RL Weekly 1: Soft Actor-Critic Code Release; Text-based RL Competition; Learning with Training Wheels
Published
Soft Actor-Critic (SAC) Code Released in TensorFlow and PyTorch

What it is
Soft Actor-Critic is an off-policy model-free reinforcement learning algorithm developed by Berkeley AI Research (Haarnoja et al., 2018). The “softness” of the algorithm comes from the maximum entropy framework, where the standard reinforcement learning objective of rewards is augmented with an entropy maximization term. As shown in Policy Gradient Q-Learning (PGQL) and Soft Q-Learning (SQL), this augmented framework encourages agents to explore and yields a more robust policy.
SAC is an improvement on both PGQL and SQL. Since it is an off-policy algorithm, it has greater data efficiency compared to PGQL, an on-policy algorithm. Also, it does not require complex approximate inference procedures like Soft Q-Learning.
In various simulated environments with continuous action spaces, SAC is shown to perform better than traditional policy gradient methods such DDPG (Deep Deterministic Policy Gradient), Proximal Policy Optimization (PPO), and Twin Delayed Deep Deterministic Policy Gradients (TD3). In training a four-legged Minitaur robot in the real world, SAC was able to generalize to terrains with various obstacles despite being trained only on a flat terrain. In training a 3-finger dexterous robotic hand to manipulate a “valve,” it was able to learn in 3 hours, which less than half the reported time of PPO (7.4 hours) (Zhu et al., 2018).
Why it matters
Classic policy gradient algorithms have had some success in various simulated environments, but were unable to perform well in most real world tasks. One crucial reason this discrepancy is the lack of data available for real world tasks. Unlike simulated environments where the agent can learn from infinitely many trials, in the real world each trial wears the robot down.
Thus, a successful algorithm should have good sample complexity to minimize the number of trails needed, and also be robust to hyperparameters to minimize the need for hyperparameter tuning. The experiments show that SAC outperforms previous algorithms on both aspects, and thus it is a good step towards a practical use of reinforcement learning in the real world.
The code release in particularly welcoming to researchers outside BAIR who are interested in using reinforcement learning in real world robotic tasks. Implementing a reinforcement learning algorithm from a paper is an arduous task since 1) the paper could have missed some implementation details and 2) the test results has large variance. By releasing the official implementations of SAC, we will be able to see more exciting applications of reinforcement learning in the real world in the near future.
Read more
- Soft Actor Critic - Deep Reinforcement Learning with Real-World Robots (BAIR Blog Post)
- Soft Actor-Critic Algoritms and Applications (Project Website)
- Soft Actor-Critic Algoritms and Applications (Paper)
- softlearning (TensorFlow Implementation of SAC)
- rlkit (PyTorch Implementation of SAC)
First TextWorld Problems
What it is
TextWorld is sandbox learning reinforcement learning environment developed by Microsoft. Most other famous reinforcement learning environment are visual-based (Atari, Gym Retro) or physics-based (MuJoCo, PyBullet). In contrast, TextWorld environments are text-based, and the agents need to comprehend language descriptions to perform well. Its observations and actions are texts, as showcased by the example interaction below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
-=Kitchen=-
You have come into the most normal of all possible kitchens.
You rest your hand against the wall, but you miss the wall and fall into the
fridge. You make out a closed oven. You see a gleam over in the corner, where
you acn see a table. You see a cookbook and a knife on the table. You rest your
hand against a wall, but you miss the wall and fall onto a counter. Why don't
you take a picture of it, it'll last longer! You see a banana, a red pepper and
a tomato on the counter. You see a stove. However, the stove, like an empty
stove, has nothing on it. Aw, here you are all, excited for there to be things
in it!
> take knife
You take the knife from the table.
> take tomato from counter
You take the tomato from the counter.
> slice tomato with knife
You slice the tomato.
In the First TextWorld Problems challenge, all the Textworld environments share a theme of “cooking in a modern house context,” where the agent needs to gather ingredients to cook a recipe. The agent must 1) read the ingredients from recipe book, 2) gather ingredients and cooking utensils by exploring the house, and 3) return to the kitchen and cook the meal. The layout and the location of the house changes game to game, so the agent must be able to adapt.
The competition starts in January 7th and ends in May 31st.
Why it matters
TextWorld is an exciting new environment where language learning and reinforcement learning is combined into a single challenge. As a competition, the First TextWorld Problem challenge offers something for both beginners and seasoned experts. The challenge introduces “handicaps,” where the agent can requests additional information from the game at the expense of a penalty. Those who are less experienced could start this competition by training an agent with additional information, and gradually improve the agent and remove unnecessary information.
Read more
- First TextWorld Problems - Microsoft Research Montreal’s latest AI competition is really cooking (Microsoft Research Blog Post)
- First TextWorld Problems: A Reinforcement and Language Learning Challenge (CodaLab Competition)
- TextWorld (Documentation)
Learning with Training Wheels: Speeding up Training with a Simple Controller for Deep Reinforcement Learning
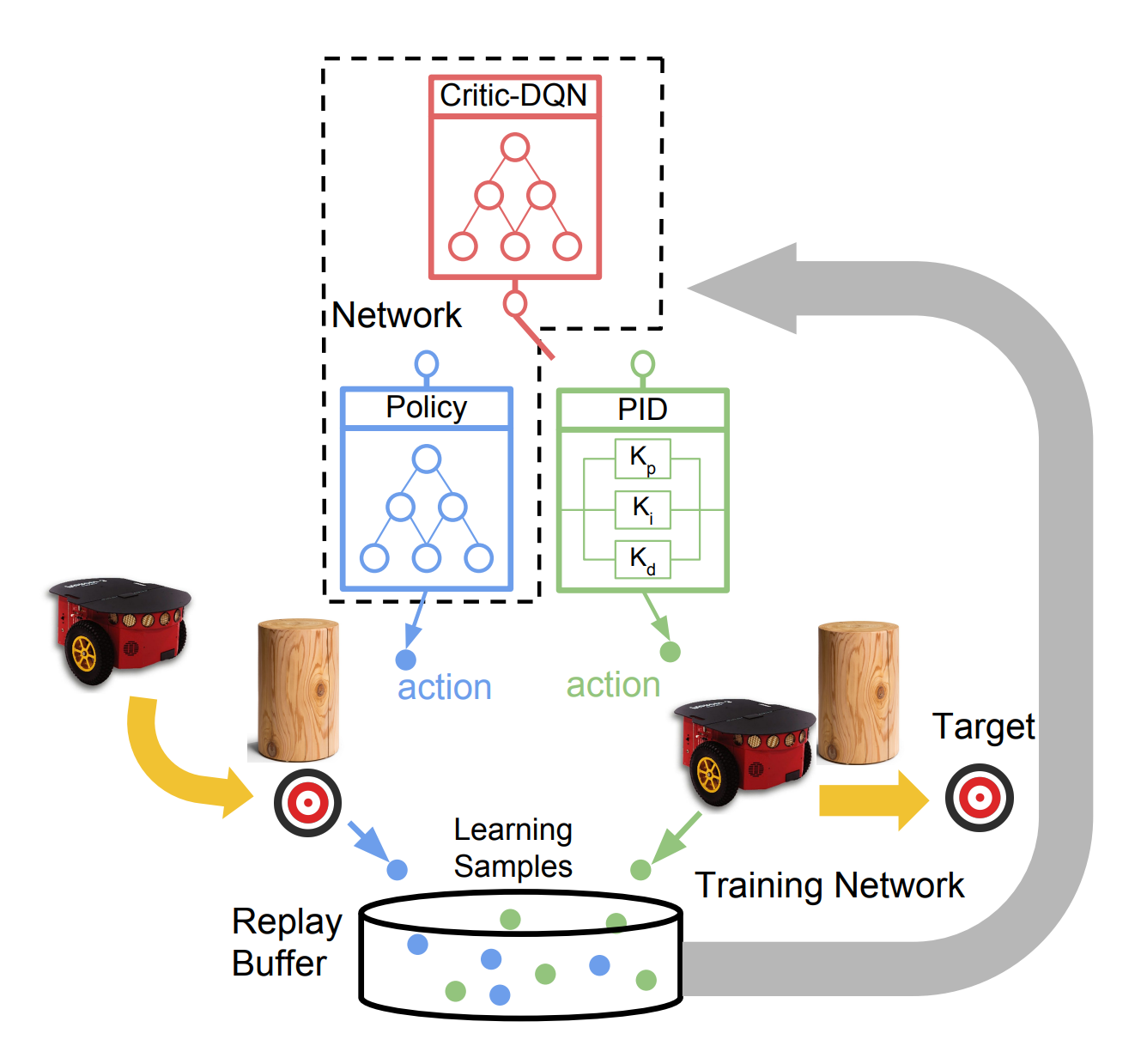
What it is
Students from University of Oxford and Heriot-Watt University proposed a new approach named Assisted Deep Deterministic Policy Gradient (AsDDPG), where a classic controller is used to speed up training a DDPG agent. The intuition is that a naive controller will easily learn simpler subtasks like driving in a straight line that epsilon-greedy exploration agents will struggle to achieve.
To decide whether to use an action chosen by the policy network or the naive controller, AsDDPG has a “Critic-DQN” that determines which action to select. Initially, the action of the simple controller will be selected the majority of the time, but over time, the learned policy will outperform the simple controller. After the training is finished, the Critic-DQN and the simple controller can be discarded.
Experiments with a simulated navigation task show several benefits of AsDDPG. AsDDPG is more robust compared to DDPG, which is highly sensitive to hyperparameters. AsDDPG also outperforms DDPG in a sparse-reward task.
Why it matters
The key issue of applying deep reinforcement learning to real world tasks is the number of trials needed to train the agent. There have been numerous works on general guided exploration techniques such as imitation learning to increase the learning speed, but there are fewer works on guided exploration techniques for robot control tasks. AsDDPG shows that even a simple idea of using a naive controller in a basic on-off manner can improve the agent.
Read more
Want to read more about what happened last week? Check out Import AI, a weekly newsletter on artificial intelligence written by Jack Clark, the Strategy and Communications Director at OpenAI.
Want to be updated on exciting new papers on arXiv? Check out @Miles_Brundage at Twitter. Miles Brundage works as a Research Scientist on the policy team at OpenAI, and tweets about new papers every day.