All Stories
Using TensorBoard with PyTorch 1.1+
Since PyTorch 1.1, tensorboard is now natively supported in PyTorch. This post contains detailed instuctions to install tensorboard.
Collapsible Code Blocks in GitHub Pages
Here is a quick guide on using collapsible code blocks in GitHub pages. This might be useful when there is a large output that might...
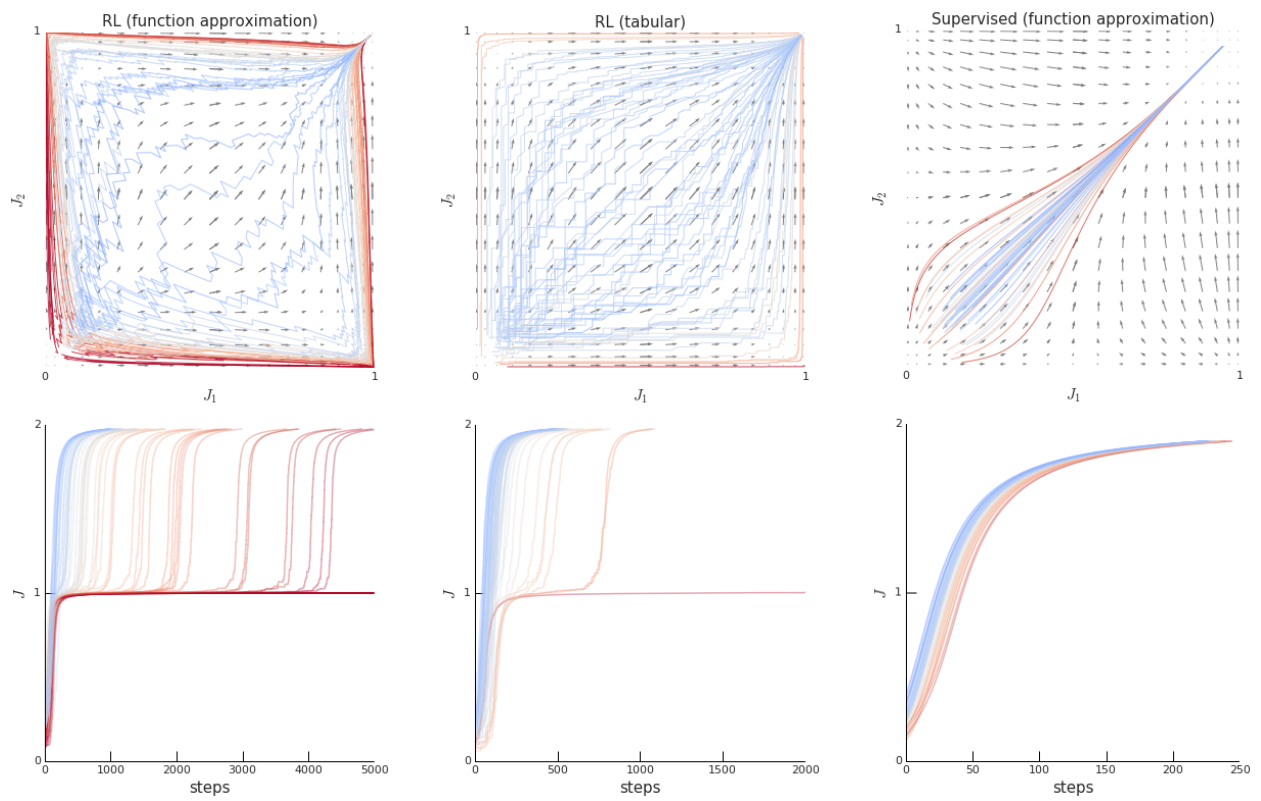
RL Weekly 16: Why Performance Plateaus May Occur, and Compressing DQNs
In this issue, we introduce 'ray interference,' a possible cause of performance plateaus in deep reinforcement learning conjectured by Google DeepMind. We also introduce a...
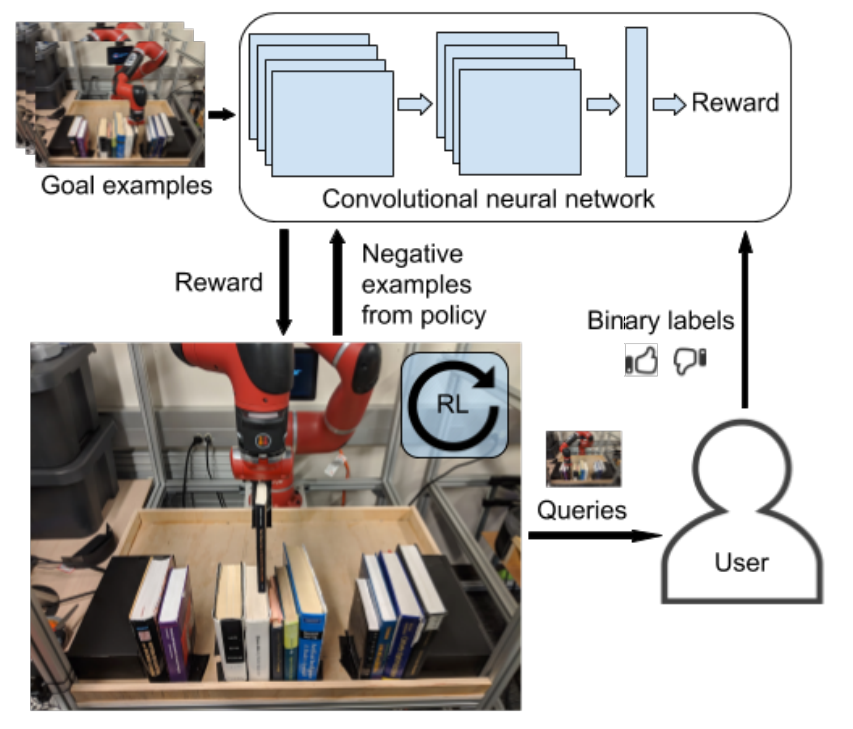
RL Weekly 15: Learning without Rewards: from Active Queries or Suboptimal Demonstrations
In this issue, we introduce VICE-RAQ by UC Berkeley and T-REX by UT Austin and Preferred Networks. VICE-RAQ trains a classifier to infer rewards from...

RL Weekly 14: OpenAI Five and Berkeley Blue
In this week's issue, we summarize the Dota 2 match between OpenAI Five and OG eSports and introduce Blue, a new low-cost robot developed by...
