RL Weekly 4: Generating Problems with Solutions, Optical Flow with RL, and Model-free Planning
Published
Generating Problems with Solutions
What it is
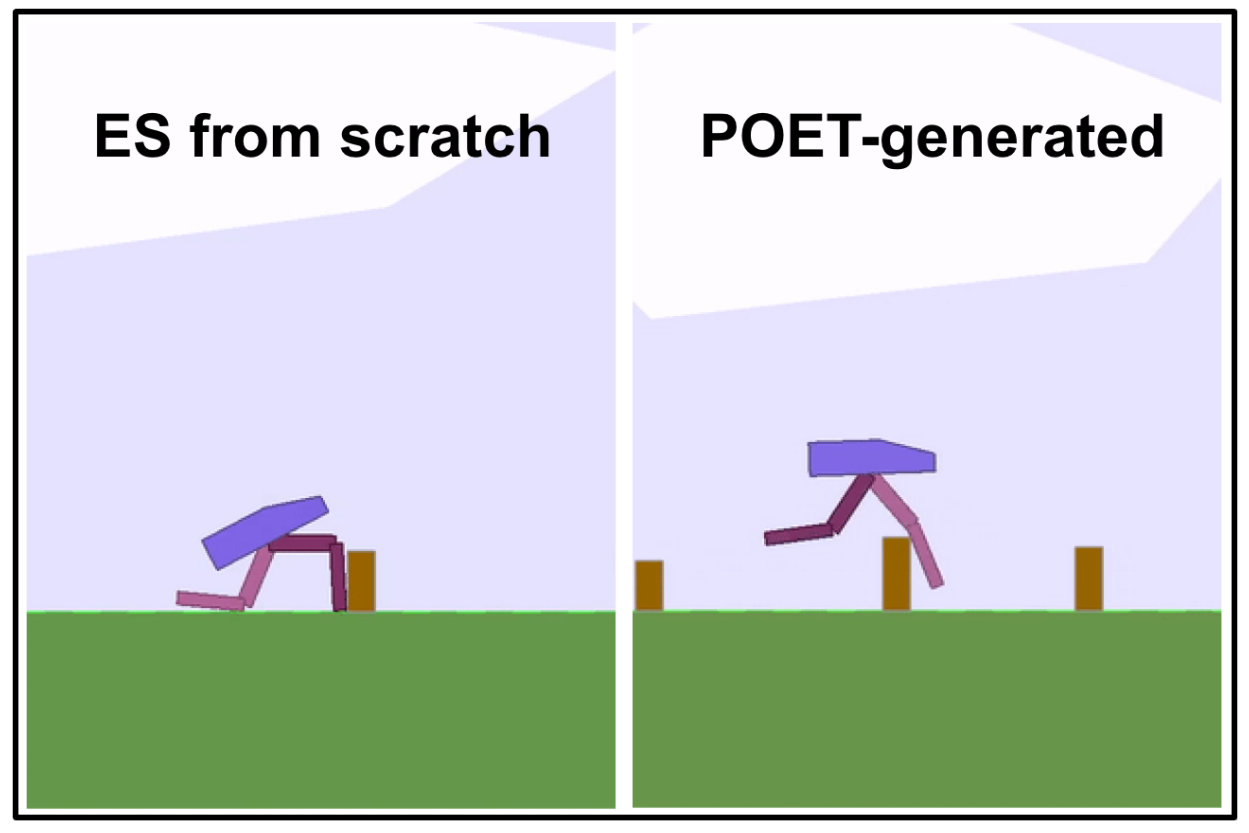
Paired Open-Ended Trailblazer (POET) is an algorithm developed by researchers at Uber AI Labs where reinforcement learning problems are generated at the same time as they are being solved. The environments are generated as the agents learn, so the agents can transfer their knowledge on previous environments to new environments. POET combined with evolutionary strategy (ES) is tested on a modified version of BipedalWalkerHardcore in OpenAI Gym, and it is able to solve difficult terrains that cannot be solved with direct optimization or with simple curriculum learning.
Why it matters
The authors of POET emphasize the unboundedness of the algorithm: with an algorithm] that can generate arbitrarily complex levels and evolve agent’s body, POET can train agents for a rich variety of environments. As demonstrated in the paper, POET can find solutions that cannot be solved with direct optimization, so with enough training, it has the potential to solve previously unsolved problems.
POET requires a method to generate environments so that agent from one variant can transfer its knowledge to a slightly more difficult variant. Unfortunately, not all environments can be easily modified to use POET, especially those on the real world. However, POET-style curriculum learning seems promising on navigation tasks such as CarRacing, TORCS, and other self-driving car environments.
Read more
- Paired Open-Ended Trailblazer (POET) (arXiv paper)
- Paired Open-Ended Trailblazer (POET) (Uber AI Post)
External Resources
- BipedalWalkerHardcore-v2 (OpenAI Gym Environment)
- CarRacing-v0 (OpenAI Gym Environment)
- The Open Racing Car Simulator (TORCS)
Model-free Planning
What it is
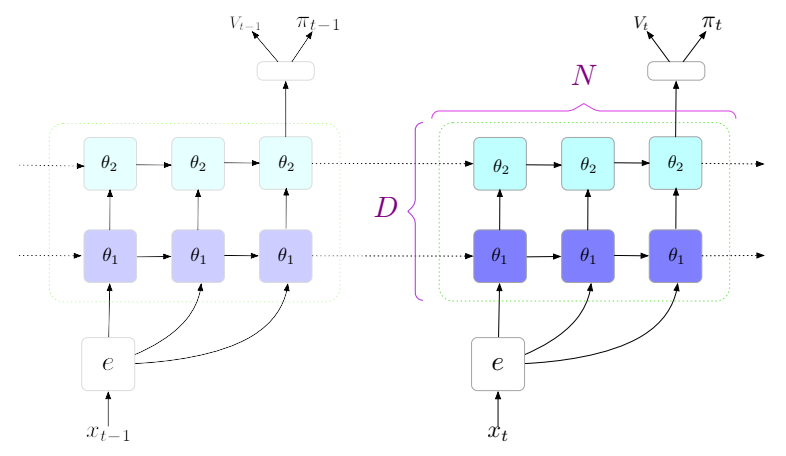
Most planning algorithms require a model of the environment. In Chess or Go, the model is given, but in other environments, the agent must learn a model through interaction. Classical algorithms learned an explicit model, whereas recent works added inductive bias in the function approximator through agent architecture instead. Researchers at DeepMind suggest that even without this special structure, the agent can learn to plan if the neural network is flexible enough.
To verify this idea, the paper introduces a new algorithm named Deep Repeated ConvLSTM (DRC), which uses stacked convolutional LSTMs. DRC is tested in Gridworld, Sokoban, BoxWorld, and five Atari 2600 games, obtaining state of the art scores in most environments, most notably in Asteroid and Ms. Pacman.
Why it matters
In this paper, not only are the state of the art results impressive, but also the proposal of model-free algorithm in planning. They take a “behaviorist approach to measuring planning as a property of the agent’s interactions” and consider three key properties that a planning agent should exhibit: generalization across situations, data efficiency, and correlation of thinking time and performance. Although these properties do not perfectly define planning, this novel approach is certainly worth analyzing.
Read more
- An investigation of model-free planning (arXiv Paper)
- An investigation of model-free planning (ICLR 2019 Review)
External Resources
Optical Flow with RL
What it is
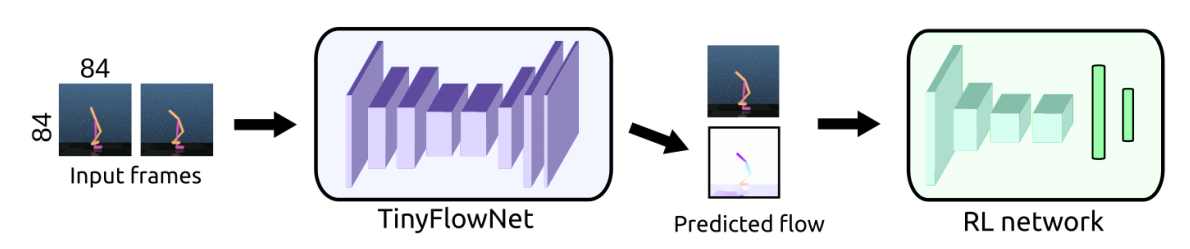
Intel Labs and the University of Freiburg collaborated to show that an explicitly learned motion features could improve learning. Instead of using direct sensory observation input, they propose optical flow estimation using the FlowNetS network. They show that in simple continuous control environments, this explicitness can improve performance.
Why it matters
Although pure reinforcement learning is an elegant solution, it often is impractical due to the lack of data efficiency. To use reinforcement learning in the real world, many techniques must be used to speed up the learning process. A popular and effective technique used throughout deep learning is “divide and conquer.” This paper suggests one such technique for dividing the continuous control task: using optical flow. Although it awaits for verification in complex environments, their preliminary results show promise.
The authors also show that performance does not degrade in most environments when given image differences as input instead of image stacks. Although further tests is needed to verify this result in other algorithms, this could accelerate learning in multiple tasks if it can be reproduced and generalized.
Read more
External Resources