RL Weekly 25: Replacing Bias with Adaptive Methods, Batch Off-policy Learning, and Learning Shared Model for Multi-task RL
Published
On Inductive Biases in Deep Reinforcement Learning
What it says
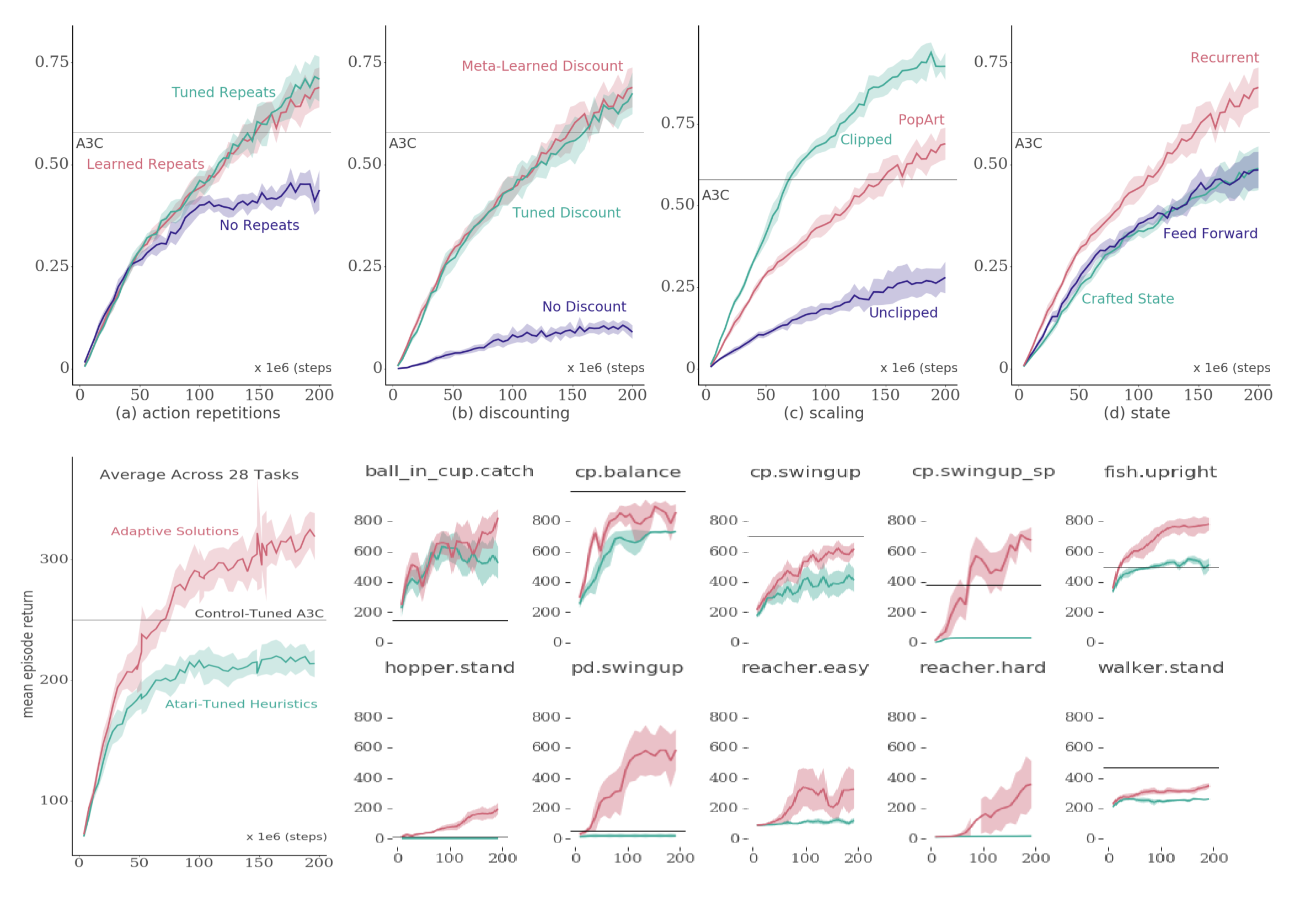
When injecting inductive bias, there is a tradeoff between generality and performance. Adding more bias allows for faster training and often better performance, whereas adding fewer bias allows for more general algorithms applicable to wider set of problems. However, more inductive bias does not always result in better result, as shown by AlphaGo and AlphaZero.
In deep RL, the two most common methods of injecting bias is by modifying the objective (reward) or by modifying the agent-environment interface. Reward modification methods such as reward clipping or discounting is very commonplace, if not universal, across papers. Likewise, agent-environment interface is often tweaked through methods such as action repetitions (also known as frame skipping) and observation preprocessing.
Instead of such methods, the authors propose using adaptive solutions.
- Reward clipping is replaced with PopArt
- Constant discount factor is replaced with meta-learning based adaptive discount factor
- Frame skipping is replaced with “Dynamic Action Repetition”
- Observation preprocessing (Downsampling, Gray-scaling, Frame stacking) is removed
- “Number of lives” information is ignored
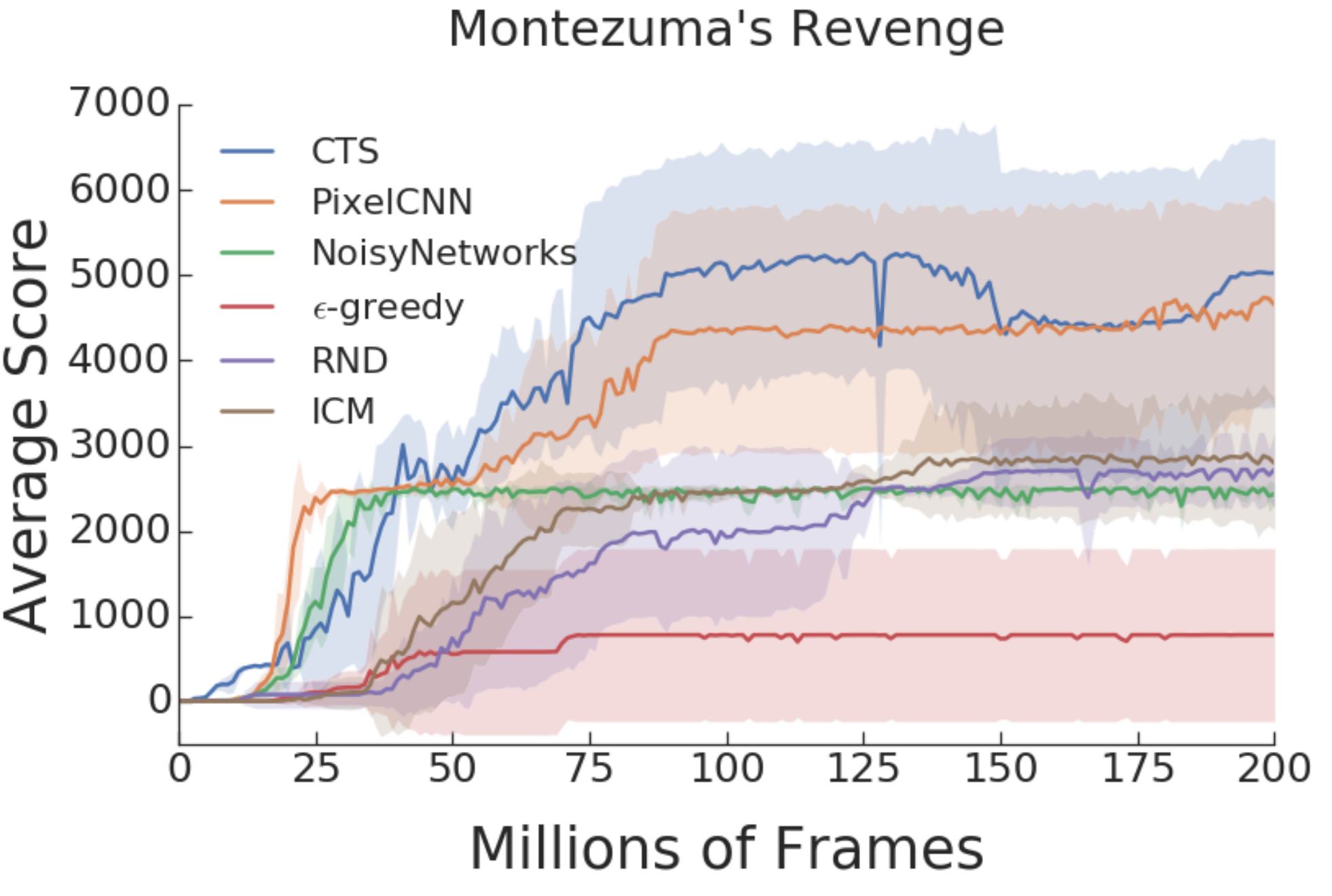
Through experiments in a simple tabular environment with A2C, the authors show that the hyperparameters introducing inductive bias are sensitive and that using adaptive solutions performs competitively with the best hyperparameters. The experiments show that adaptive solutions (Colored red in figure above) are competitive to inductive biases (Colored green) in Arcade Learning Environment (top row) and generalize better to new domains (bottom row).
Read more
External resources
- Learning values across many orders of magnitude (ArXiv Preprint): PopArt
- Dynamic Action Repetition for Deep Reinforcement Learning (PDF): Dynamic Action Repetition
Striving for Simplicity in Off-policy Deep Reinforcement Learning
What it says
Despite being one of the Deadly Triad (Function Approximation, Bootstrapping, and Off-policy learning) and not having theoretical guarantees, off-policy learning has great potential since it allows learning from experience collected by any policy. To develop a stable off-policy algorithm, various ideas have been proposed, but it is unclear how necessary are these “complexities of recent off-policy methods.”
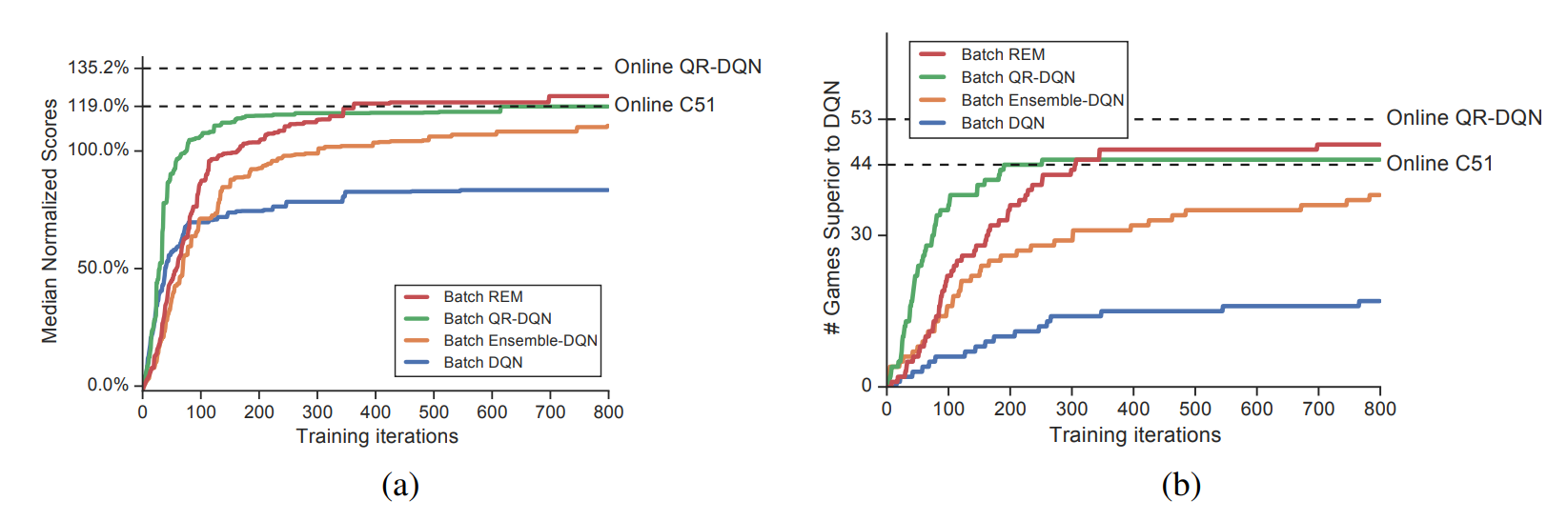
To test their ideas, the authors setup a simple “pure” off-policy learning setting. The authors first train a Nature Deep Q-Network (DQN) on a standard setting, while saving all experiences encountered during training. Then, a new “batch” agent is trained using just the save examples with no additional environment interactions (Section 3).
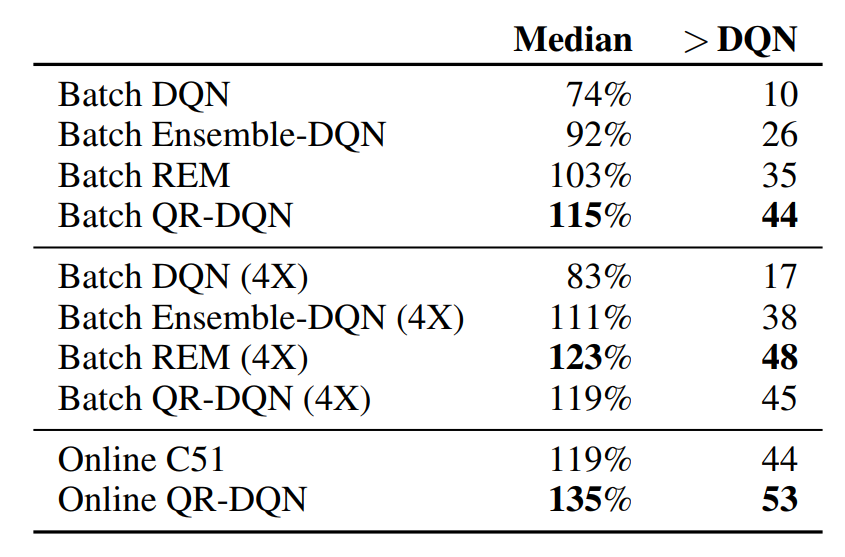
The authors find that “batch” DQN achieves suboptimal performance than online DQN in most Atari environments and argues that DQN is “not very effective at exploiting off-policy data” (Section 3.1). However, the authors find that “batch” QR-DQN and “batch” C51 significantly outperforms batch DQN and conclude that the performance gain of distributional RL agents originate from better exploitation capability rather than better exploration.
To study the success of distributional RL in more detail, the authors also test Ensemble-DQN and Random Ensemble Mixture (REM) that use a modified DQN network to output multiple heads (Section 4.1, 4.2). “Batch” ensemble-DQN and “batch” REM both significantly outperform “batch” DQN, showing that much of the performance gain of distributional RL originates from training multiple heads.
Read more
External resources
A Model-based Approach for Sample-efficient Multi-task Reinforcement Learning

What it says
Recent Multi-task reinforcement learning algorithms such as Model Agnostic Meta Learning (MAML) learn a shared policy that is served as the initial policy for all tasks. The authors suggest “revisiting the model-based approach to multi-task reinforcement learning” by learning a shared dynamic model (instead of shared policy). Thus, instead of using a shared policy as the initial policy, a policy is “warmed up” via virtual interactions with the model.
For the “Sequential Multi-task Training” algorithm that the authors suggest, the training starts by sampling tasks from the task distribution. Then, the policy is virtually trained (or “warmed up”) with the dynamics model. Meanwhile, the dynamics model is trained through model-based RL (SLBO) by interacting with the real environment (Section 4.1).
The authors compare Sequential Multi-task Training against MAML in various MuJoCo continuous control environments (Section 5.2). They report Sequential Multi-task Training outperforming MAML across all tasks, and show that the “warmed up” policy with zero interactions with the real environment can have good performance (Section 5.2), given that the tasks’ dynamics models are similar (Section 6).
Read more
External resources
- Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks (ArXiv Preprint): MAML
- Algorithmic Framework for Model-based Deep Reinforcement Learning with Theoretical Guarantees (ArXiv Preprint): SLBO
Two-line introductions to some more exciting news in RL this week:
- D-REX: T-REX uses ranked demonstrations for imitation learning, but ranked demonstrations are difficult to obtain, so let’s automatically generate them. D-REX outperforms both demonstrations and baseline methods (BC, GAIL) on most environments!
- Data Efficient RL for Legged Robots: Model-based RL can train a Minitaur robot to walk after just 4.5 minutes of data! This is made possible through 1) multi-step loss to prevent model error accumulation, 2) parallelized planning algorithm for real-time planning, and 3) safe exploration through smooth trajectory generator.
- AlphaStar in Europe Ladder DeepMind’s StarCraft II agent “AlphaStar” will be playing on the competitive ladder in Europe. Whereas the “old” AlphaStar that won against Team Liquid’s TLO and MaNa were only trained for Protoss-vs-Protoss matches with a zoomed-out view, this AlphaStar now can play any matchup and uses a camera-like view that is closer to humans.