RL Weekly 21: The interplay between Experience Replay and Model-based RL
Published
Search on the Replay Buffer
What it says
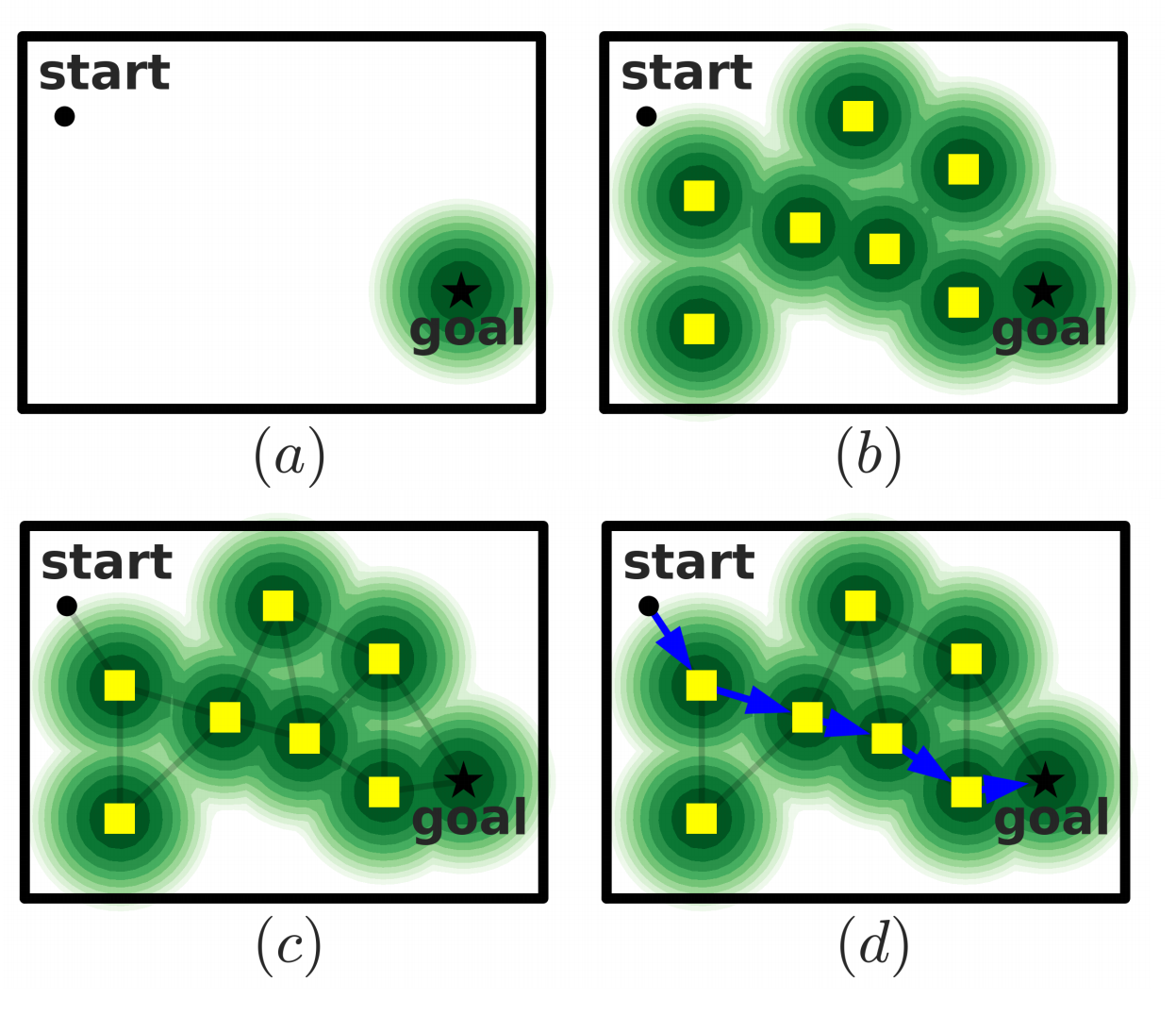
Goal-conditioned RL studies tasks where there exists a “goal”, and the epsiode ends when the agent is sufficiently close to it (Section 2.2). Many attempts have used reward shaping or demonstrations to guide the agent. Instead, the authors propose reducing this goal-reaching problem into several easier goal-reaching tasks.
To decompose the problem, the authors build a directed, weighted graph, where each node is an observation from the replay buffer, and the edges are the predicted “distance” between two observations (Section 2.3). Then, by using Dijkstra’s algorithm (Appendix A),it is possible to find the shortest path to the goal, allowing the agent to plan its trajectory.
The authors discuss different distance estimates, using distributional RL (Section 3.1) or value function ensembles (Section 3.2). Experiments show that these enhancements are crucial for the performance of SoRB (Section 5.4).
In a visual navigation task, SoRB outperforms Hindsight Experience Replay (HER), C51, Semi-parametric Topological Memory (SPTM), and Value Iteration Networks (VIN) (Section 5.2, 5.3). It is also shown to generalize well to new navigation environments (Section 5.5).
Read more
- Search on the Replay Buffer: Bridging Planning and Reinforcement Learning (ArXiv Preprint)
- Search on the Replay Buffer: Bridging Planning and Reinforcement Learning (Google Colab Notebook)
External Resources
Learning Powerful Policies by Using Consistent Dynamics Model
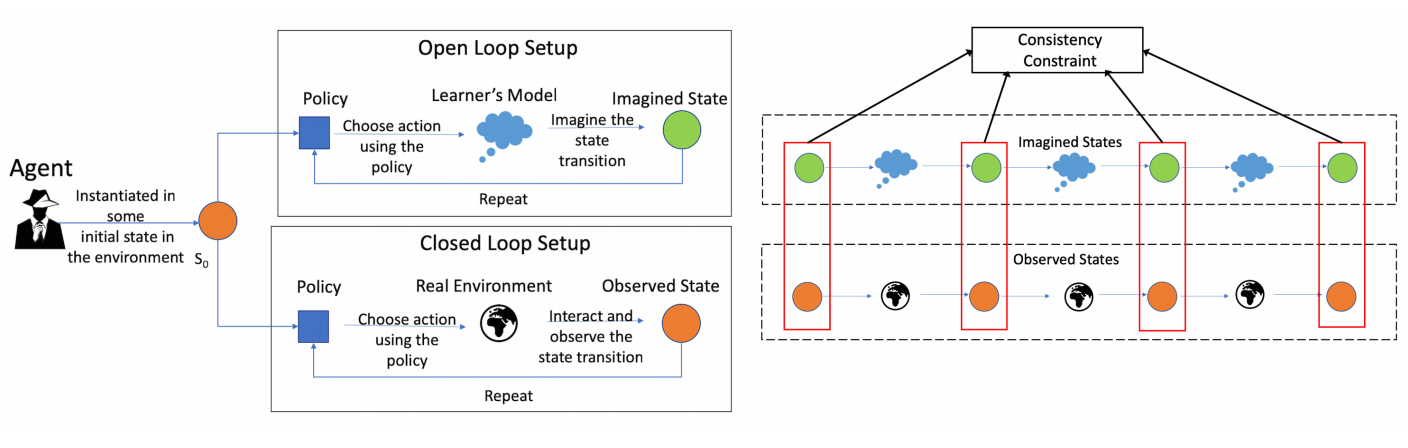
What it says
Model-based RL relies on having a good model that sufficiently represents the real environment, since the error of the model is compounded as the model is unrolled for multiple steps. Thus, a multi-step dynamics model could deviate greatly from the real environment. To fix this problem, the authors propose an auxilary loss to match the imagined state from the model with the observed state from the real environment (Section 3.1). Compared to the baseline algorithms Mb-Mf and A2C, the Consistent Dynamics model shows superior performance in various Atari and MuJoCo tasks (Section 6).
Read more
External Resources
- Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning (ArXiv Preprint): Introduces Mb-Mf
When to use Parametric Models?

What it says
Model-based and replay-based agents have different computational properties. Parametric models typically require more computations than sampling from a replay buffer, but parametric models can achieve good accuracy with a finite memory requirement, whereas for replay memory past experiences are forgotten (Section 2.1). However, they also share similarities. Notably, with a perfect model, the experience generated from it will be indistinguishable from that from the real environment, so it has the same effect as experience replay. (Section 2.2).
Parametric models can be helpful when the agent must plan forward into the future to improve behavior, or when the agent plans backward to solve the credit assignment problem. (Section 2.3). However, these models can lead to catastrophic learning updates that are commonplace for algorithms that have the “deadly triads”: function approximation, bootstrapping, and off-policy learning (Section 3).
To compare the two approaches, the authors chose SimPLe for the model-based agent and data-efficient Rainbow DQN (Section 4.1) for the replay-based agent. Their results show that Rainbow was superior to SimPLe in 17 out of 26 Atari games (Appendix E), hinting that the hypothesized instability indeed exists in model-based agents.
Why it matters
Although replay-based agents such as Rainbow are generally categorized as model-free, the experience replay mechanism has many similarities with model-based RL. Just like how model-based agents use their models to improve the agent in between interactions with the real environment, replay-based agents also extensively use the replay buffer to train and improve the agent.
Many RL papers introduce new models for the sake of sample efficiency, but model-based RL is not a panacea that works in every environment and situation. It is important to understand both the power and the shortcoming of model-based approaches.
Read more
External Resources
- Rainbow: Combining Improvements in Deep Reinforcement Learning (ArXiv Preprint)
- Model-Based Reinforcement Learning for Atari (ArXiv Preprint): Introduces SimPLe
More exciting news in RL:
- Researchers at DeepMind show that agents with structured representations and structured policies outperform less-structured ones for physical construction tasks.
- Researchers at Google Brain, X, and UC Berkeley proposed Watch, Try, Learn (WTL), a meta-learning agent that can learn from both demonstrations and experience from interactions.
- Researchers at UC Berkeley and Intel proposed goal-GAIL, an algorithm that uses demonstrations to speed up agents on goal-conditioned tasks.
- Marlos Machado’s thesis that discuss exploration through time-based representation learning has been published online.