RL Weekly 27: Diverse Trajectory-conditioned Self Imitation Learning and Environment Probing Interaction Policies
Published
Diverse Trajectory-conditioned Self Imitation Learning
What it says
Self-imitation learning is a method of imitating one’s own trajectories to improve learning efficiency. In past work, only the good trajectories were selected, but this could mislead the agent to settle for local optima, as high return in the short term does not conclude high return in the long term.
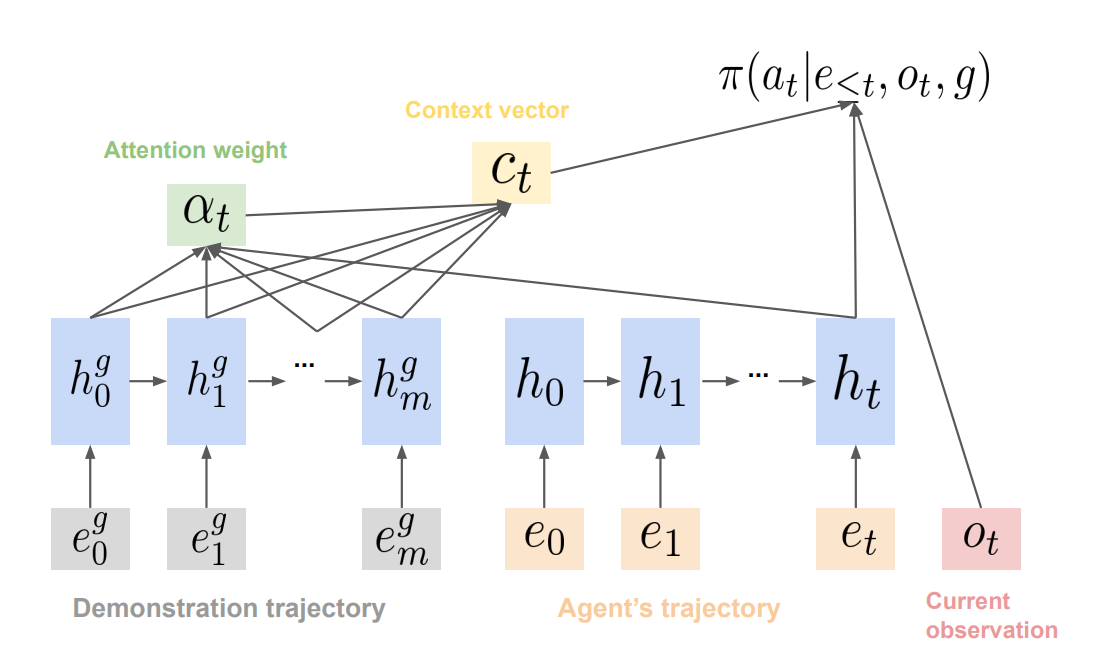
Thus, the authors propose using a buffer to store all past trajectories, and imitate any trajectory in this buffer, “exploiting the past experience in diverse directions.” Each element in the buffer contains the trajectory, the embedding of the final state of the trajectory, and the visitation count of this embedded final state (Section 3.2). It is assumed that such embedding is provided (Section 3.1).
For every timestep, the embedded final state is computed. If such embedding has never been seen, a new element is added to the buffer. If there is another element in the buffer with the same embedding, the visitation count is incremented, and the “better” trajectory leading to the embedded final state is kept in the buffer.
To learn the policy, the demonstration trajectories are sampled stochastically, with the weights being inverse proportional to square root of visitation count. Thus, trajectories with less-visited final states are prioritized for imitation. (Section 3.3).
The trajectory-conditioned policy is represented by an RNN with attention mechanism (Section 3.4), where given a demonstration trajectory and current partial trajectory, the policy predicts the next action to imitate the demonstration. This is trained with RL through policy gradients by defining imitation rewards, and it is also trained with supervised learning by using same trajectories for both demonstration and current policy and predicting the action selected in the demonstration.
This algorithm DT-SIL is tested against PPO, PPO with count-based exploration bonus, and PPO with Self-Imitation Learning. DT-SIL shows superior performance in various domains, and achieves the score of 29278 in Atari Montezuma’s Revenge.
Read more
Environment Probing Interaction Policies
What it says
Although RL has achieved great success in many fields, it has the problem of overfitting to the environment, failing to generalize to the new environment. One way to mitigate this issue is by training the policy in multiple environments, but this often leads to a conservative policy that does not exploit environment dynamics.
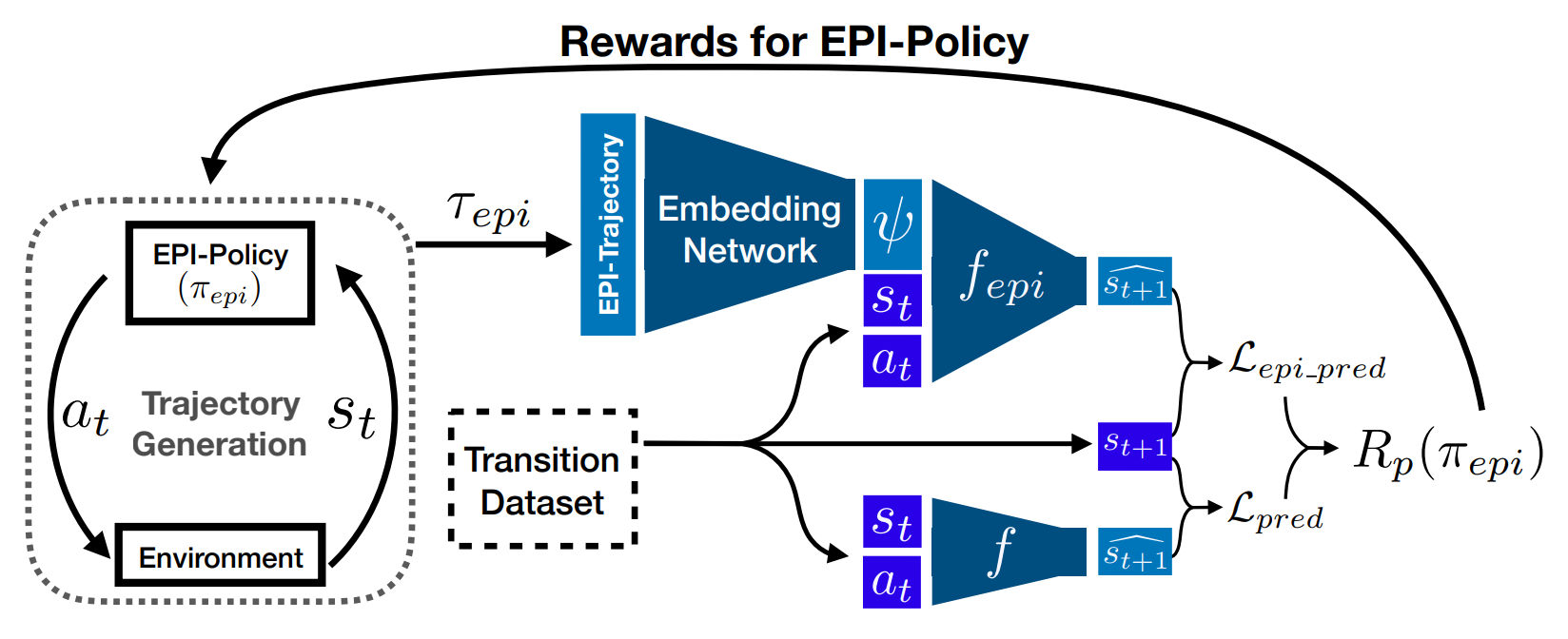
Another way to mitigate this issue is to design a policy that adapts to the environment. Since identifying the environment is infeasible and challenging, the authors propose “Environment Probing Interaction” (EPI), where the agent also learns an EPI policy separate from the task-specific policy.
The EPI policy is trained using two next-state-prediction networks (Figure 1). One is a simple prediction network, and another is a network that is given extra information from the trajectory embedding network that is also being trained. EPI policy is rewarded by how much better the prediction of the latter network is, so it is encouraged to generate trajectories that can be embedded to gain useful information about the environment. (Section 4.1).
The EPI policy is tested n two MuJoCo environments: Striker and Hopper. The environment is altered by changing various physical properties such as the body mass, the joint dampings, and the friction coefficient. The EPI policy shows performance superior to the simple MLP policy and “invariant policy” (Section 5).
Read more
- Environment Probing Interaction Policies (ArXiv Preprint)
- Environment Probing Interaction Policies (OpenReview)
- Environment Probing Interaction Policies (GitHub Repo)
One-line introductions to more exciting news in RL this week:
- Environments
- Psycholab: Create a multi-agent gridworld game with an ASCII representation!
- CuLE: Run thousands of Atari environments simultaneously with GPU’s superior parallelization ability!
- Arena: A multi-agent RL research tool supporting popular environments such as StarCraft II, Pommerman, VizDoom, and Soccer!
- Competitions
- The Unity Obstacle Tower Challenge has come to an end! Here are two writeups from the participants:
- MineRL The whitepaper for the MineRL NeurIPS competition was released!
- Algorithms & Theories
- A3C TP: Predicting closeness to episode termination while training A3C can boost its performance!
- Hindsight TRPO: Use hindsight with TRPO to outperform Hindsight Policy Gradient (HPG) in various environments!
- DS-VIC: Identify decision states in a goal-independent manner!
- Miscellaneous
- Coursera Specialization There is a new Coursera specialization on RL from University of Alberta!