RL Weekly 12: Atari Demos with Human Gaze Labels, New SOTA in Meta-RL, and a Hierarchical Take on Intrinsic Rewards
Published
Atari-HEAD: Atari Human Eye-Tracking and Demonstration Dataset
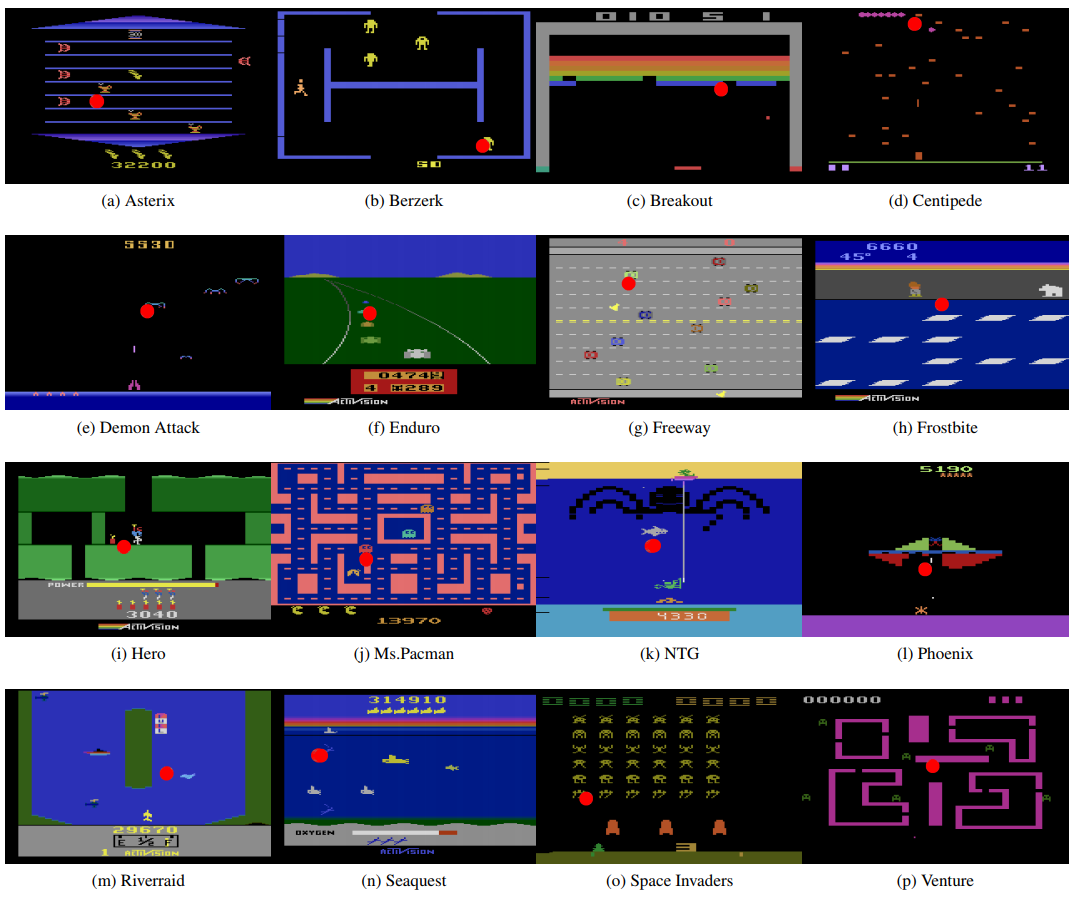
What it is
Atari-HEAD is a new dataset collected by researchers at UT Austin, Google, and CMU. The dataset contains human actions and eye-movements playing Atari 2600 games on the Arcade Learning Environment (ALE). The dataset contains demonstration data for 16 games (Asterix, Berzerk, Breakout, Centipede, Demon Attack, Enduro, Freeway, Frostbite, Hero, Ms. Pacman, Name This Game, Phoenix, Riverraid, Seaquest, Space Invaders, and Venture). To obtain near-optimal decision, the human players played these games frame-by-frame.
Why it matters
Imitation Learning is a powerful technique that allows agents to learn with little amount of interaction. However, imitation learning requires demonstration data, and gathering such data is difficult and expensive. As a result, only labs with access to such data were able to study imitation learning on various environments. This open dataset allows for labs to test their imitation learning algorithms on the most standard RL testbed: Arcade Learning Environment (ALE). Furthermore, the human gaze position data with the trajectories allows for imitation learning with visual attention.
Read more
- Atari-HEAD: Atari Human Eye-Tracking and Demonstration Dataset (ArXiv Preprint)
- Atari-HEAD: Atari Human Eye-Tracking and Demonstration Dataset (Dataset)
External Resources
Efficient Off-Policy Meta-RL via Probabilistic Context Variables
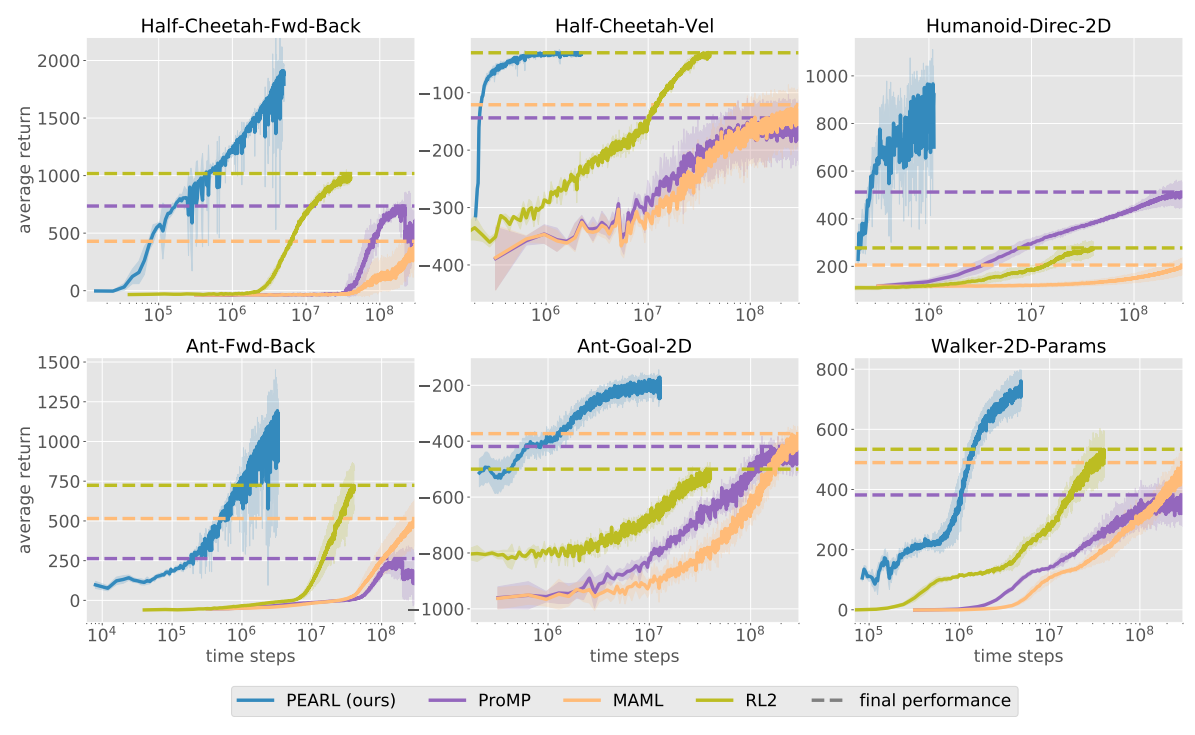
What it is
Researchers at UC Berkeley devloped Probabilistic Embeddings for Actor-critic RL (PEARL), an off-policy meta-RL algorithm. Meta-RL refers to methods that can adapt and learn quickly in new tasks by incorporating experience from related tasks. The authors show that PEARL is drastically more sample efficient while outperforming other meta-RL methods (RL^2, MAML, and ProMP).
Read more
- Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables (ArXiv Preprint)
- PEARL: Efficient Off-policy Meta-learning via Probabilistic Context Variables (GitHub Repo)
External Resources
These are resources to learn about meta learning:
- Meta-Learning: Learning to Learn Fast (Lilian Weng’s Blog Post)
- Meta Learning (CS294-112: Deep Reinforcement Learning Lecture Slides)
Hierarchical Incorporation of Intrinsic Rewards
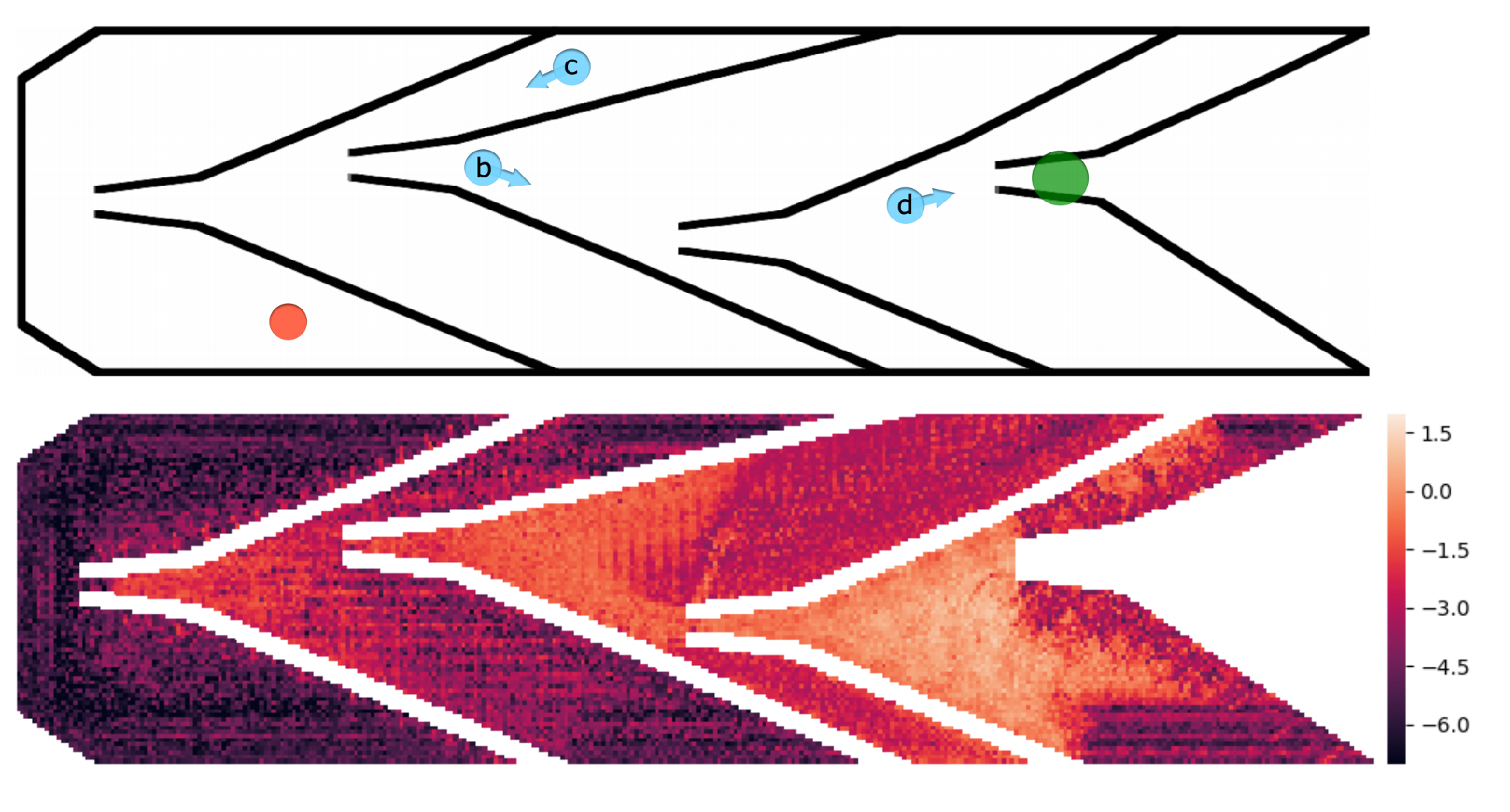
What it is
Researchers at University of Freiburg proposed Scheduled Intrinsic Drive (SID) agent that separates maximization of intrinsic and extrinsic rewards. Instead of maximizing the sum of intrinsic and extrinsic rewards, a high-level controller chooses which reward to maximize for certain number of steps. The authors claim that random controller is a good candidate. The authors also propose Successor Feature Control (SFC), a new intrinsic reward using successor features for more far-sighted exploration. SID and SFC are shown to perform better than simple sum and ICM or RND in navigation tasks.
Why it matters
Existing state-of-the-art methods such as Intrinsic Curiosity Module (ICM) and Random Network Distillation (RND) provide novel methods of representing novel experiences as numerical intrinsic rewards. However, they do not provide novel methods of combining intrinsic rewards and extrinsic rewards and simply add them and provide it to the agent as a reward signal. Because these rewards stem from different objectives, different combining methods such as SID would be an interesting avenue to pursue to improve agent’s performance.
Read more
- Scheduled Intrinsic Drive: A Hierarchical Take on Intrinsically Motivated Exploration (ArXiv Preprint)
- Scheduled Intrinsic Drive: A Hierarchical Take on Intrinsically Motivated Exploration (YouTube Video)
Some more exciting news in RL:
- Marc G. Bellemare published a blog post summarizing his 18 months of RL research at Google Brain in Montreal.
- Joshua Achiam, Ethan Knight, and Pieter Abbeel investigated causes of divergence in Deep Q-Learning and proposed Preconditioned Q-Networks (PreQN).
- ICML Workshops have been announced. Workshops such as “Exploration in Reinforcement Learning Workshop”, “Workshop on Multi-Task and Lifelong Reinforcement Learning”, or “Reinforcement Learning for Real Life” could be a nice place to submit your research!