RL Weekly 39: Intrinsic Motivation for Cooperation and Amortized Q-Learning
Published
Dear readers,
RL Weekly is back! Sorry for the hiatus, and thank you for your patience. I have been occupied trying to get a summer internship or research opportunity. That said, please feel free to suggest an opportunity!
This issue has materials of about two months, so there is a lot to enjoy! In this issue, we look at using intrinsic rewards to encourage cooperation in two-agent MDP. We also look at replacing maximization in Q-learning over all actions with a neural network to use Q-learning in environments with big action spaces.
I would love to hear your feedback! If you have anything to say, please email me.
- Ryan
Intrinsic Motivation for Encouraging Synergistic Behavior

What it says
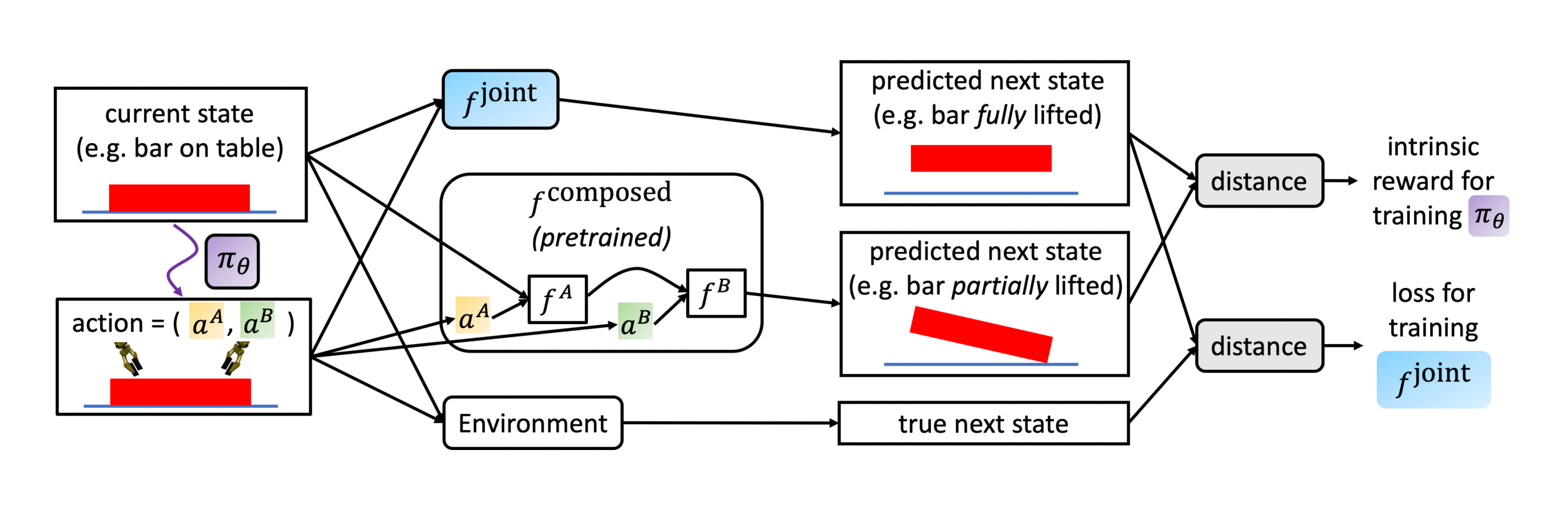
Consider a setting where there are two agents that must cooperate synergistically to complete a certain task. For example, consider a goal of opening a bottle on a table by rotating a bottle cap, where each agent controls one robot arm. To complete this goal, one agent must hold the bottle while the other rotates the cap. The authors propose a way of using intrinsic rewards to encourage the two agents to cooperate.
The insight comes from the fact that if the task requires both agents to cooperatively act, then a single agent would be unable to complete the task. Then, consider training a forward model of a single agent that predicts the next state given an action, where the other agent does nothing. This pre-trained forward model will predict the next state if the two agents are working independently, but it will fail to predict the next state when the two agents cooperate, since the forward model could have never seen such maneuver. Thus, the intrinsic reward is computed by the distance between the predicted next state and the true next state. The authors also propose replacing the true next state with a prediction from training a joint forward model, which allows for the computation of analytical gradients.
In six different synergistic tasks, the authors show that agents trained with their intrinsic reward perform better than baselines, which were trained in just extrinsic reward or with extrinsic reward and surprise-based intrinsic reward. The authors also show that using a joint forward model increases the performance of the agent, and that it is due to the analytical gradients.
Read more
Q-Learning in enormous action spaces via amortized approximate maximization

What it says
Amortization is a technique of replacing an expensive operation with a forward pass of some parametric model. In Q-learning, this expensive operation is maximization. To choose the greedy action, the agent must find the maximum of all the action values. For small discrete action spaces, this is not a concern, but for large action spaces, it becomes infeasible. Thus, the authors suggest using a neural network to make the maximization more efficient by giving the agent a small subset of actions to maximize over. This “proposal” network models a distribution, and the subset of actions of size N is obtained by sampling from this distribution N times.
The authors suggest adding stochasticity to action selection. Instead of using the proposal network to choose every element in the subset of actions, some actions are sampled uniformly from the total action space. This not only allows for additional exploration, but also guarantees that every action has a nonzero probability.
In various experiments, the authors show that Amortized Q-Learning (AQL) performs competitively against D3PG, QT-Opt, and IMPALA on tasks with large discrete action space or on discretized continuous control tasks.
Read more
Here is some more exciting news in RL:
Dopamine and temporal difference learning: A fruitful relationship between neuroscience and AI
Researchers at DeepMind, UCL, and Harvard found connections between distributional RL and dopamine neurons from experiments with mice.
Bug in BipedalWalkerHardcore
chozabu (GitHub handle) found that BipedalWalkerHardcore-v2 in the OpenAI Gym had a bug in the observation which made the environment even harder. The LIDAR was tracing through objects and returning the furthest hit result instead of the closest.
Reinforcement Learning Assembly
RL Assembly is Ape-X and R2D2 implementations from Facebook AI.
Curriculum for Reinforcement Learning
Lilian Weng published a blog post summarizing various methods to use a notion of a curriculum to train RL models effectively.
Connect X
Connect X is a generalization of Connect Four hosted by Kaggle as a new type of competition. Your submission will play against a computer or other users’ submissions instead of being evaluated by a metric.
My Top 10 Deep RL Papers of 2019
Robert Tjarko Lange summarized 10 research papers that he found to be most interesting.
RL Open Source Fest
RL Open Source Fest is an online program by Microsoft Research where accepted students will work on a research programming project over the summer using Vowpal Wabbit.
Jericho
Jericho is a new environment from Microsoft Research to train RL agents in text-based interactive fiction games such as Zork.
Lyceum: An efficient and scalable ecosystem for robot learning
Lyceum is a new framework from the University of Washington Seattle that allows developing RL and MPC algorithms for robot learning using Julia and MuJoCo.
RLAX
RLAX is a JAX library from DeepMind that contains useful operations and functions to develop RL agents.
Open-sourcing Polygames, a new framework for training AI bots through self-play
Polygames is a new framework from Facebook AI for training agents through self-play.