RL Weekly 34: Dexterous Manipulation of the Rubik's Cube and Human-Agent Collaboration in Overcooked
Published
Dear readers,
Here is the 34th issue! In this issue, we look at a robot hand manipulating and “solving” the Rubik’s Cube. We also look at how RL agents perform in collaborative tasks when paired with human players.
As always, please feel free to email me or leave any feedback. Your input is always appreciated.
- Ryan
Solving Rubik’s Cube with a Robot Hand

What it says
Last year, OpenAI demonstrated a single robot hand dexterously manipulating a block using sim-to-real transfer. In this result, they replaced the block with a Rubik’s Cube. A classical algorithm called the Kociemba’s algorithm generated the solution steps, so the focus of the study was on perception and dexterous manipulation.
Most of the idea is identical to the previous work on training for the block reorientation task. The robot hand is trained in simulation. The vision-based state estimator that outputs observation (cube pose and face angles) from raw pixels and the control policy that uses these observations to output actions are trained separately. Then, the state estimator and the control policy is combined and transferred to the real world. To reduce the gap between simulation and reality, various domain randomization techniques have been used, such as changing the colors, illuminations, friction coefficient, and other visual and physical properties.
This domain randomization technique relies on manual tuning, so Automatic Domain Randomization (ADR) was proposed and used for the training of the Rubik’s Cube. The central idea of ADR is gradually expanding the distribution of environments that the model can perform well in. This removes the need for manual tuning of the randomization parameters, and also naturally introduces a curriculum, starting with a single environment and additional environments being added when some performance threshold is met (Section 5).
Also, unlike a block that has different letters on each face, the Rubik’s Cube is rotationally symmetric. Thus, the Rubik’s Cube has been modified in one of the two ways. The first is using asymmetric center stickers that have one corner cut, and the second is using a customized Giiker Cube with built-in sensors (Section 7).
The training The robot is able to solve scrambles that require 15 or less rotations 60% of the time, and can maximally difficult scrambles 20% of the time. The authors note that the failures occur mostly during the first few rotations and flips where the robot must detect and adapt to the physical world.
Read more
- OpenAI Blog Post (Rubik’s Cube)
- OpenAI Blog Post (Learning Dexterity)
- YouTube Video (Solving the Rubik’s Cube)
- YouTube Video (Under Perturbations)
On the Utility of Learning about Humans for Human-AI Coordination

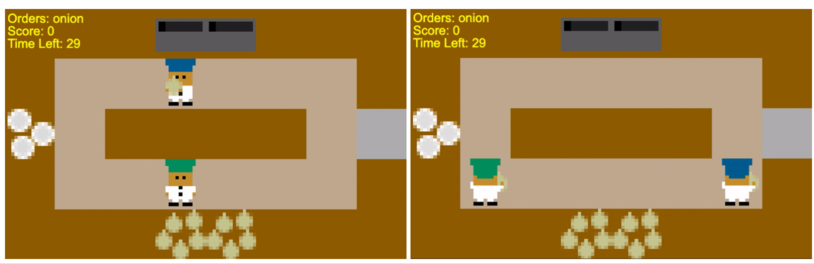
What it says
RL agents have performed well against human players in various tasks such as Go (AlphaGo) and Dota (OpenAI Five). These algorithms have been trained with self-play, which expects the opponent to play like itself. Human players often deviate from this expectation, but this is rarely problematic to the agents since suboptimal human actions benefit the agents even more. For collaborative tasks, however, the human players deviating could result in a suboptimal outcome for both the agent and the human player.
A two-player environment that is a simplified version of the game Overcooked is used to test this hypothesis. The goal of the agents are to bring the onions to the pot, cook them, bring a plate, put the cooked onions in a plate, and serve them. The kitchen is designed to test the coordination of the two players. For example, the two players could pass the onions through the counter instead of moving around the counter. A human model is trained using behavior cloning leaned over human trajectories.
Upon experiments, the agents that were explicitly designed to work with human models performed significantly better and were more adaptive.
Read more
Here are some more exciting news in RL:
A Simple Randomization Technique for Generalization in Deep Reinforcement Learning
Using a randomized state input for agent training allows for better performance of PPO in CoinRun, DM-Lab, and Surreal Robotics tasks.
A Survey and Critique of Multiagent Deep Reinforcement Learning
A survey of multiagent deep RL (MDRL) that categorizes recent works and lists the challenges and open questions of MDRL.
Adaptive Trade-Offs in Off-Policy Learning
C-trace is a variant of Retrace that uses adaptive mixture of target and behavior policy for a modified target policy. This allows for better tradeoffs between update variance, fixed-point bias, and contraction rate. C-trace with DQN or R2D2 achieves similar or better performance in Atari environments.
Momentum in Reinforcement Learning
Value Iteration can be extended to Momentum Value Iteration (MoVI), and can be used with DQN for better performance on Atari.
Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning
A new environment suite with 50 manipulation tasks that can be used for multitask RL or meta-RL.
RoboNet: Large-Scale Multi-Robot Learning
The RoboNet dataset features data collected from different robots in diverse settings to mitigate the data collection problem for using RL for robotics.
Regularization Matters in Policy Optimization
Various regularization techniques (L1, L2, Weight clipping, Dropout, BatchNorm, Entropy) on various parts of RL framework with MuJoCo. Empirically, regularizing just the policy network is enough, and L2 performs best on average, although there are fluctuations based on algorithms and tasks used.
SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
By optimizing the distributed architecture and using TPUs, it is possible to speed up training significantly.
Stabilizing Transformers for Reinforcement Learning
Transformers are hard to incorporate to RL settings, but with architectural modifications, Gated Transformer-XL (GTrXL) can surpass LSTM in DM-Lab multitask suite.