RL Weekly 33: Action Grammar, the Squashing Exploration Problem, and Task-relevant GAIL
Published
Dear readers,
Here is the 33rd issue, containing two weeks worth of news! In this issue, we look a hierarchical RL framework that adds new macro-actions from action grammar. We then look at the problem of additive noise on bounded actions and how solving this leads to better performance for TD3. Finally, we look at an improvement to GAIL on raw pixel observations by focusing on task-relevant details.
This week, I will be at the Workshop on Theory of Deep Learning hosted in the Institute for Advanced Study. If you are coming, I would love to have a chat with you!
As always, please feel free to email me or leave any feedback.
- Ryan
Reinforcement Learning with Structured Hierarchical Grammar Representations of Actions
What it says
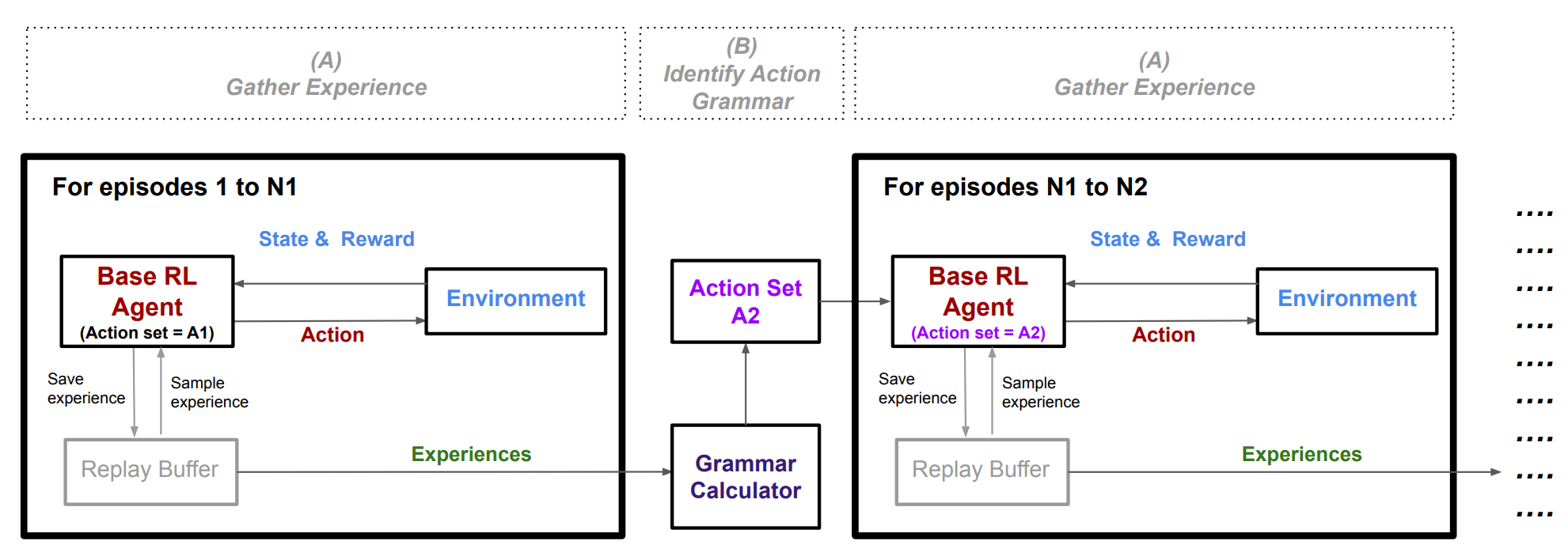
Identifying a good hierarchical policy structure is difficult, which has hindered the progress of Hierarchical RL (HRL). From human behavior of relying on grammatical principles, it is possible to define Action Grammar RL (AG-RL). AG-RL is a two-step process: with the standard off-policy learning with experience collection, paired with an action grammar identification stage.
The Gather Experience step is similar to standard off-policy learning. The agent interacts with the environment, saves experience to a replay buffer, and samples batches to train. One difference is that a separate buffer is used to collect experience of episodes run with all random exploration turned off.
The Action Grammar Identification step then uses this separately stored experience to generate new macro actions using a a regularized version of grammar calculator called “Sequitur.” given a sequence of actions, a macro action is created to replace repeating subsequences of actions if it reduces the amount of information needed to encode the sequence.
Deep RL agents have a separate output node for each action, so adding new macro actions requires transfer learning. All existing nodes have their weights unchanged, and the new nodes have the same weights as the “closest” action. For example, if “a” and “b” are actions and “abb” is the new macro action, then the weights of “abb” is initialized by copying those of “a”.
A few more improvements are added. (1) Hindsight Action Replay (HAR) is an idea of augmenting the replay buffer. When a macro-action is played, the experiences of individual actions are also added to the buffer, and if a sequence of primitive actions match a macro-action, the macro-action experience is also added to the buffer. (2) The buffer also uses balanced sampling so that it returns a batch containing equal amounts of each action. (3) A agent abandons the macro-action if following the macro-action is significantly worse than the best primitive action. (4) Finally, the agent is biased to select macro-actions during random exploration.
AH-RL works well in Towers of Hanoi. Furthermore, AG-DDQN (Double DQN) and AG-SAC (Soft Actor critic) show better performance than DDQN and SAC respectively in most Atari games tested. The ablation studies on Qbert using DDQN show that of the four improvements, Hindsight Experience Replay was the most influential technique.
Read more
Towards Simplicity in Deep Reinforcement Learning: Streamlined Off-Policy Learning
What it says
Maximum entropy (MaxEnt) RL is the idea of maximizing both the expected return and the expected entropy of the policy. MaxEnt RL has been met with great success, in particular through Soft Actor Critic (SAC), in areas where its non-MaxEnt equivalent Twin-delayed DDPG (TD3) achieves subpar performance. The success of MaxEnt RL has been attributed to better exploration and its ability to capture multiple near-optimal behaviors.
The authors describe a “squashing exploration problem”: when an additive noise is added to an action, squashing actions into a bounded action space using a tanh() function could be disastrous to exploration (Section 3). DDPG and TD3 uses such noise addition.
The proposed Streamlined Off-Policy (SOP) algorithm adds output normalization to the policy network to ensure bounded actions while mitigating squashing (Section 4). Paired with a TD3 SOP shows performance competitive to SAC in various MuJoCo domains. SOP is also tested with a simple experience replay technique called Emphasizing Recent Experience (ERE) where recent data has higher probability of being sampled. SOP+ERE is shown to have consistently better performance than SAC and SOP.
Read more
External resources
Task-Relevant Adversarial Imitation Learning
What it says
Generative Adversarial Imitation Learning (GAIL) is an imitation learning algorithm that trains a discriminator network to discern agent and expert behavior and uses it for a reward function. GAIL has worked well for feature inputs but has had trouble with raw pixel inputs.
The problem with raw pixel inputs is that there is a lot of task-irrelevant information in the observation. This allows the discriminators of GAIL to exploit task-irrelevant features leading to poor performance. Some good ways to mitigate this problem is data augmentation and actor early stopping. Actor early stopping is needed since once the actor is trained, the discriminator cannot distinguish agent and expert from its behavior, and is forced to distinguish using task-irrelevant features.
Although regularization and data augmentation improves upon standard GAIL, the authors propose adding a constraint for the discriminator. The constraint is that the discriminator must not be able to distinguish between the agent and the expert during some invariant set, where there is no meaningful behavior. that it cannot distinguish agent and expert demonstrations from their early frames, where their behavior is not apparent. The authors experimentally find that both using frames from a random policy or extracting early frames from a trained policy works.
Experimentally, TRAIL shows better performance than GAIL in simulated block lifting tasks.
Read more
Here are some more exciting news in RL:
Quantized Reinforcement Learning (QUARL)
Empirical study on the effects of quantification of various RL algorithms to reduce needed computational resources.
The Paths Perspective on Value Learning
A blog post on Distill illustrating the idea of temporal difference learning.
TorchBeast: A PyTorch Platform for Distributed RL
A PyTorch implementation of IMPALA.
SURREAL-System: Fully-Integrated Stack for Distributed Deep Reinforcement Learning
A scalable framework for distributed deep RL.
“I’m sorry Dave, I’m afraid I can’t do that” Deep Q-learning from forbidden action
Define a “frontier loss” using a classification network to encourage the Q-values of forbidden actions to be below those of each valid actions.
Benchmarking Batch Deep Reinforcement Learning Algorithms
Benchmarks of batch deep RL algorithms with data generated by one partially trained policy. The discrete variant of Batch-Constrained deep Q-learning (BCQ) consistently outperforms other methods.
Discounted Reinforcement Learning is Not an Optimization Problem
Discounted RL (using a discount factor) in a continuing task does not have a well-defined objective and is thus not an optimization problem. However, average reward RL is.
If MaxEnt RL is the Answer, What is the Question?
Analysis of maximum entropy RL, showing that its benefits come from “implicitly solving control problems with variability in the reward.”
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Using two standard supervised learning steps is enough to learn value function and policy in an off-policy manner that is competitive to state-of-the-art RL methods such as TD3 and SAC.