RL Weekly 44: Reinforcement Learning with Videos and Automatic Data Augmentation
Published
Dear readers,
Last week, I received a couple of emails indicating that one issue every two weeks would work best for them. A big thank you to those who sent feedback! I am experimenting with the bi-weekly issues, and I hope to make a decision in January. If you have any suggestions or feedback, please email me!
In this issue, we look at using human demonstrations to help robots learn and automatically selecting data augmentation methods for RL.
- Ryan
Reinforcement Learning with Videos: Combining Offline Observations with Interaction
Karl Schmeckpeper1, Oleh Rybkin1, Kostas Daniilidis1, Sergey Levine2, Chelsea Finn3
1University of Pennsylvania 2University of California, Berkeley 3Stanford University
Summary
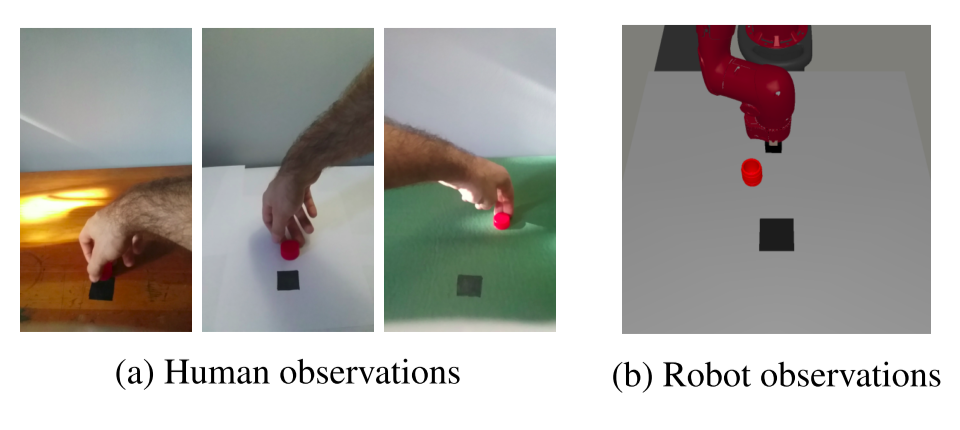
Reinforcement learning requires a large amount of interaction data. However, it is difficult to get such an amount in real-world applications such as robotics. The authors propose using demonstration videos of humans performing the same task to train agents and show that this allows for greater sample efficiency.
To learn with off-policy RL algorithms such as Soft Actor-Critic (SAC), the agent keeps a buffer of past interactions. These interactions contain the previous state, selected action, next state, and the received reward. However, videos of human demonstrations only show the states. Therefore, to use these videos, the agent must synthetically generate actions and rewards from pairs of previous and next states.
For actions, an inverse model is trained. Given the encodings of the previous and next state from real interaction data, the model is trained to predict the action selected for this interaction. This model is then used to generate artificial actions for videos. For rewards, no learning is done: for each video, a large reward is given for the terminal state, and a small reward is given for non-terminal states.
For a good inverse model (and training), the state encoder must be able to encode both interaction data and video data. The encoder is trained adversarially: a discriminator model is trained to discern interaction data and video data, and the encoder is trained to fool the discriminator model.
The authors evaluate their model (RL with Videos; RLV) with simulated robot environments using SAC. On experiments with demonstration videos of other agents, RLV solves tasks faster than other approaches (ILPO, BCO, SAC), and with videos of human demonstrations, RLV learns faster than SAC or SAC with an exploration algorithm (Random Network Distillation).
Thoughts
It is impressive that real-world demonstrations can be used when the visual domain shift is so apparent!
Read more
Automatic Data Augmentation for Generalization in Deep Reinforcement Learning
Roberta Raileanu1, Max Goldstein1, Denis Yarats12, Ilya Kostrikov1, Rob Fergus1
1New York University 2Facebook AI Research
Summary
Generalization is an important challenge in RL: we want agents that can understand environment dynamics and make decisions, not agents that memorize specific trajectories. One such way to improve generalization is data augmentation. Data augmentation is already widely used in other machine learning fields such as computer vision. However, it is not as prevalent in RL as many popular environments are not invariant to common augmentation methods such as rotations or flips.
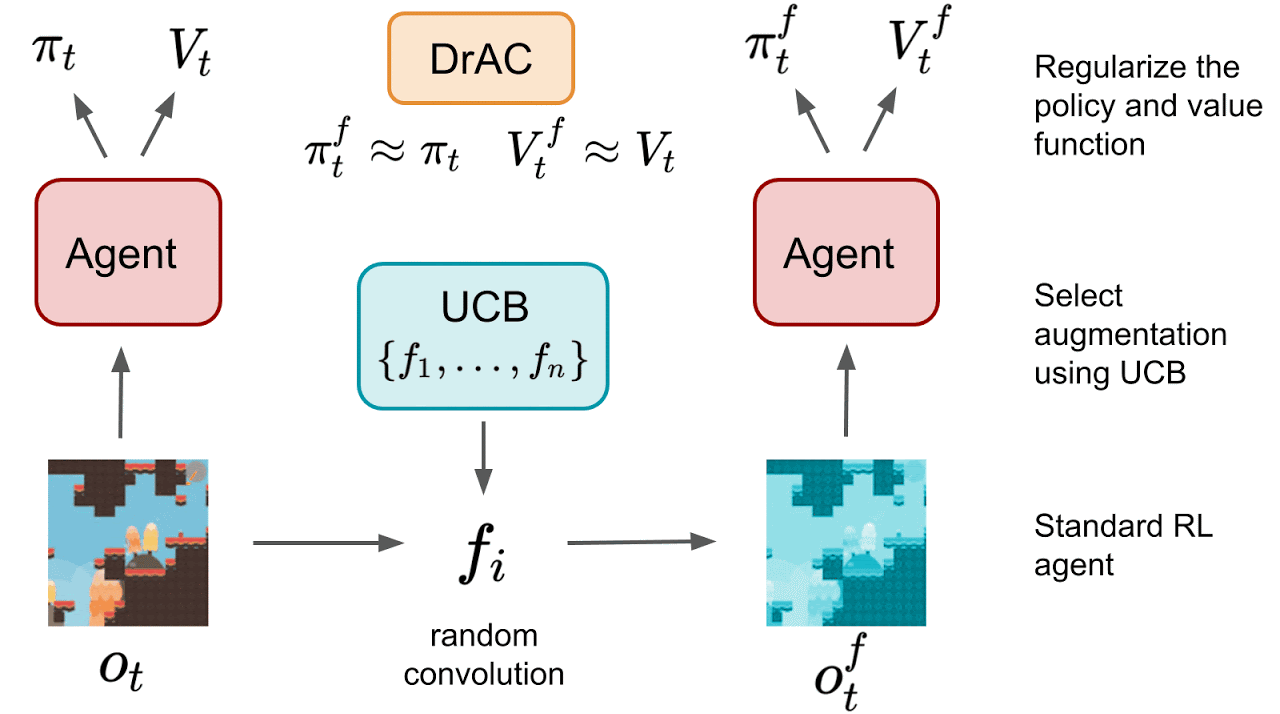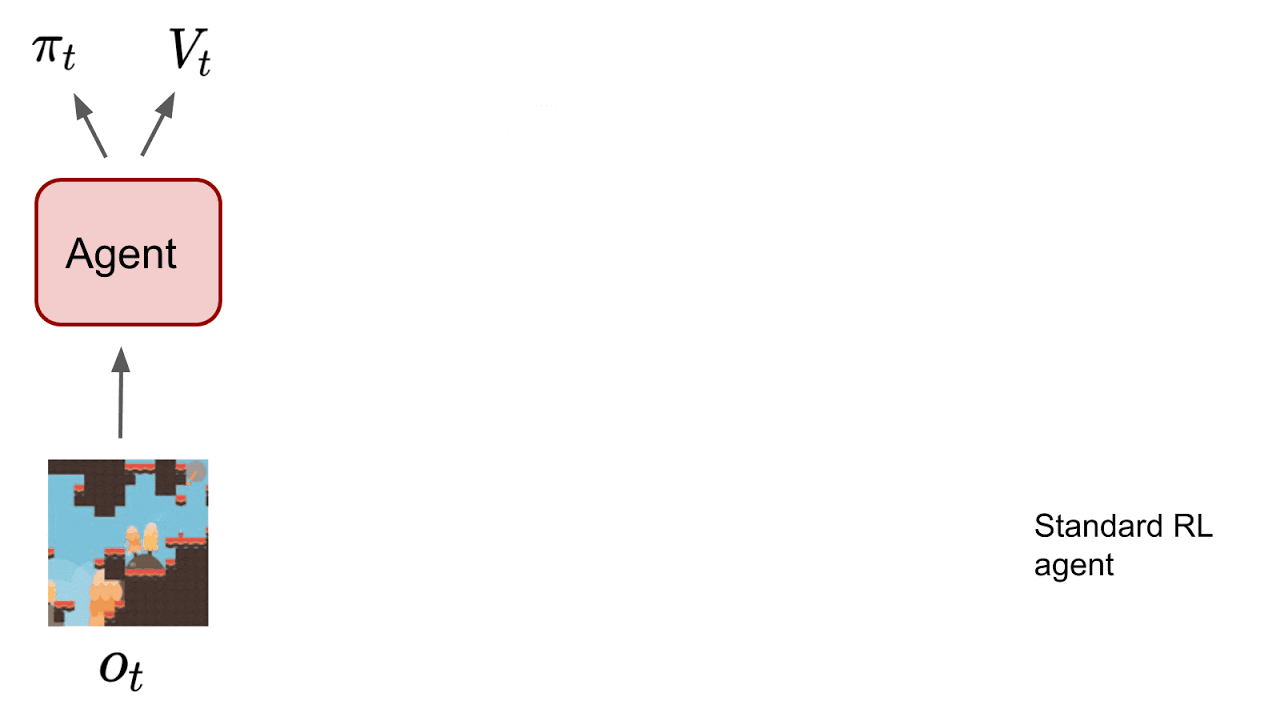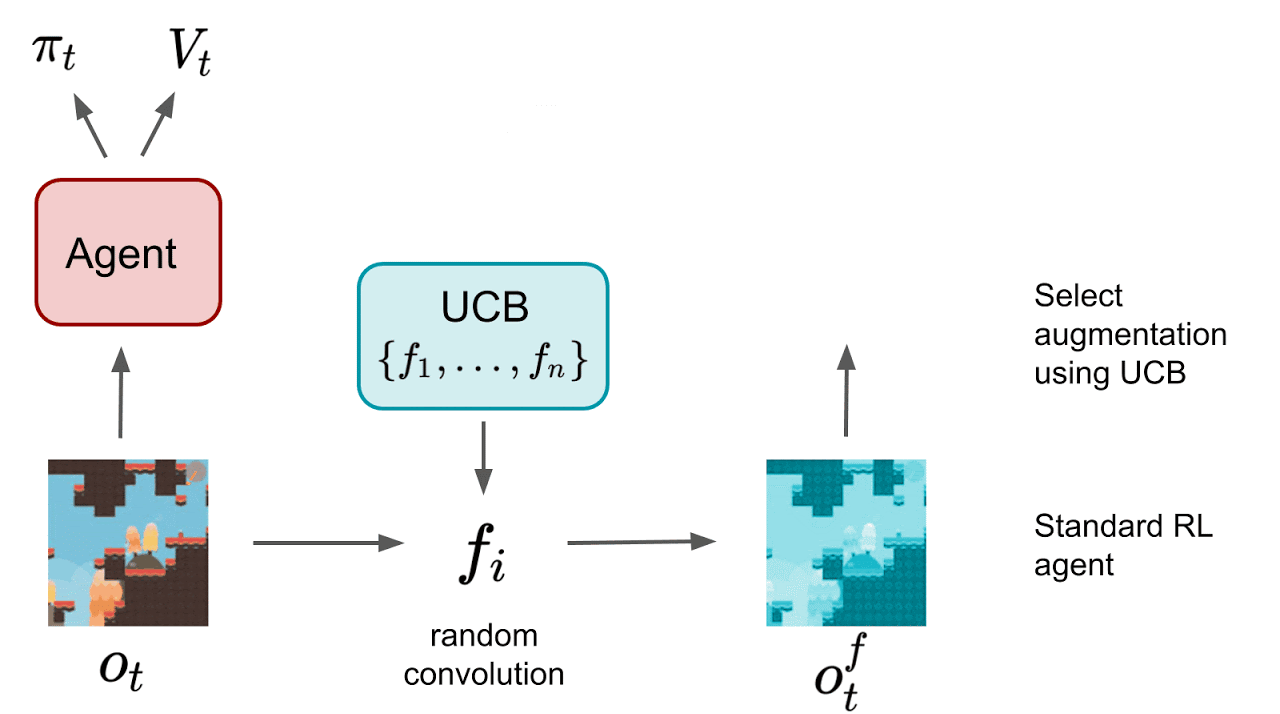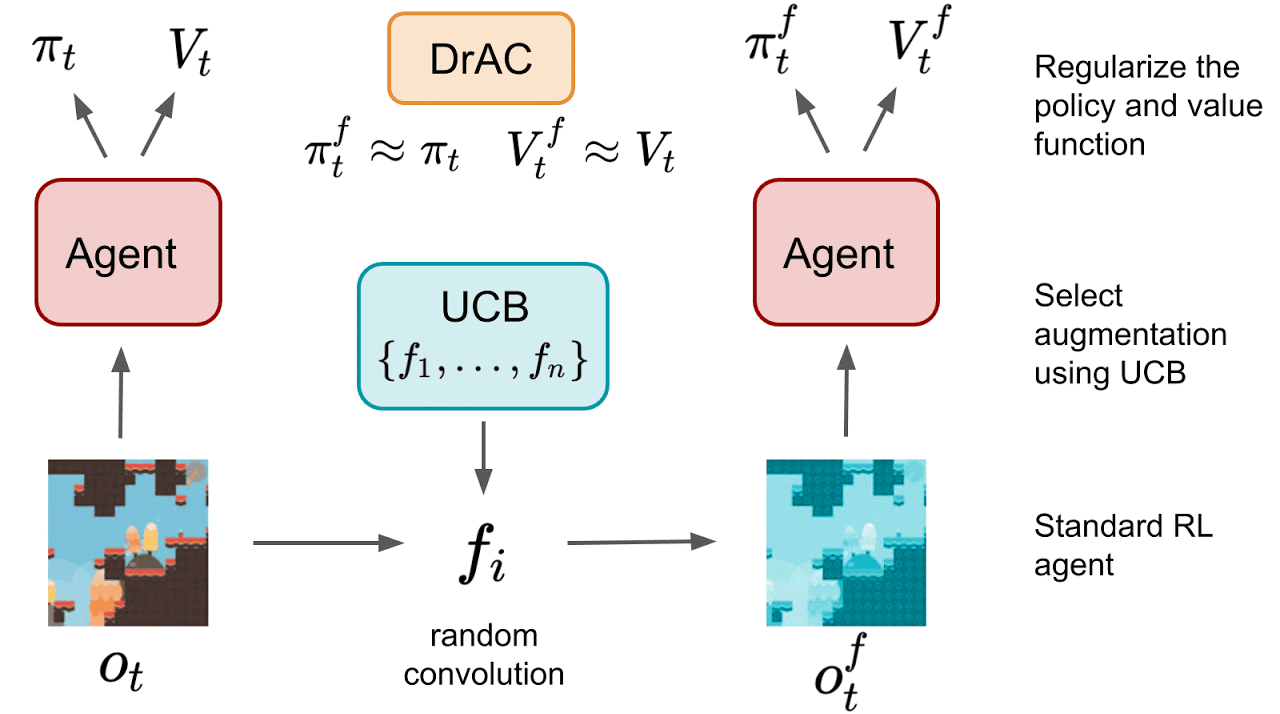
To ensure that data augmentation techniques preserve the agent’s interpretation of the state, the authors introduce regularization terms for both the policy and value functions. The policy function is regularized to encourage that the output action distribution is the same when given the augmented state or the original state. Similarly, the value function is regularized to encourage the same value estimates when given augmented or original states.
The authors also test three approaches for automatically finding an appropriate augmentation. The first two methods select augmentation technique, either through Upper Confidence Bound (UCB-DrAC) or meta-learning (RL2-DrAC). The authors also experiment with using meta-learning to select the weights of a convolutional network that serves as an augmentation technique (Meta-DrAC).
DrAC is tested on the Procgen Benchmark with eight possible transformations: crop, grayscale, cutout, cutout-color, flip, rotate, random convolution, and color-jitter. UCB-DrAC outperforms the baseline PPO, as well as the two other approaches (RL2-DrAC, Meta-DrAC). When compared to the best result out of all eight transformation methods, UCB-DrAC also attains similar performance, showing that it can indeed find the best data augmentation method.
Thoughts
Although meta-learning methods showed worse results than UCB in all scenarios, I am thankful that the authors included them in the paper. Negative results in papers can bring new insights to the reader.
Read more
More News
Here is some more exciting news in RL:
Understanding RL Vision
A distill.pub article investigating interpretability techniques.
Discovering Reinforcement Learning Algorithms (Paper)
A new meta-learning approach for discovering new RL algorithms from data.
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems (Paper)
A 43-page paper reviewing offline RL with its challenges and research directions.
SoftGym (Benchmark)
A new set of benchmarks that simulate manipulation of deformable objects.
RL Unplugged: Benchmarks for Offline RL (Benchmark)
A set of benchmarks for offline RL with datasets from Atari, DeepMind Locomotion, DeepMind Control Suite, and Realworld RL.
dm_hard_eight: DeepMind Hard Eight Task Suite (Benchmark)
A set of benchmarks with hard exploration problems used to verify R2D3.
Reinforcement Learning - Industrial Applications with Intelligent Agents (Book)
A new book summarizing RL algorithms with case studies.
RL Virtual School
ANITI’s first RL virtual school, to be held from late March to early April.