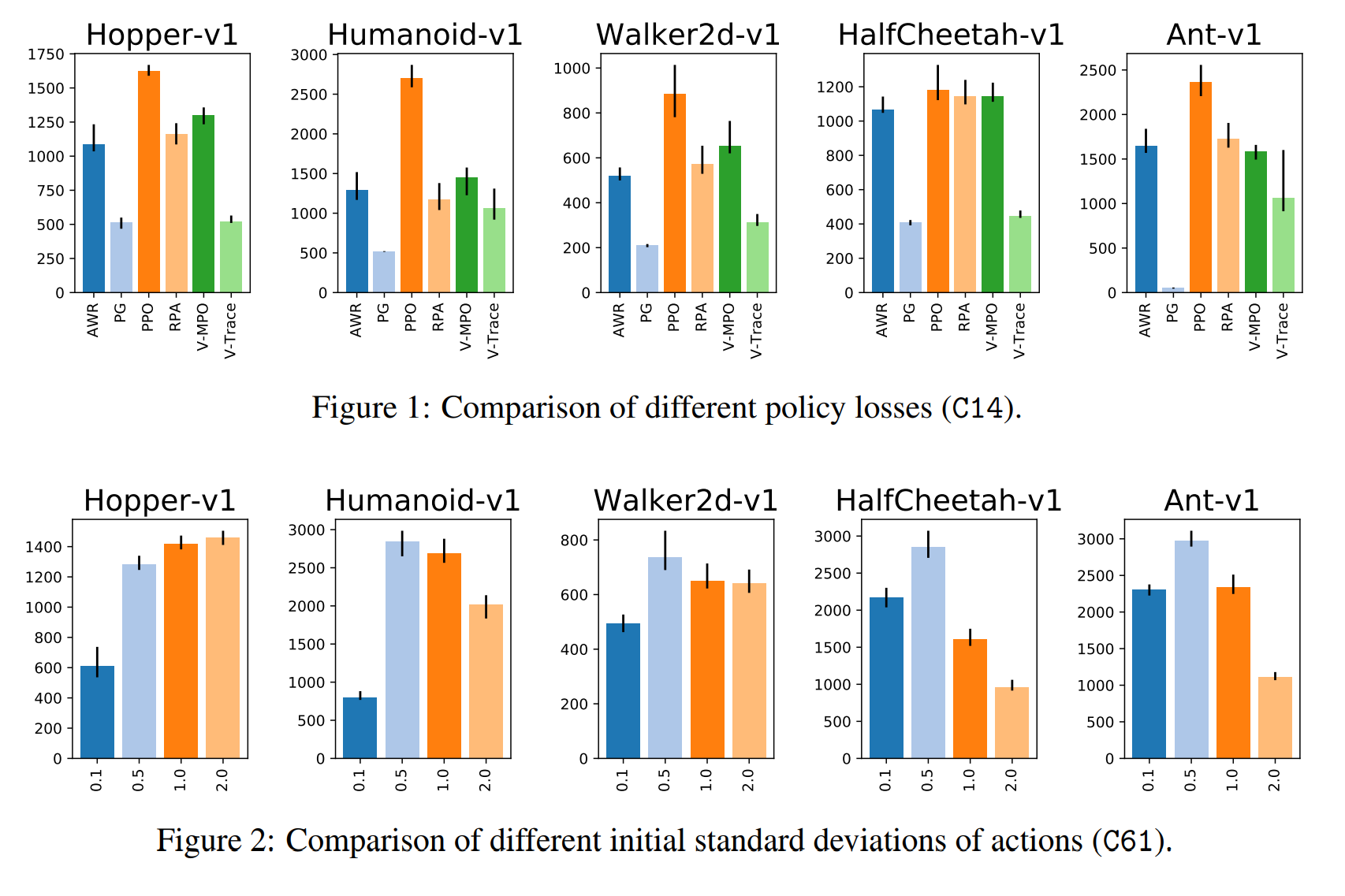
For the experiments, the authors grouped design choices into eight thematic groups. Then, for each group, the choices were randomly sampled within the group while using the default configuration for choices outside the group. The authors interpret the results separately for each group and give a recommendation, summarized below.
- Policy Losses: Use the PPO policy loss with the clipping threshold set to 0.25. Tune threshold value if needed.
- Network Architecture: Separate value and policy networks and tune width of policy MLP. Initialize the last policy layer with $100 \times$ smaller weights.
- Normalization and clipping: Always use observation normalization. Try value function normalization and gradient clipping.
- Advantage Estimation: Use GAE with $\lambda = 0.9$ but neither Huber loss nor PPO-style value loss clipping.
- Training setup: Go over experience multiple times. Shuffle individual transitions before assigning them to minibatches and recompute advantages once per data pass. Tune the number of transitions in each iteration.
- Timesteps handling: Tune discount factor $\gamma$ with initial value $0.99$. Try frame skip if possible.
- Optimizers: Use Adam optimizer with momentum $\beta_1 = 0.9$ and a tuned learning rate (0.0003 is a safe default).
- Regularization: Not useful in this study.
Thoughts
I find large-scale empirical studies like this paper beautiful. It shows how much we have yet to learn about existing algorithms and also points at future areas of research. I highly recommend reading the full paper to researchers or practitioners looking to study or use on-policy methods, as the summary above does not fully convey the insight of the paper.
Read more
Revisiting Rainbow: Promoting More Insightful and Inclusive Deep Reinforcement Learning Research
Johan S. Obando-Ceron, Pablo Samuel Castro1
1Google Research, Brain Team
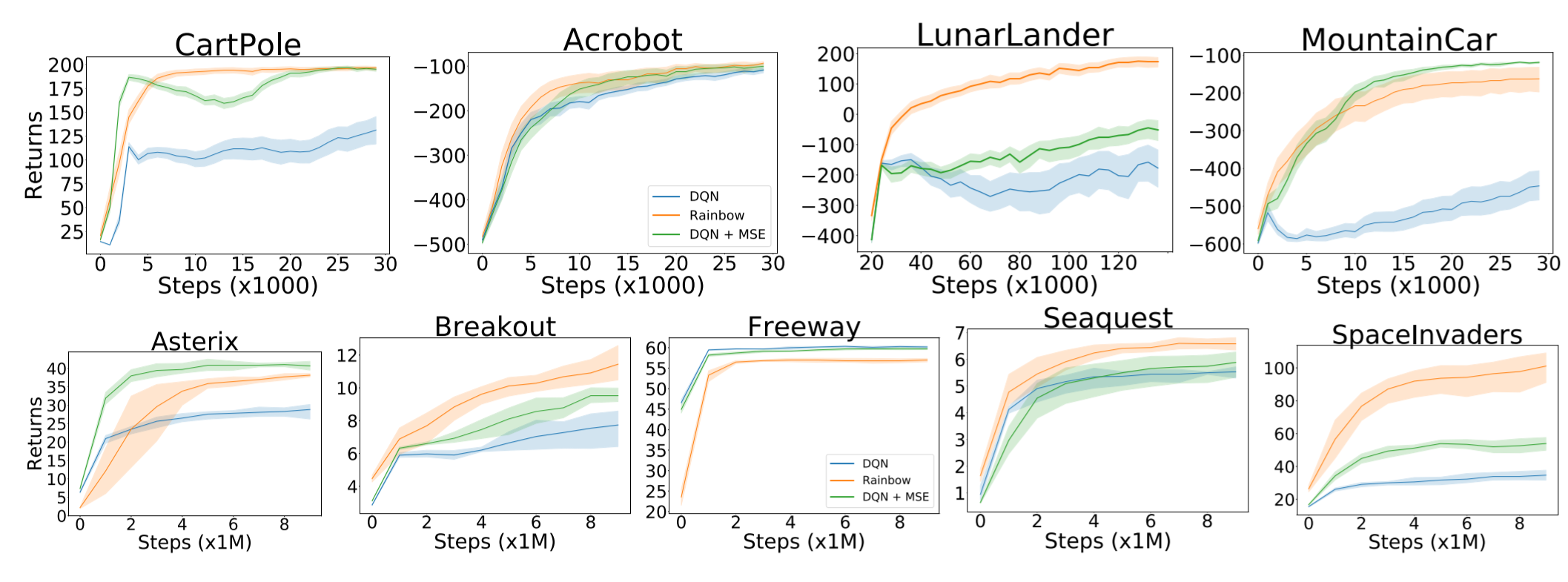
Summary
One of the most popular benchmarks for deep RL algorithms is the Arcade Learning Environment (ALE). Although its wide variety of challenging environments led to the rapid development of the field, training and evaluating on ALE requires enormous computing power. For example, it takes almost 4 years of GPU hours with a Tesla P100 to reproduce Rainbow’s result on all 57 environments. Therefore, instead of ALE, the authors test Rainbow on less resource-intensive environments, namely classical control and MinAtar.
From an additive and an ablative study of each component of the Rainbow, the authors report results mostly consistent with the analysis by Hessel et al. (2018) in the original Rainbow paper. Each component affects performances in a different way for each environment and using all components results in the best overall performance.
The authors also perform additional experiments on some of the design decisions of Rainbow, namely the loss function, the neural network architecture, and the batch size. Experiments show that Rainbow is generally robust to varying architecture dimensions and batch sizes. Surprisingly, mean squared error (MSE) outperformed Huber loss in all environments.
Thoughts
Inclusivity is an important issue that should not be overlooked, and this paper helps mitigate one possible entry barrier to RL research. This reminds me of the recent debate on D4RL, a benchmark paper using MuJoCo submitted to ICLR 2021. Such active discussions help the RL community be mindful of inclusivity.
Read more
- ArXiv Preprint
- Twitter Thread by Pablo Samuel Castro (Second Author)
- Blog Post by Pablo Samuel Castro (Second Author)
- GitHub Repository
- SlidesLive Video from NeurIPS 2020 Deep RL Workshop
More News
Here is some more exciting news in RL:
Acme (Library)
Research Framework for Distributed Reinforcement Learning with TensorFlow or JAX
coax (Library)
Plug-n-Play Reinforcement Learning in Python with OpenAI Gym and JAX
Reverb (Library)
Reverb is a data storage and transport system designed to be used for experience replay in distributed RL algorithms.
EEML2020 RL Tutorial
This Jupyter notebook introduces important RL algorithms up to DQN using Acme, Haiku, JAX, and dm_env.
DQN Zoo
A collection of reference implementations of DQN-based agents (Rainbow, IQN) using JAX, Haiku, and RLax.
Control Meets Learning Virtual Seminar
A new seminar series focused on the intersection of control theory and machine learning.
ICML2020 Tutorial on Model-Based Methods in Reinforcement Learning
A 4-hour overview of model-based RL.