RL Weekly 22: Unsupervised Learning for Atari, Model-based Policy Optimization, and Adaptive-TD
Published
ST-DIM: Unsupervised State Representation Learning in Atari
What it says
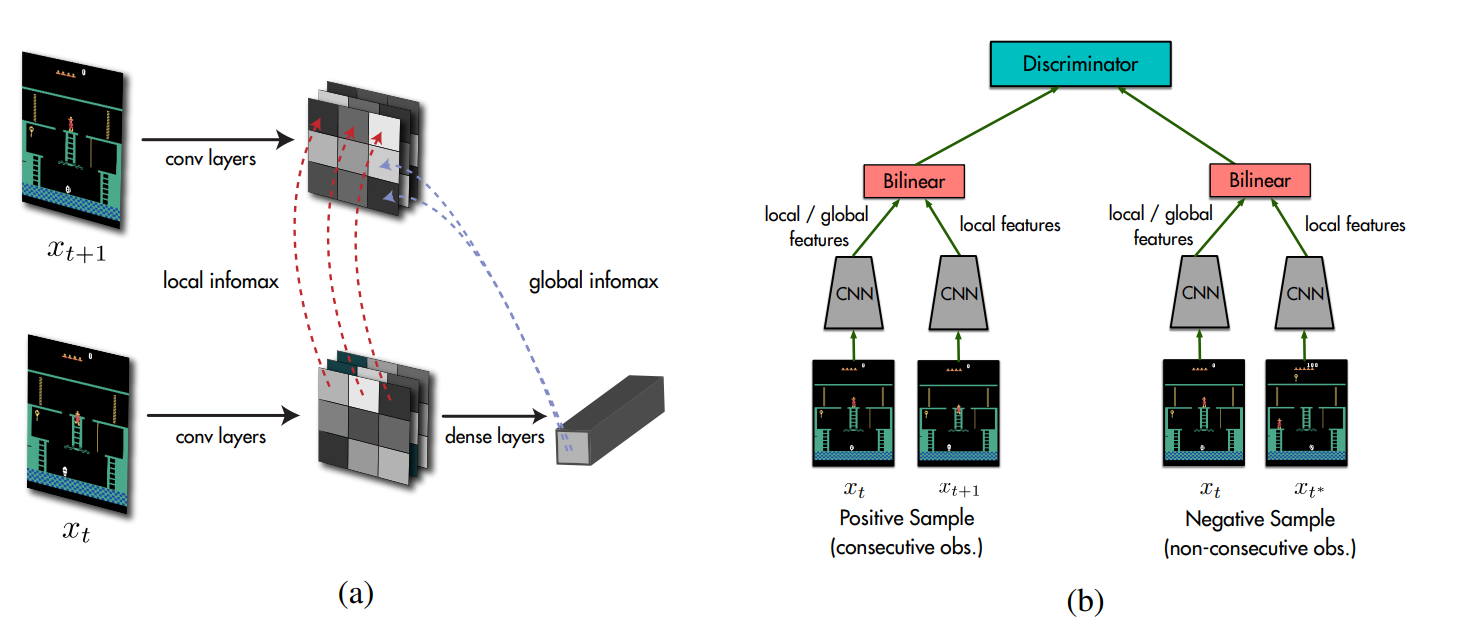
Representation learning is an important field of deep learning that can allow agents to perform a single task well or transfer knowledge between multiple tasks. The authors propose Spatiotemporal Deep Infomax (ST-DIM), a new unsupervised representation learning method that extends Deep Infomax (DIM) across spatial and temporal axes (Section 3).
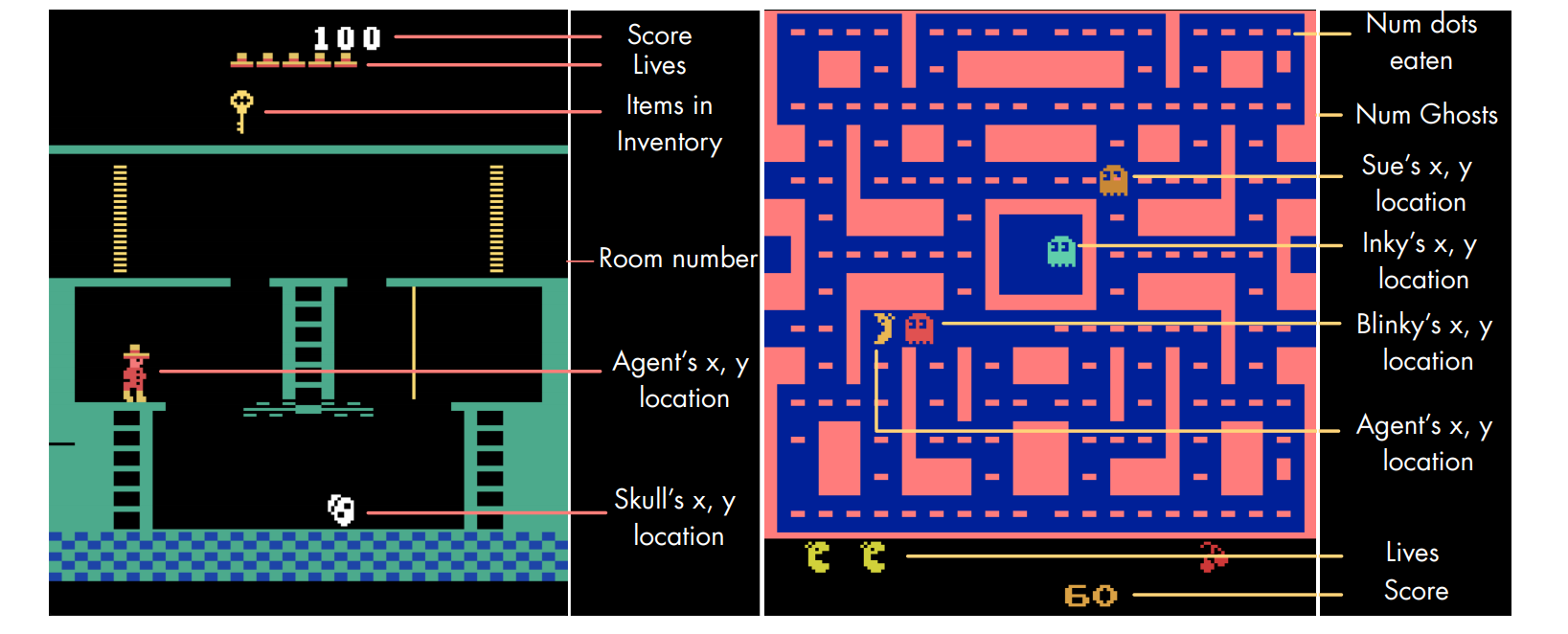
The authors also propose Atari Annotated RAM Interface (AARI), a new benchmark for state representation in RL. Although the Arcade Learning Environment (ALE) does not directly expose any state information (agent location, object location, number of lives, etc.), it is possible to extract them from the RAM state. The authors successfully extracted state information from 22 Atari games (Section 4). A trained representation can be evaluated with AARI by training linear classifiers predicting each state variable.
The authors compare ST-DIM with other baseline representation learning methods. These methods include random CNN encoder, variational autoencoder (VAE), next-step pixel prediction model, and Contrastive Predictive Coding (CPC). These representations are trained either from data collected by random agents or from a pretrained PPO agent. The experiment shows that in both representations, ST-DIM achieves better F1 score than baseline methods in most Atari games (Table 2, 3, 6, 7).
Read more
External resources
- Learning deep representations by mutual information estimation and maximization (ArXiv Preprint): Deep Infomax (DIM)
When to Trust Your Model: Model-Based Policy Optimization
What it says
Although the idea of model-based RL is attractive due to high sample efficiency, it requires an accurate model for the agent to learn a good policy, since even small model error is compounded while simulating trajectories. Unfortunately, when the agent must learn the model while interacting with the environment, the accuracy of the model cannot be guaranteed. Thus, model-based RL methods where the model is learned often perform worse than model-free RL methods.
Despite the uncertainty in the model, it is possible to provide performance guarantees for model-based RL (Theorem 4.1). However, if the effective horizon is big, the guarantee only holds when the return of the policy in the model improves immensely. Thus, instead of “pure” model-based rollouts, the authors choose “branched rollout,” where a k-step model-based rollout is generated from the start under the previous policy’s state distribution (Section 4.2).
To test MBPO, Soft Actor Critic (SAC) is used with an ensemble of probabilistic neural network that acts as a model (Section 5). On MuJoCo tasks, MBPO achieves better performance compared to the model-free counterpart SAC and a standard model-free baseline PPO. It also achieves better performance than recent model-based methods such as PETS, STEVE, and SLBO (Section 6.1).
Read more
- When to Trust Your Model: Model-Based Policy Optimization (ArXiv Preprint)
- When to Trust Your Model: Model-Based Policy Optimization (Website)
- ICML2019 Workshop on Model-Based Reasoning: Model-Based Policy Optimization (YouTube Video)
External resources
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor (ArXiv Preprint)
- Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models (ArXiv Preprint)
Adaptive Temporal-Difference Learning for Policy Evaluation with Per-State Uncertainty Estimates
What it says
The bias-variance tradeoff of Monte Carlo (MC) methods and Temporal Difference (TD) methods is a well-studied topic in RL. When compared, MC is typically characterized as low-bias, high-variance, and TD as high-bias, low-variance. Monte Carlo method suffers from high variance because it generates entire trajectories, and Temporal Difference method suffers from high bias because it bootstraps values, allowing errors to propagate (known as the leakage problem). There is no clear winner between these methods, certain methods suite certain tasks better.
The authors propose Adaptive-TD, an algorithm to combine MC and TD. As the name suggests, the main driver is TD, but the algorithm resorts to MC when it suspects that the estimate is poor (Section 3.1). The authors use an ensemble of MC networks that provide value estimates and compute a MC “predictive confidence interval” from these estimates. If the TD estimate does not correspond to any sample in the MC distribution, we can suspect that the estimate is poor, so we resort to using the MC estimate (Section 3.2).
The authors compare Adaptive-TD with TD and MC on a simple MDP, Labyrinth-2D, and Atari environments. Whereas TD and MC show great performance on some tasks but fail on others, Adaptive-TD is shown to be robust in all tasks, “[mimicking] the behavior of the best-performing one.” (Section 4-5).
Read more