RL Weekly 18: Survey of Domain Randomization Techniques for Sim-to-Real Transfer, and Evaluating Deep RL with ToyBox
Published
Domain Randomization for Sim2Real Transfer
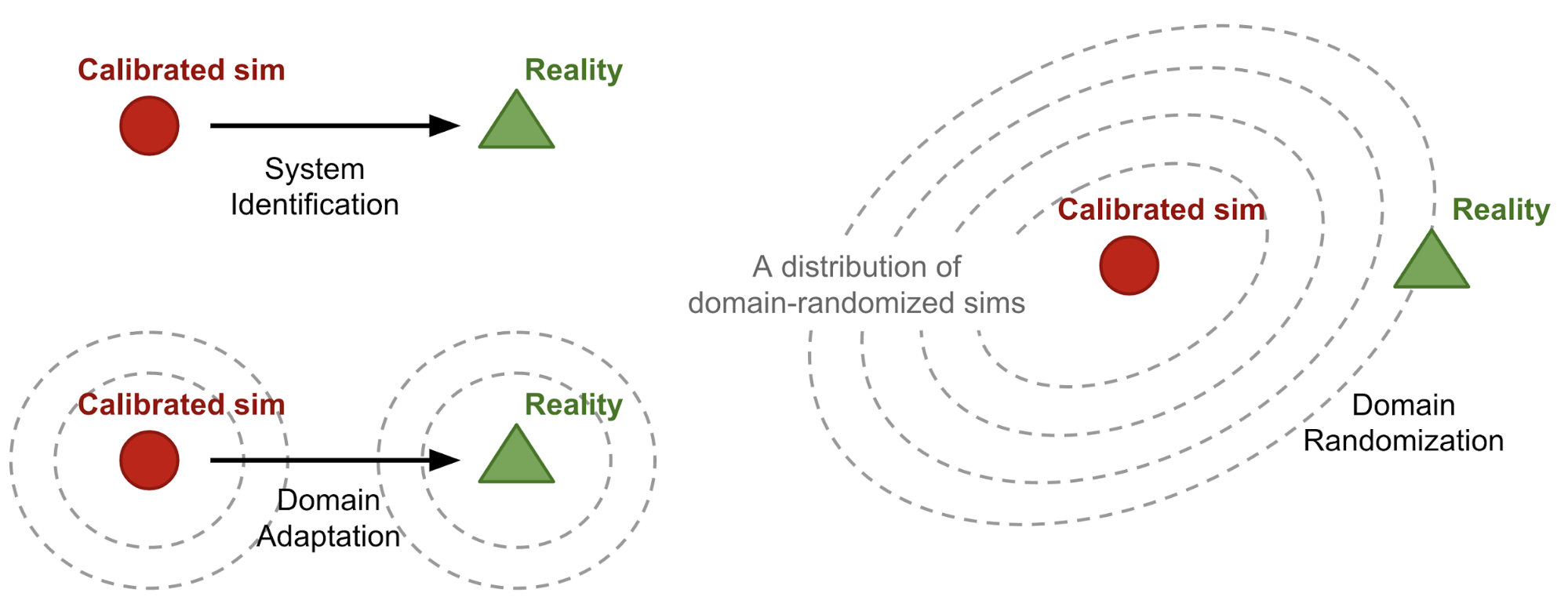
What it is
Lilian Weng, a researcher at OpenAI, wrote a blog post summarizing various Domain Randomization methods for Sim-to-Real transfer. Sim-to-Real is a method of pretraining agents in simulated environments and fine-tuning them in the real world. Domain Randomization is a technique of creating a variety of simulation environments by randomizing various properties. By training a model that performs well on all these environments, we expect that the model will also perform well on real environment.
The blog post explains the reasoning behind domain randomization, and introduces Uniform Domain Randomization and Guided Domain Randomization. Uniform Domain Randomization uniformly samples various simulation parameters to randomize the environment. Guided Domain Randomization replaces the uniform sampling and “guides” parameters so that the randomized simulated environments are realistic.
Why it matters
In many real application of RL (especially robotics), it is impractical to train the agent in the real world, as the real world cannot be sped up. This is especially the case for robotics, since robots are expensive and can wear out from numerous operations. Thus, sim-to-real techniques are essential methods to increase real-world sample efficiency. Among various sim-to-real methods, domain randomization is particularly attractive as it requires little to no real data.
Read more
External Resources
- sim2realAI: This website indexes progress of sim-to-real transfer.
ToyBox for Experimental Evaluation of Deep RL
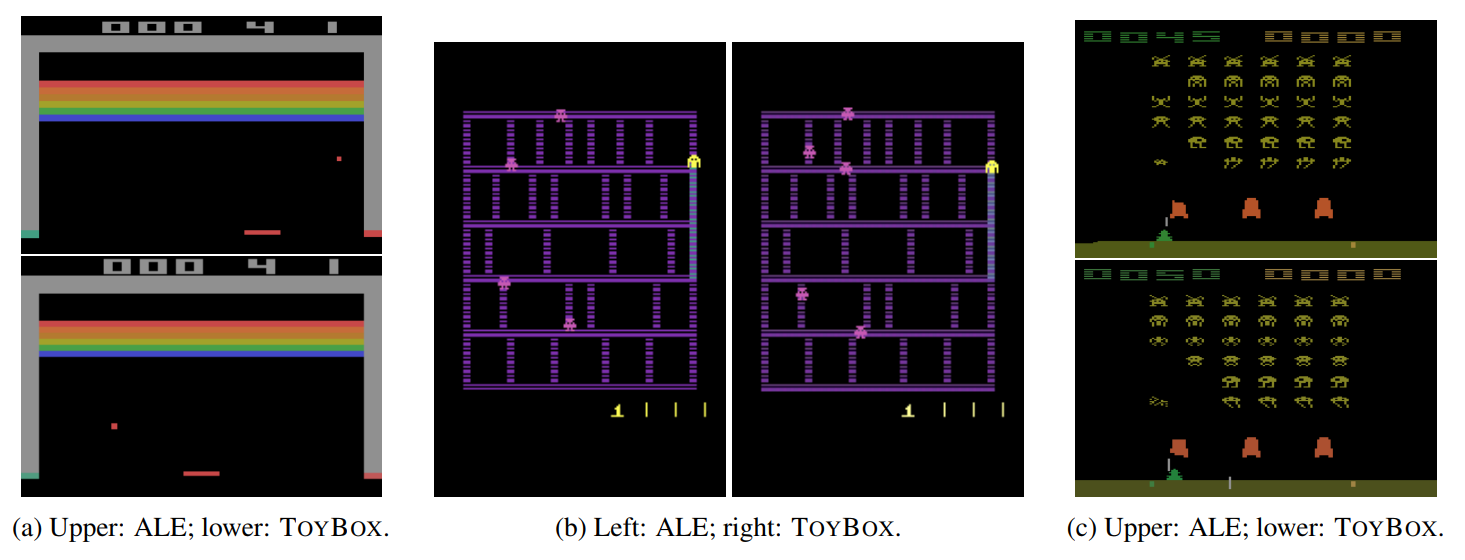
What it is & Why it matters
The Arcade Learning Environment (ALE) has been the standard test suite for evaluating deep RL algorithms. Although ALE has accelerated the development of algorithms, it is not very customizable, making in difficult to qualitatively analyze the agent’s abilities. Researchers at University of Massachusetts Amherst created ToyBox, a faster, highly customizable, drop-in replacement for Atari Breakout, Amidar, and Space Invaders.
Read more
External Resources
- Arcade Learning Environment (GitHub Repo)
- OpenAI Gym: Atari Environments
- Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents
Some more exciting news in RL:
- DeepMind published Meta-learning of Sequential Strategies, reviewing the capabilities of memory-based meta-learning.
- Week 11 of UC Berkeley’s Deep Unsupervised Learning course have been published, which reviews Representation Learning in Reinforcement Learning.
- MineRL Competition page was revealed. The competition starts on June 1st.
- Task Agnostic Reinforcement Learning Workshop was held in ICLR2019. The workshop videos are up at SlidesLive!
- Researchers at KAIST showed that dimensional-wise importance sampling weight clipping can improve the performance of PPO.