Train a Deep Q-Network with Swift for TensorFlow (S4TF)
Published
Introduction
Deep Q-Network (DQN) is a reinforcement learning algorithm published in Nature in 2015. It was the first deep reinforcement learning algorithm to use the Atari 2600 environments from Arcade Learning Environment, which became the standard benchmark for reinforcement learning agents. DQN achieved superhuman performance in many of the games, which led to its popularity.
Swift for TensorFlow (S4TF) is Google’s product to bring machine learning to Swift. Python has been the primary language for prototyping and developing machine learning models, with the two most popular machine learning libraries (TensorFlow and PyTorch) both being Python libraries. Python has a great benefit of being easy to use. However, native Python is very slow and relies on external libraries like NumPy for computation. Swift, on the other hand, is faster and safer, while still being easy to use.
In this post, we explore how to use Swift for TensorFlow to implement Deep Q-Network. We look at each component of Deep Q-Network and see how they can be translated to Swift for TensorFlow. The code is also available in GitHub.
This work is a part of my Google Summer of Code project. Google Summer of Code connects student developers with open source organizations. Students are assigned mentors from the organizations to help them contribute to their software. I had the pleasure of working with Brad Larson and Dan Zheng from TensorFlow, and this work would not have been possible without them.
Q-Network
The Q-network is a neural network that receives the state as input and returns the estimated action value (Q-value) of each action as output. The Q-Network is the heart of the DQN agent: it governs how the agent will act when in a state.
In S4TF, it is very easy to create a neural network with the Layer protocol. During
initialization, we define dense layers by their input and output sizes and activation functions.
Then, we allow the network to be called as a function using the Tensor.sequenced() function.
Full Code for DeepQNetwork struct
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
/// A Deep Q-Network.
///
/// A Q-network is a neural network that receives the observation (state) as input and estimates
/// the action values (Q values) of each action. For more information, check Human-level control
/// through deep reinforcement learning (Mnih et al., 2015).
struct DeepQNetwork: Layer {
typealias Input = Tensor<Float>
typealias Output = Tensor<Float>
var l1, l2: Dense<Float>
init(observationSize: Int, hiddenSize: Int, actionCount: Int) {
l1 = Dense<Float>(inputSize: observationSize, outputSize: hiddenSize, activation: relu)
l2 = Dense<Float>(inputSize: hiddenSize, outputSize: actionCount, activation: identity)
}
@differentiable
func callAsFunction(_ input: Input) -> Output {
return input.sequenced(through: l1, l2)
}
}
S4TF Documentation
We can design the agent to greedily choose the action with the highest Q-value. However, this may not be a good idea, since the agent can get stuck in a local optimum. Therefore, we want the agent to explore different actions, even if it thinks it is suboptimal. One way to achieve such exploration is by making the agent sometimes choose random actions. This is called the $\varepsilon$-greedy action selection. For probability $\varepsilon$, the agent chooses a random action, and for probability $1 - \varepsilon$, it chooses the action with the highest action value.
To implement this, we sample a number from 0 to 1, and if it is less than $\epsilon$, we choose a
random action. For random action selection, we can use NumPy, since S4TF supports it! We just need
to convert it into a Tensor with Tensor(numpy: , dtype: ).
In case we don’t randomly sample an action, we use the Q-network to get the Q-values of each action. Here, we consider the simplest case where there are just two actions: 0 and 1. If the Q-value for action 1 is higher, the agent chooses action 1, and it chooses action 0 otherwise.
Full Code for getAction function
1
2
3
4
5
6
7
8
9
10
func getAction(state: Tensor<Float>, epsilon: Float) -> Tensor<Int32> {
if Float(np.random.uniform()).unwrapped() < epsilon {
return Tensor<Int32>(numpy: np.array(np.random.randint(0, 2), dtype: np.int32))!
} else {
// Neural network input needs to be 2D
let tfState = Tensor<Float>(numpy: np.expand_dims(state.makeNumpyArray(), axis: 0))!
let qValues = qNet(tfState)[0]
return Tensor<Int32>(qValues[1].scalarized() > qValues[0].scalarized() ? 1 : 0, on: device)
}
}
S4TF Documentation
Experience Replay
Now, what do we train the Q-Network with?
In reinforcement learning, the agent interacts with the environment to gain experience. The agent is given observations, takes action, and is given an appropriate reward. The agent uses this experience to learn what actions should be taken for what observations to maximize the reward through trial and error.
In online reinforcement learning (like Q-learning), the agent uses each experience just once and forgets about it. Deep Q-Network is an offline reinforcement learning algorithm: it keeps all its experience from its past self into a collection called a Replay Buffer. This technique is called Experience Replay, and it allows the agent to use an experience multiple times.
Each experience consists of five components: the state the agent was in, the action it
took, the reward it received, the next state it went to, and whether the episode finished.
In S4TF, we create an array for each component and use the @noDerivative attribute since we do
not need to calculate their derivatives.
1
2
3
4
5
@noDerivative var states: [Tensor<Float>] = []
@noDerivative var actions: [Tensor<Int32>] = []
@noDerivative var rewards: [Tensor<Float>] = []
@noDerivative var nextStates: [Tensor<Float>] = []
@noDerivative var isDones: [Tensor<Bool>] = []
Every experience that the agent collects takes up space in the memory. Therefore, in reality, the agent cannot save all the experience: it must delete old ones. Therefore, the replay buffer has a set capacity, and if the replay buffer is already full, the oldest experience is deleted before a new experience is added.
In S4TF, we can easily implement this using the Swift-native .removeFirst() and .append()
function that removes the first element and appends a new element to the end of the array.
Full Code for ReplayBuffer.append() function
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
func append(
state: Tensor<Float>,
action: Tensor<Int32>,
reward: Tensor<Float>,
nextState: Tensor<Float>,
isDone: Tensor<Bool>
) {
if count >= capacity {
states.removeFirst()
actions.removeFirst()
rewards.removeFirst()
nextStates.removeFirst()
isDones.removeFirst()
}
states.append(state)
actions.append(action)
rewards.append(reward)
nextStates.append(nextState)
isDones.append(isDone)
}
The agent samples a minibatch of experience from this collection and uses that batch for training. In Deep Q-Network, the sampling is done uniformly at random, so every experience in the replay buffer has the same probability of being sampled.
We first sample the indices using the random number function Int32.Random(). (The indices for
Tensors need to be Int32, not Int.) Then, we stack the entire collection into a Tensor and
sample the experience according to the indices using Tensor.gathering().
Full Code for ReplayBuffer.sample() function
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
func sample(batchSize: Int) -> (
stateBatch: Tensor<Float>,
actionBatch: Tensor<Int32>,
rewardBatch: Tensor<Float>,
nextStateBatch: Tensor<Float>,
isDoneBatch: Tensor<Bool>
) {
let sampledIndices = (0..<batchSize).map { _ in Int32.random(in: 0..<Int32(count)) }
let indices = Tensor<Int32>(shape: [batchSize], scalars: sampledIndices)
let stateBatch = Tensor(stacking: states).gathering(atIndices: indices, alongAxis: 0)
let actionBatch = Tensor(stacking: actions).gathering(atIndices: indices, alongAxis: 0)
let rewardBatch = Tensor(stacking: rewards).gathering(atIndices: indices, alongAxis: 0)
let nextStateBatch = Tensor(stacking: nextStates).gathering(atIndices: indices, alongAxis: 0)
let isDoneBatch = Tensor(stacking: isDones).gathering(atIndices: indices, alongAxis: 0)
return (stateBatch, actionBatch, rewardBatch, nextStateBatch, isDoneBatch)
}
S4TF Documentation
It is possible to enhance the performance of Deep Q-Network using alternative sampling methods. One simple method is Combined Experience Replay. In this method, the sampling is still uniformly random, but the most recent experience is always sampled.
In S4TF, we add a boolean flag to toggle combined experience replay. For combined experience replay,
we simply combine the sampled indices with the last index of the replay buffer with the +
operator.
1
2
3
4
5
6
7
8
9
if self.combined == true {
// Combined Experience Replay
let sampledIndices = (0..<batchSize - 1).map { _ in Int32.random(in: 0..<Int32(count)) }
indices = Tensor<Int32>(shape: [batchSize], scalars: sampledIndices + [Int32(count) - 1])
} else {
// Vanilla Experience Replay
let sampledIndices = (0..<batchSize).map { _ in Int32.random(in: 0..<Int32(count)) }
indices = Tensor<Int32>(shape: [batchSize], scalars: sampledIndices)
}
That is everything we need for the ReplayBuffer class!
Full Code for the ReplayBuffer class
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
/// Replay buffer to store the agent's experiences.
///
/// Vanilla Q-learning only trains on the latest experience. Deep Q-network uses
/// a technique called "experience replay", where all experience is stored into
/// a replay buffer. By storing experience, the agent can reuse the experiences
/// and also train in batches. For more information, check Human-level control
/// through deep reinforcement learning (Mnih et al., 2015).
class ReplayBuffer {
/// The maximum size of the replay buffer. When the replay buffer is full,
/// new elements replace the oldest element in the replay buffer.
let capacity: Int
/// If enabled, uses Combined Experience Replay (CER) sampling instead of the
/// uniform random sampling in the original DQN paper. Original DQN samples
/// batch uniformly randomly in the replay buffer. CER always includes the
/// most recent element and samples the rest of the batch uniformly randomly.
/// This makes the agent more robust to different replay buffer capacities.
/// For more information about Combined Experience Replay, check A Deeper Look
/// at Experience Replay (Zhang and Sutton, 2017).
let combined: Bool
/// The states that the agent observed.
@noDerivative var states: [Tensor<Float>] = []
/// The actions that the agent took.
@noDerivative var actions: [Tensor<Int32>] = []
/// The rewards that the agent received from the environment after taking
/// an action.
@noDerivative var rewards: [Tensor<Float>] = []
/// The next states that the agent received from the environment after taking
/// an action.
@noDerivative var nextStates: [Tensor<Float>] = []
/// The episode-terminal flag that the agent received after taking an action.
@noDerivative var isDones: [Tensor<Bool>] = []
/// The current size of the replay buffer.
var count: Int { return states.count }
init(capacity: Int, combined: Bool) {
self.capacity = capacity
self.combined = combined
}
func append(
state: Tensor<Float>,
action: Tensor<Int32>,
reward: Tensor<Float>,
nextState: Tensor<Float>,
isDone: Tensor<Bool>
) {
if count >= capacity {
// Erase oldest SARS if the replay buffer is full
states.removeFirst()
actions.removeFirst()
rewards.removeFirst()
nextStates.removeFirst()
isDones.removeFirst()
}
states.append(state)
actions.append(action)
rewards.append(reward)
nextStates.append(nextState)
isDones.append(isDone)
}
func sample(batchSize: Int) -> (
stateBatch: Tensor<Float>,
actionBatch: Tensor<Int32>,
rewardBatch: Tensor<Float>,
nextStateBatch: Tensor<Float>,
isDoneBatch: Tensor<Bool>
) {
let indices: Tensor<Int32>
if self.combined == true {
// Combined Experience Replay
let sampledIndices = (0..<batchSize - 1).map { _ in Int32.random(in: 0..<Int32(count)) }
indices = Tensor<Int32>(shape: [batchSize], scalars: sampledIndices + [Int32(count) - 1])
} else {
// Vanilla Experience Replay
let sampledIndices = (0..<batchSize).map { _ in Int32.random(in: 0..<Int32(count)) }
indices = Tensor<Int32>(shape: [batchSize], scalars: sampledIndices)
}
let stateBatch = Tensor(stacking: states).gathering(atIndices: indices, alongAxis: 0)
let actionBatch = Tensor(stacking: actions).gathering(atIndices: indices, alongAxis: 0)
let rewardBatch = Tensor(stacking: rewards).gathering(atIndices: indices, alongAxis: 0)
let nextStateBatch = Tensor(stacking: nextStates).gathering(atIndices: indices, alongAxis: 0)
let isDoneBatch = Tensor(stacking: isDones).gathering(atIndices: indices, alongAxis: 0)
return (stateBatch, actionBatch, rewardBatch, nextStateBatch, isDoneBatch)
}
}
Bellman Update Equation
We defined both the neural network and the dataset it will train on. Now, let’s see how the neural network updates its weights. Specifically, let’s see how the loss is calculated.
In reinforcement learning, there are no labels: we only have unlabeled experience. As a result, we need to “bootstrap”: update values based on estimates instead of exact values from labels.
The predicted action value is simple: it is the output of the Q-network.
\[\text{Prediction} = Q(s, a)\]where $Q$ is our Q-network, $s$ is the state, and $a$ is the action.
The target action value is bootstrapped using the saved experience:
\[\text{Target} = \begin{cases} r + \gamma \max_{a'} Q(s', a') & \text{if s' is not a terminal state} \\ r & \text{if s' is a terminal state} \end{cases}\]where $r$ is the reward from the action $a$, $s’$ is the next state after the action $a$, and $\gamma$ is the discount factor to discount future rewards. If the next state is not a terminal state (i.e., if the episode is not over), we add the discounted estimate of the next state value to the reward to get the target action value.
Now, let’s translate these into S4TF. This is perhaps the most complex part, not because the prediction and the target are difficult to calculate, but because we need to batch the operation to parallelize the operation.
From the replay buffer, we have a batch of states. We pass this to the Q-network to get the Q-values
of every action for these states. Now, we want to extract the Q-values of just the selected actions.
To do this, we create a batch of index pairs (batch_index, action_index) that specify for each
experience in the batch which action was selected. Finally, we extract the Q-values using the index
pairs with Tensor.dimensionGathering(atIndices:). (This is a custom function that we developed
that will soon be added to Swift API that emulates tf.gather_nd in Python TensorFlow.)
Full Code for predictionBatch calculation
1
2
3
4
5
6
7
8
// Get Q-values
let stateQValueBatch = qNet(tfStateBatch)
// Create index pairs
let npActionBatch = tfActionBatch.makeNumpyArray()
let npFullIndices = np.stack([np.arange(batchSize, dtype: np.int32), npActionBatch], axis: 1)
let tfFullIndices = Tensor<Int32>(numpy: npFullIndices)!
// Extract the Q-values
let predictionBatch = stateQValueBatch.dimensionGathering(atIndices: tfFullIndices)
Fortunately, computing the target is much easier, because we don’t have to deal with action selection. We input the batch of next states to the Q-network. This time, we choose the highest Q-value among all the actions. We then discount the Q-value by multiplying the discount factor and add it to the reward batch to get the bootstrapped target.
Note that we need to check if the next state is a terminal state. We can simplify this process
by simply multiplying by (1 - isTerminalState). If it is a terminal state, the value is 0, so the
second term will disappear.
Full Code for targetBatch calculation
1
2
3
4
// Compute target batch
let nextStateQValueBatch = self.qNet(tfNextStateBatch).max(squeezingAxes: 1)
let targetBatch: Tensor<Float> =
tfRewardBatch + self.discount * (1 - Tensor<Float>(tfIsDoneBatch)) * nextStateQValueBatch
We want to train the Q-network so that the prediction matches the target. We use Huber loss, a variant of the $L_2$ loss with clipped gradients. The Huber loss is defined as
\[L(a) = \begin{cases} \frac{1}{2} a^2 & \text{for} |a| < \delta \\ \delta(|a| - \frac{1}{2} \delta) & \text{otherwise} \\ \end{cases}\]where $a$ is the difference between the prediction and the target, and $\delta$ is a constant.
Fortunately, calculating the Huber loss is easy, since S4TF provides a function for it!
1
huberLoss(predicted: predictionBatch, expected: targetBatch, delta: 1)
To backpropagate the loss and update the neural network, we need to encapsulate all this
code to tell S4TF to track their gradients. We use the valueWithGradient(at: ) function specifying
the network to train. Then, once the loss is computed, we can simply call optimizer.update().
Full Code for backpropagation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
let (loss, gradients) = valueWithGradient(at: qNet) { qNet -> Tensor<Float> in
// Compute prediction batch
let npActionBatch = tfActionBatch.makeNumpyArray()
let npFullIndices = np.stack(
[np.arange(batchSize, dtype: np.int32), npActionBatch], axis: 1)
let tfFullIndices = Tensor<Int32>(numpy: npFullIndices)!
let stateQValueBatch = qNet(tfStateBatch)
let predictionBatch = stateQValueBatch.dimensionGathering(atIndices: tfFullIndices)
// Compute target batch
let nextStateQValueBatch = self.qNet(tfNextStateBatch).max(squeezingAxes: 1)
let targetBatch: Tensor<Float> =
tfRewardBatch + self.discount * (1 - Tensor<Float>(tfIsDoneBatch)) * nextStateQValueBatch
return huberLoss(
predicted: predictionBatch,
expected: targetBatch,
delta: 1
)
optimizer.update(&qNet, along: gradients)
Bootstrapping allows us to train the Q-network without labels. However, it means that we update
values using estimates that keep changing. This results in high variance and hinders training.
Therefore, Deep Q-Network proposes a technique called Target Network. We keep another copy of
the Q-network that is updated at a slower rate, and use it to compute the target. In other words,
we define self.targetQNet and use it instead of self.qNet to compute the target action values.
1
2
3
let nextStateQValueBatch = self.targetQNet(tfNextStateBatch).max(squeezingAxes: 1)
let targetBatch: Tensor<Float> =
tfRewardBatch + self.discount * (1 - Tensor<Float>(tfIsDoneBatch)) * nextStateQValueBatch
In S4TF, the network can be copied simply by assignment, since a struct is passed by value.
1
2
3
func updateTargetQNet() {
self.targetQNet = self.qNet
}
Instead of updating the target network by simply copying the weights every once in a while, it is also possible to use incremental updates (also known as “soft updates”) more frequently. The update equation for soft update is
\[w^{Target} := \tau \times w + (1 - \tau) \times w^{Target}\]where $w^{Target}$ is the weight of a target network, and $w$ is the weight of the original Q-network. The $\tau$ is a constant that determines how fast the soft update is done.
1
2
3
4
5
6
7
8
9
10
func updateTargetQNet(tau: Float) {
self.targetQNet.l1.weight =
tau * Tensor<Float>(self.qNet.l1.weight) + (1 - tau) * self.targetQNet.l1.weight
self.targetQNet.l1.bias =
tau * Tensor<Float>(self.qNet.l1.bias) + (1 - tau) * self.targetQNet.l1.bias
self.targetQNet.l2.weight =
tau * Tensor<Float>(self.qNet.l2.weight) + (1 - tau) * self.targetQNet.l2.weight
self.targetQNet.l2.bias =
tau * Tensor<Float>(self.qNet.l2.bias) + (1 - tau) * self.targetQNet.l2.bias
}
Although target networks reduce variance, Hasselt, Guez, and Silver proved that it suffers from “overestimation bias.” To mitigate this bias, they suggest another improvement known as Double DQN. The Double DQN changes the calculation for the target action value $y$ as follows:
\[y^{Double DQN} = r + \gamma Q^{Target}(s', \text{argmax}_{a'} Q(s', a'))\]For reference, here is the original update equation rewritten for easier comparison:
\[y^{DQN} = r + \gamma Q(s', \text{argmax}_{a'} Q(s', a'))\]You can see that Double DQN decouples the action selection from the evaluation.
To implement Double DQN, we use a similar technique we used for computing the prediction. We use
Tensor.argmax() to select the actions according to the Q-network’s outputs. Then, we create
a batch of index pairs using these actions and use Tensor.dimensionGathering() to get the relevant
Q-value outputs from the Q-value estimates from the target network.
Full Code for DoubleDQN targetBatch calculation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
if self.doubleDQN == true {
// Double DQN
let npNextStateActionBatch = self.qNet(tfNextStateBatch).argmax(squeezingAxis: 1)
.makeNumpyArray()
let npNextStateFullIndices = np.stack(
[np.arange(batchSize, dtype: np.int32), npNextStateActionBatch], axis: 1)
let tfNextStateFullIndices = Tensor<Int32>(numpy: npNextStateFullIndices)!
nextStateQValueBatch = self.targetQNet(tfNextStateBatch).dimensionGathering(
atIndices: tfNextStateFullIndices)
} else {
// DQN
nextStateQValueBatch = self.targetQNet(tfNextStateBatch).max(squeezingAxes: 1)
}
let targetBatch: Tensor<Float> =
tfRewardBatch + self.discount * (1 - Tensor<Float>(tfIsDoneBatch)) * nextStateQValueBatch
Now, we have the code for the agent to train the Q-Network and select action using the Q-network!
We can encapsulate them into a DeepQNetworkAgent class.
Full Code for the DeepQNetworkAgent class
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
/// Agent that uses the Deep Q-Network.
///
/// Deep Q-Network is an algorithm that trains a Q-network that estimates the action values of
/// each action given an observation (state). The Q-network is trained iteratively using the
/// Bellman equation. For more information, check Human-level control through deep reinforcement
/// learning (Mnih et al., 2015).
class DeepQNetworkAgent {
/// The Q-network uses to estimate the action values.
var qNet: DeepQNetwork
/// The copy of the Q-network updated less frequently to stabilize the
/// training process.
var targetQNet: DeepQNetwork
/// The optimizer used to train the Q-network.
let optimizer: Adam<DeepQNetwork>
/// The replay buffer that stores experiences of the interactions between the
/// agent and the environment. The Q-network is trained from experiences
/// sampled from the replay buffer.
let replayBuffer: ReplayBuffer
/// The discount factor that measures how much to weight to give to future
/// rewards when calculating the action value.
let discount: Float
/// The minimum replay buffer size before the training starts.
let minBufferSize: Int
/// If enabled, uses the Double DQN update equation instead of the original
/// DQN equation. This mitigates the overestimation problem of DQN. For more
/// information about Double DQN, check Deep Reinforcement Learning with
/// Double Q-learning (Hasselt, Guez, and Silver, 2015).
let doubleDQN: Bool
let device: Device
init(
qNet: DeepQNetwork,
targetQNet: DeepQNetwork,
optimizer: Adam<DeepQNetwork>,
replayBuffer: ReplayBuffer,
discount: Float,
minBufferSize: Int,
doubleDQN: Bool,
device: Device
) {
self.qNet = qNet
self.targetQNet = targetQNet
self.optimizer = optimizer
self.replayBuffer = replayBuffer
self.discount = discount
self.minBufferSize = minBufferSize
self.doubleDQN = doubleDQN
self.device = device
// Copy Q-network to Target Q-network before training
updateTargetQNet(tau: 1)
}
func getAction(state: Tensor<Float>, epsilon: Float) -> Tensor<Int32> {
if Float(np.random.uniform()).unwrapped() < epsilon {
return Tensor<Int32>(numpy: np.array(np.random.randint(0, 2), dtype: np.int32))!
} else {
// Neural network input needs to be 2D
let tfState = Tensor<Float>(numpy: np.expand_dims(state.makeNumpyArray(), axis: 0))!
let qValues = qNet(tfState)[0]
return Tensor<Int32>(qValues[1].scalarized() > qValues[0].scalarized() ? 1 : 0, on: device)
}
}
func train(batchSize: Int) -> Float {
// Don't train if replay buffer is too small
if replayBuffer.count >= minBufferSize {
let (tfStateBatch, tfActionBatch, tfRewardBatch, tfNextStateBatch, tfIsDoneBatch) =
replayBuffer.sample(batchSize: batchSize)
let (loss, gradients) = valueWithGradient(at: qNet) { qNet -> Tensor<Float> in
// Compute prediction batch
let npActionBatch = tfActionBatch.makeNumpyArray()
let npFullIndices = np.stack(
[np.arange(batchSize, dtype: np.int32), npActionBatch], axis: 1)
let tfFullIndices = Tensor<Int32>(numpy: npFullIndices)!
let stateQValueBatch = qNet(tfStateBatch)
let predictionBatch = stateQValueBatch.dimensionGathering(atIndices: tfFullIndices)
// Compute target batch
let nextStateQValueBatch: Tensor<Float>
if self.doubleDQN == true {
// Double DQN
let npNextStateActionBatch = self.qNet(tfNextStateBatch).argmax(squeezingAxis: 1)
.makeNumpyArray()
let npNextStateFullIndices = np.stack(
[np.arange(batchSize, dtype: np.int32), npNextStateActionBatch], axis: 1)
let tfNextStateFullIndices = Tensor<Int32>(numpy: npNextStateFullIndices)!
nextStateQValueBatch = self.targetQNet(tfNextStateBatch).dimensionGathering(
atIndices: tfNextStateFullIndices)
} else {
// DQN
nextStateQValueBatch = self.targetQNet(tfNextStateBatch).max(squeezingAxes: 1)
}
let targetBatch: Tensor<Float> =
tfRewardBatch + self.discount * (1 - Tensor<Float>(tfIsDoneBatch)) * nextStateQValueBatch
return huberLoss(
predicted: predictionBatch,
expected: targetBatch,
delta: 1
)
}
optimizer.update(&qNet, along: gradients)
return loss.scalarized()
}
return 0
}
func updateTargetQNet(tau: Float) {
self.targetQNet.l1.weight =
tau * Tensor<Float>(self.qNet.l1.weight) + (1 - tau) * self.targetQNet.l1.weight
self.targetQNet.l1.bias =
tau * Tensor<Float>(self.qNet.l1.bias) + (1 - tau) * self.targetQNet.l1.bias
self.targetQNet.l2.weight =
tau * Tensor<Float>(self.qNet.l2.weight) + (1 - tau) * self.targetQNet.l2.weight
self.targetQNet.l2.bias =
tau * Tensor<Float>(self.qNet.l2.bias) + (1 - tau) * self.targetQNet.l2.bias
}
}
Environment
Now, we want to train this agent! The agent needs an environment to interact with. In Python, the OpenAI Gym has been the de-facto standard. S4TF allows using Python libraries, so we can borrow Gym from Python. However, the library still outputs Python variables as output, so we need to convert them to Swift variables to use them.
To simplify the process, we build an environment wrapper. This wrapper encapsulates the Python Gym environment and converts all its outputs to Swift natives.
Full Code for TensorFlowEnvironmentWrapper class
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class TensorFlowEnvironmentWrapper {
let originalEnv: PythonObject
init(_ env: PythonObject) {
self.originalEnv = env
}
func reset() -> Tensor<Float> {
let state = self.originalEnv.reset()
return Tensor<Float>(numpy: np.array(state, dtype: np.float32))!
}
func step(_ action: Tensor<Int32>) -> (
state: Tensor<Float>, reward: Tensor<Float>, isDone: Tensor<Bool>, info: PythonObject
) {
let (state, reward, isDone, info) = originalEnv.step(action.scalarized()).tuple4
let tfState = Tensor<Float>(numpy: np.array(state, dtype: np.float32))!
let tfReward = Tensor<Float>(numpy: np.array(reward, dtype: np.float32))!
let tfIsDone = Tensor<Bool>(numpy: np.array(isDone, dtype: np.bool))!
return (tfState, tfReward, tfIsDone, info)
}
}
With this, our environment is ready!
Train and Evaluate
Now, all that is left to do is to connect all the pieces. For the agent to train, the agent must
- Select action $\varepsilon$-greedily
- Interact with the environment using selected action
- Save interaction to the replay buffer
- Update weights using a minibatch sampled from the replay buffer
- Periodically update target network
and repeat the process.
Using all the S4TF we wrote, we can do all this in just a few lines of code!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
var state = env.reset()
while ... {
// Step 1: Action selection
let epsilon: Float =
epsilonEnd + (epsilonStart - epsilonEnd) * exp(-1.0 * Float(stepIndex) / epsilonDecay)
let action = agent.getAction(state: state, epsilon: epsilon)
// Step 2: Interact
let (nextState, reward, isDone, _) = env.step(action)
// Step 3: Save interaction
replayBuffer.append(
state: state, action: action, reward: reward, nextState: nextState, isDone: isDone)
// Step 4: Train agent
losses.append(agent.train(batchSize: batchSize))
// Step 5: Update target network
if stepIndex % targetNetUpdateRate == 0 {
agent.updateTargetQNet(tau: softTargetUpdateRate)
}
// End-of-episode
if isDone.scalarized() == true {
state = env.reset()
}
// End-of-step
state = nextState
}
We skipped hyperparameter and variable initializations and some logging, but that is all the code we need for Deep Q-Network!
Variable Initialization Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
// Hyperparameters
/// The size of the hidden layer of the 2-layer Q-network. The network has the
/// shape observationSize - hiddenSize - actionCount.
let hiddenSize: Int = 100
/// Maximum number of episodes to train the agent. The training is terminated
/// early if maximum score is achieved during evaluation.
let maxEpisode: Int = 1000
/// The initial epsilon value. With probability epsilon, the agent chooses a
/// random action instead of the action that it thinks is the best.
let epsilonStart: Float = 1
/// The terminal epsilon value.
let epsilonEnd: Float = 0.01
/// The decay rate of epsilon.
let epsilonDecay: Float = 1000
/// The learning rate for the Q-network.
let learningRate: Float = 0.001
/// The discount factor. This measures how much to "discount" the future rewards
/// that the agent will receive. The discount factor must be from 0 to 1
/// (inclusive). Discount factor of 0 means that the agent only considers the
/// immediate reward and disregards all future rewards. Discount factor of 1
/// means that the agent values all rewards equally, no matter how distant
/// in the future they may be.
let discount: Float = 0.99
/// If enabled, uses the Double DQN update equation instead of the original DQN
/// equation. This mitigates the overestimation problem of DQN. For more
/// information about Double DQN, check Deep Reinforcement Learning with Double
/// Q-learning (Hasselt, Guez, and Silver, 2015).
let useDoubleDQN: Bool = true
/// The maximum size of the replay buffer. If the replay buffer is full, the new
/// element replaces the oldest element.
let replayBufferCapacity: Int = 100000
/// The minimum replay buffer size before the training starts. Must be at least
/// the training batch size.
let minBufferSize: Int = 64
/// The training batch size.
let batchSize: Int = 64
/// If enabled, uses Combined Experience Replay (CER) sampling instead of the
/// uniform random sampling in the original DQN paper. Original DQN samples
/// batch uniformly randomly in the replay buffer. CER always includes the most
/// recent element and samples the rest of the batch uniformly randomly. This
/// makes the agent more robust to different replay buffer capacities. For more
/// information about Combined Experience Replay, check A Deeper Look at
/// Experience Replay (Zhang and Sutton, 2017).
let useCombinedExperienceReplay: Bool = true
/// The number of steps between target network updates. The target network is
/// a copy of the Q-network that is updated less frequently to stabilize the
/// training process.
let targetNetUpdateRate: Int = 5
/// The update rate for target network. In the original DQN paper, the target
/// network is updated to be the same as the Q-network. Soft target network
/// only updates the target network slightly towards the direction of the
/// Q-network. The softTargetUpdateRate of 0 means that the target network is
/// not updated at all, and 1 means that soft target network update is disabled.
let softTargetUpdateRate: Float = 0.05
// Setup device
let device: Device = Device.default
// Initialize environment
let env = TensorFlowEnvironmentWrapper(gym.make("CartPole-v0"))
// Initialize agent
var qNet = DeepQNetwork(observationSize: 4, hiddenSize: hiddenSize, actionCount: 2)
var targetQNet = DeepQNetwork(observationSize: 4, hiddenSize: hiddenSize, actionCount: 2)
let optimizer = Adam(for: qNet, learningRate: learningRate)
var replayBuffer = ReplayBuffer(
capacity: replayBufferCapacity,
combined: useCombinedExperienceReplay
)
var agent = DeepQNetworkAgent(
qNet: qNet,
targetQNet: targetQNet,
optimizer: optimizer,
replayBuffer: replayBuffer,
discount: discount,
minBufferSize: minBufferSize,
doubleDQN: useDoubleDQN,
device: device
)
Full Code for the RL Loop
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
func evaluate(_ agent: DeepQNetworkAgent) -> Float {
let evalEnv = TensorFlowEnvironmentWrapper(gym.make("CartPole-v0"))
var evalEpisodeReturn: Float = 0
var state: Tensor<Float> = evalEnv.reset()
var reward: Tensor<Float>
var evalIsDone: Tensor<Bool> = Tensor<Bool>(false)
while evalIsDone.scalarized() == false {
let action = agent.getAction(state: state, epsilon: 0)
(state, reward, evalIsDone, _) = evalEnv.step(action)
evalEpisodeReturn += reward.scalarized()
}
return evalEpisodeReturn
}
// RL Loop
var stepIndex = 0
var episodeIndex = 0
var episodeReturn: Float = 0
var episodeReturns: [Float] = []
var losses: [Float] = []
var state = env.reset()
var bestReturn: Float = 0
while episodeIndex < maxEpisode {
stepIndex += 1
// Interact with environment
let epsilon: Float =
epsilonEnd + (epsilonStart - epsilonEnd) * exp(-1.0 * Float(stepIndex) / epsilonDecay)
let action = agent.getAction(state: state, epsilon: epsilon)
let (nextState, reward, isDone, _) = env.step(action)
episodeReturn += reward.scalarized()
// Save interaction to replay buffer
replayBuffer.append(
state: state, action: action, reward: reward, nextState: nextState, isDone: isDone)
// Train agent
losses.append(agent.train(batchSize: batchSize))
// Periodically update Target Net
if stepIndex % targetNetUpdateRate == 0 {
agent.updateTargetQNet(tau: softTargetUpdateRate)
}
// End-of-episode
if isDone.scalarized() == true {
state = env.reset()
episodeIndex += 1
let evalEpisodeReturn = evaluate(agent)
episodeReturns.append(evalEpisodeReturn)
if evalEpisodeReturn > bestReturn {
print(
String(
format: "Episode: %4d | Step %6d | Epsilon: %.03f | Train: %3d | Eval: %3d", episodeIndex,
stepIndex, epsilon, Int(episodeReturn), Int(evalEpisodeReturn)))
bestReturn = evalEpisodeReturn
}
if evalEpisodeReturn > 199 {
print("Solved in \(episodeIndex) episodes with \(stepIndex) steps!")
break
}
episodeReturn = 0
}
// End-of-step
state = nextState
}
// Save learning curve
plt.plot(episodeReturns)
plt.title("Deep Q-Network on CartPole-v0")
plt.xlabel("Episode")
plt.ylabel("Episode Return")
plt.savefig("/tmp/dqnEpisodeReturns.png")
plt.clf()
Conclusion
We now have a working Deep Q-Network agent! We tested this on CartPole-v0, a simple environment with the goal of balancing a pole on top of a cart by moving the cart left or right. It is a widely used environment for some basic tests, as the environment is simple and the simulator is fast. The maximum cumulative reward is 200.

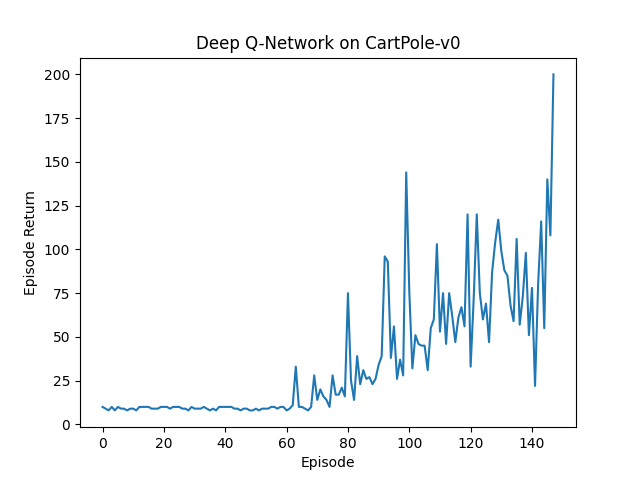
The Deep Q-Network agent consistently achieves the maximum score in 100-200 episodes. However, you can see that its performance is quite unstable. In the next post, we will discuss Proximal Policy Optimization (PPO), another reinforcement learning algorithm that is more stable.
You can find the entire code at
tensorflow/swift-models repository in GitHub
and the appropriate PR. Download the code and run
swift run Gym-DQN to try it yourself!

