RL Weekly 19: Curious Object-Based Search Agent, Multiplicative Compositional Policies, and AutoRL
Published
COBRA: Curious Object-Based seaRch Agent
Nicholas Watters*, Loic Matthey*, Matko Bošnjak, Christopher P. Burgess, and Alexander Lerchner (DeepMind)
What it is
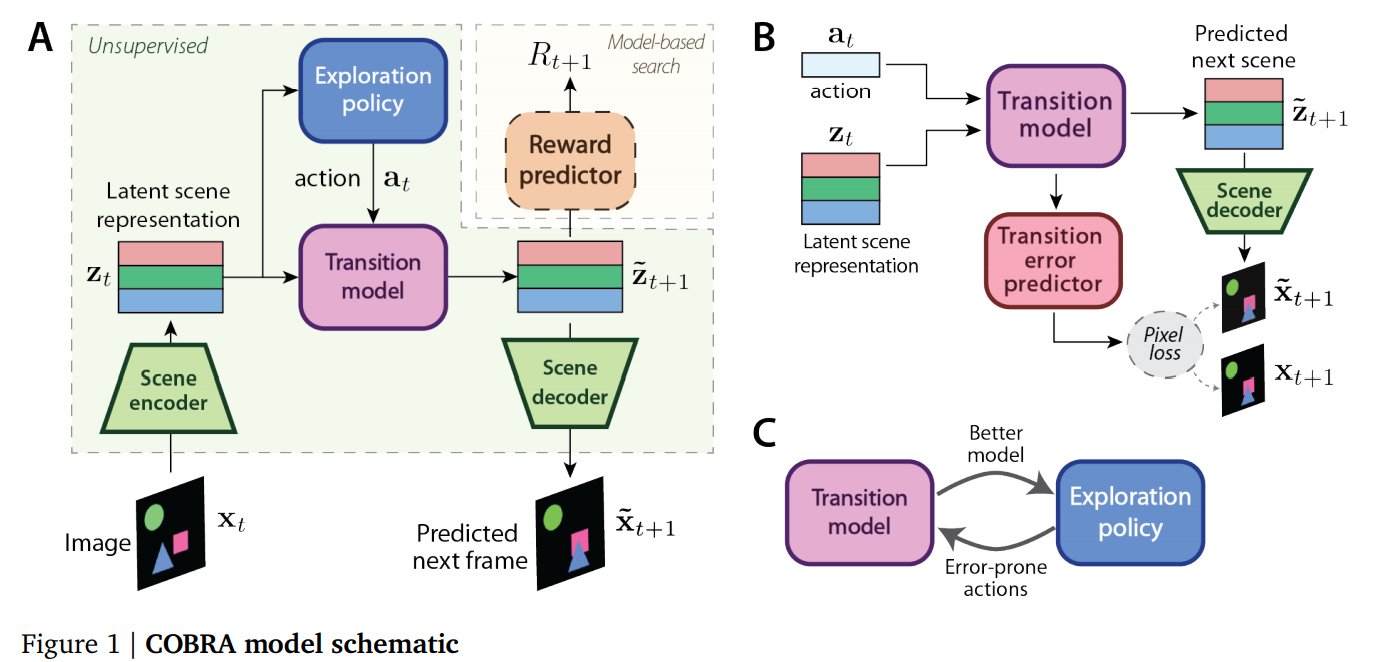
Researchers at DeepMind proposed a new agent COBRA, which incorporates object-based representation learning, curiosity-driven exploration, and model-based RL. COBRA is trained in two phases: the exploration phase and the task phase. In the exploration phase, the agent learns in a task-free, reward-free unsupervised learning setting. Then, in the task phase, the agent is trained on the task through model-based RL.
As shown in the diagram above, COBRA has four components: the vision module (scene encoder and decoder), the transition model, the exploration policy, and reward predictor. The first three are trained during the exploration phase and is frozen during the task phase. During the task phase, only the reward predictor is trained to solve a task.
MONet is used for the vision module, distributional RL for the exploration policy, and 1-step Model Predictive Control (MPC) for the reward predictor.
Why it matters
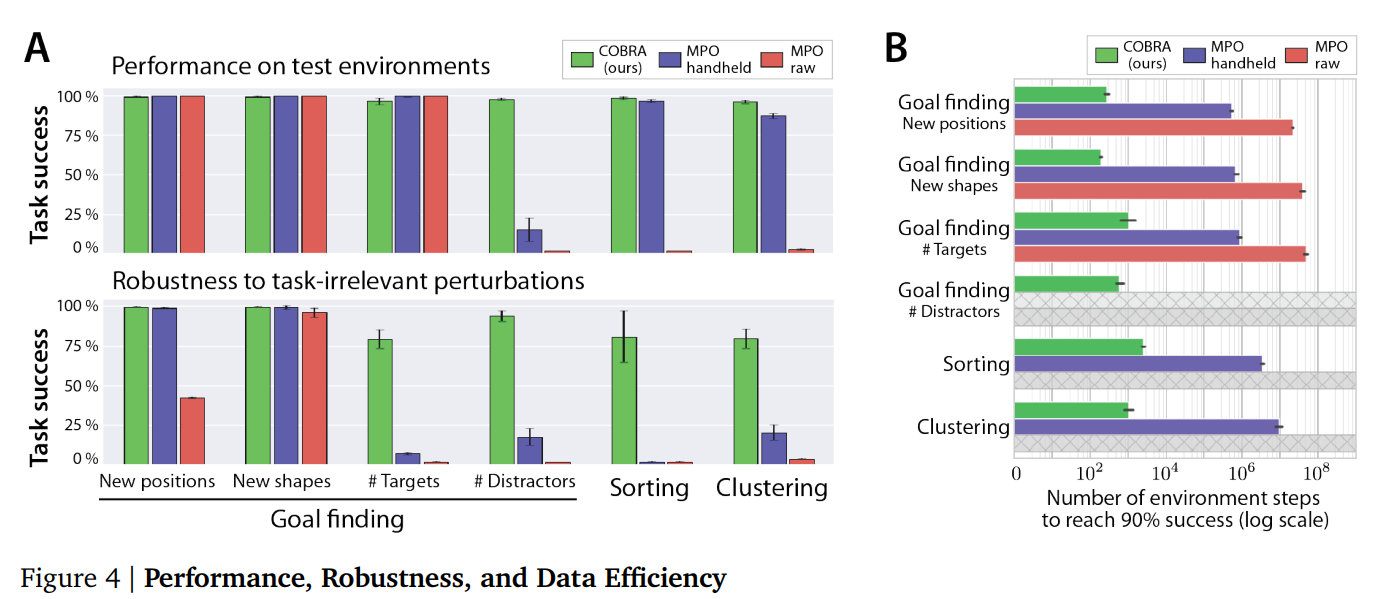
By using unsupervised learning with exploration to learn a object-based representation, COBRA can achieve both high data efficiency and robust policy. The second figure above shows its robustness and data efficiency.
We recommend the readers to read the Supplementary material section for a great detailed discussion on the training details, variations considered, and ablation studies.
Read more
- COBRA: Data-Efficient Model-Based RL through Unsupervised Object Discovery and Curiosity-Driven Exploration (ArXiv Preprint)
- COBRA agent videos (Google Drive)
External Resources
- MONet: Unsupervised Scene Decomposition and Representation (ArXiv Preprint)
- Implicit Quantile Networks for Distributional Reinforcement Learning (Arxiv Preprint)
MCP: Learning Composable Hierarchical Control with Multiplicative Compositional Policies
Xue Bin Peng, Michael Chang, Grace Zhang, Pieter Abbeel, Sergey Levine (UC Berkeley)
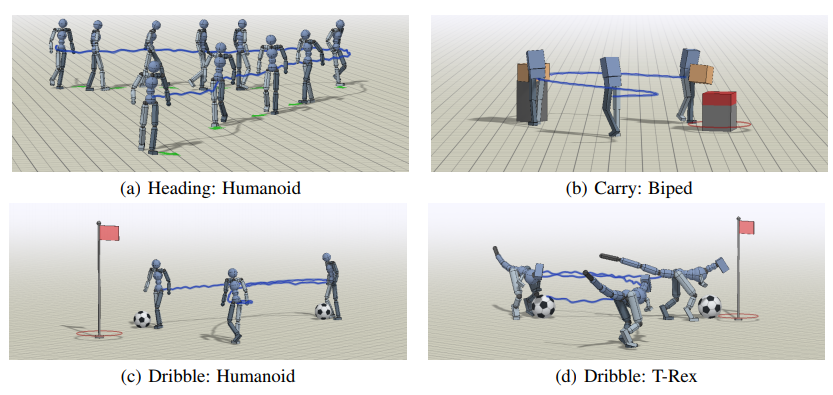
What it is & Why it matters
In a multi-task RL framework, the agent needs to learn reusable skills from “pre-training tasks” and use them in the “transfer tasks”. One way to train such agent is using a Mixture-Of-Experts (MOE) model, a Hierarchical RL method where the policy is represented as a weighted sum of a set of low-level policies (“primitives”). This “additive model” is limited to only one primitive per timestep, which could be deter the agent solving complex tasks that requires several subtasks being performed at the same time.
Researchers at UC Berkeley proposed Multiplicative Compositional Policies (MCP), a method of factoring agent’s behavior into primitives with respect to action space and enabling the agent to use multiple primitives at the same time. MCP is shown to have superior performance compared to other hierarchical models such as Option-Critic or Mixture-Of-Experts (MOE).
Read more
- MCP: Learning Composable Hierarchical Control with Multiplicative Compositional Policies (ArXiv Preprint)
- MCP: Learning Composable Hierarchical Control with Multiplicative Compositional Policies (Website)
- MCP: Multiplicative Compositional Policies (YouTube Video)
Evolving Rewards to Automate Reinforcement Learning
Aleksandra Faust, Anthony Francis, Dar Mehta (Robotics at Google)
What it is
Researchers at Google Robotics automated reward search with “AutoRL”. Proposed in their preceding work “Learning Navigation Behaviors End-to-End with AutoRL,” AutoRL is an evolutionary reward search method where it finds the reward parameters that maximizes the task objective. In other words, it “treats reward tuning as hyperparameter optimization.”
Why it matters
Reward shaping has been a difficult problem in RL. Rewards could be too sparse for the algorithms to discover, or misshaped to encourage faulty behavior. For example, for the Humanoid task, we want the agent to move by walking smoothly like a human, not rolling on the ground. AutoRL is an attempt to replace this complex hand-tuning of rewards with automated reward shaping.
Read more
- Learning Navigation Behaviors End-to-End with AutoRL (ArXiv Preprint)
- Evolving Rewards to Automate Reinforcement Learning (ArXiv Preprint)
- Evolving Rewards to Automate Reinforcement Learning (YouTube Video)
Some more exciting news in RL:
- Researchers at Google proved theoretical bounds for average-reward RL setting when there is no prior knowledge about the mixing time of the Markov chain.
- Researchers at Technion Israel Institute of Technology, Google Research, and DeepMind proposed a new Sparse Imitation Learning (Sparse-IL) algorithm that solves the text-based game Zork1.
- Researchers at Technion and DeepMind introduced Uncertainty Robust Bellman Equation (URBE) and proposed DQN-URBE, an algorithm that is robust yet not overly conservative.
- Researchers at Google Robotics used Hierarchical RL to successfully train a quadruped robot.