RL Weekly 35: Escaping Local Optimas in Distance-based Rewards and Choosing the Best Teacher
Published
Dear readers,
Here is the long overdue 35th issue! RL Weekly should be released weekly again starting next week, so the 36th issue will be published next week. Thank you for your patience.
As always, please feel free to email me or leave any feedback. Your input is always appreciated.
- Ryan
Keeping Your Distance: Solving Sparse Reward Tasks Using Self-Balancing Shaped Rewards
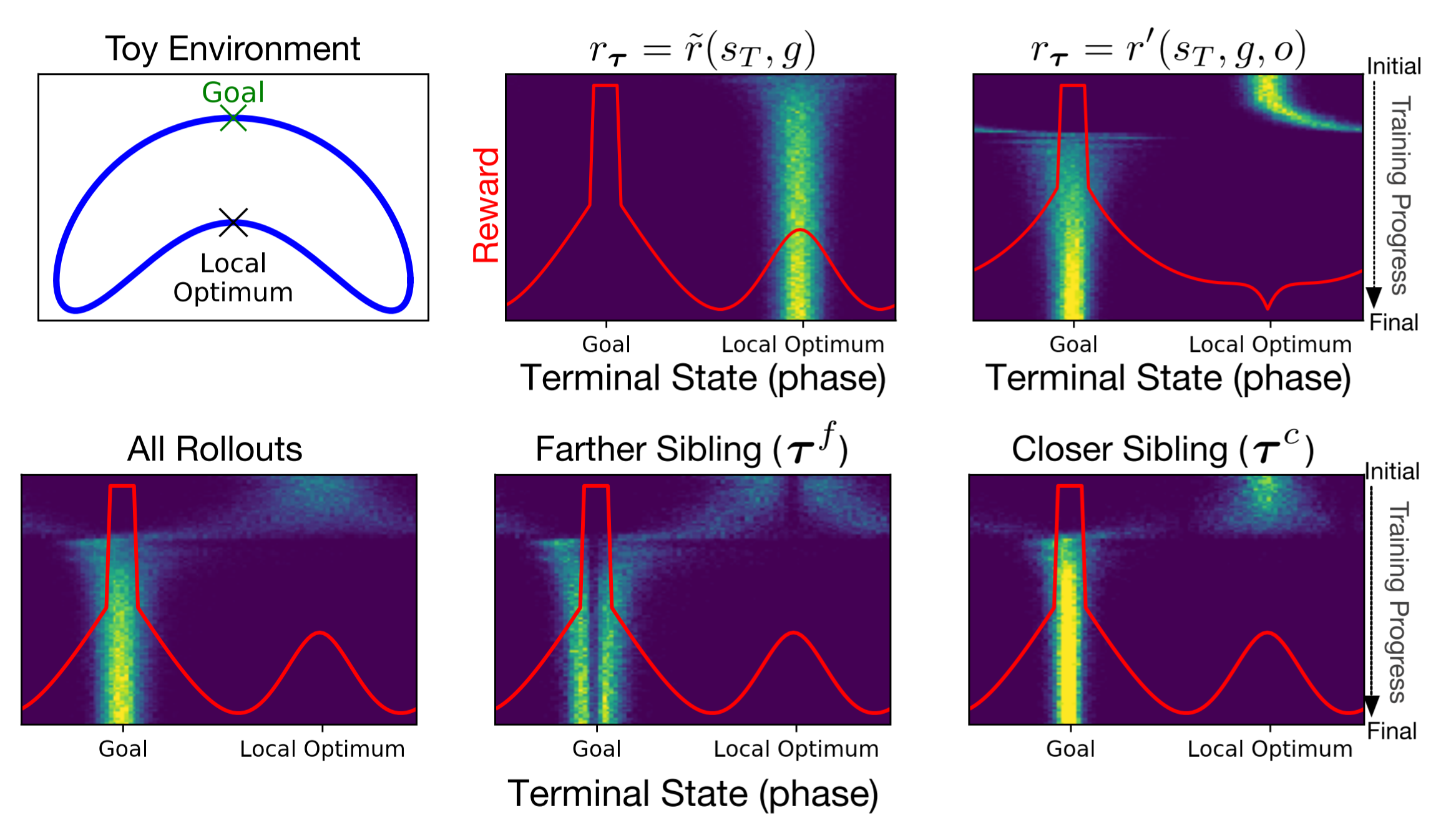
What it says
In goal-oriented RL tasks, the agent receives reward only once, when it reaches the goal. As the sparsity of reward makes the training challenging, reward shaping techniques have been used, especially distance-based shaped rewards. However, this often leads to local optima in cases where the agent must move away from the goal to reach it, In a Boomerang-shaped environment shown in top-left figure, the local optima is located in the concave part. One way to combat this local optima is to shape the reward to explicitly avoid it. (This avoided state is named the “antigoal.”) The top center and top right figures show the terminal states without and with this additional reward shaping.
However, the location of the local optima is problem-specific. The authors therefore introduce Sibling Rivalry, a general algorithm using two “sibling” trajectories to escape local optima. The sibling trajectories have the same starting states and goal states, and is generated using the same policy. We label one the farther sibling and the other the closer sibling based on their terminal states. The rewards of each sibling trajectory is shaped to avoid the terminal states of the other sibling (i.e. the terminal state of the other sibling is set as the antigoal. As shown in the bottom figures, the terminal states of the closer sibling is centered around an optimum, whereas the further sibling spread around an optimum, balancing exploitation and exploration.
Tested with PPO against Intrinsic Curiosity Module, Random Network Distillation, and Hindsight Experience Replay, Sibling Rivalry achieves better performance in 2D maze environments.
Read more
ZPD Teaching Strategies for Deep Reinforcement Learning from Demonstrations
What it says
Zone of Proximal Development (ZPD) is an epistemological theory built on an intuition that best examples to teach are those that are “difficult for the learner to solve alone but can be solved with guidance.” The authors apply the idea of ZPD to learning from demonstrations, notably DQfD, where given a set of teachers (demonstrators), the algorithm dynamically selects the best teacher.
The teachers are created by saving snapshots of a single DDQN agent pre-trained on the benchmark environment. The best teacher is selected by finding the snapshot with the reward closest to the student’s reward, and by choosing the snapshot that is fixed snapshots ahead (“k ahead”) from the closest snapshot. The agent is trained DQfD-style, sampling a minibatch from both its own experiences and the teacher’s experience.
The algorithm is tested In 9 Atari environments against randomly choosing snapshots (random ahead), choosing the best snapshot (best ahead), and different values of k. The authors report random ahead, 5 ahead, and 10 ahead works best.
Read more
External Resources
Here are some more exciting news in RL:
Fully Parameterized Quantile Function for Distributional Reinforcement Learning
Fully parametrizing both the quantile fractions and corresponding quantile values results in performance better than IQN and Rainbow.
Generalization of Reinforcement Learners with Working and Episodic Memory
The Memory Tasks Suite is a test suite that can evaluate the generalization during test time. The paper contains ablation study of a Memory Recall Agent: an IMPALA agent with 5 memory components.
Overcoming Catastrophic Interference in Online Reinforcement Learning with Dynamic Self-Organizing Maps
Experience replay mitigates the catastrophic interference phenomenon but requires memory. By using Dynamic Self-Organizing Maps (DSOM), the global updates can be replaced with a local update to mitigate the interference without using experience replay.
Reinforcement Learning Algorithms Zoo
The Tensorlayer team released RL Zoo, a collection of RL algorithms implemented with TensorFlow 2.0 and TensorLayer 2.0.
Better Exploration with Optimistic Actor-Critic
Exploration strategies in SAC and TD3 are inefficient as they underexplore due to pessimistic estimations and are directionally uninformed. By approximating an upper confidence bound and maximizing it, the Optimistic Actor Critic shows performance superior to SAC and TD3 in MuJoCo environments.
AlphaStar: Grandmaster level in StarCraft II using multi-agent reinforcement learning
AlphaStar played on the official StarCraft II game server under same constraints as human players and ranked above 99.8% of active players.

