All Stories

RL Weekly 31: How Agents Play Hide and Seek, Attraction-Repulsion Actor Critic, and Efficient Learning from Demonstrations
In this issue, we look at OpenAI's work on multi-agent hide and seek and the behaviors that emerge. We also look at Mila's population-based exploration...

Reinforcement Learning Papers Accepted to NeurIPS 2019
I have compiled a list of 184 reinforcement learning papers accepted to NeurIPS 2019.
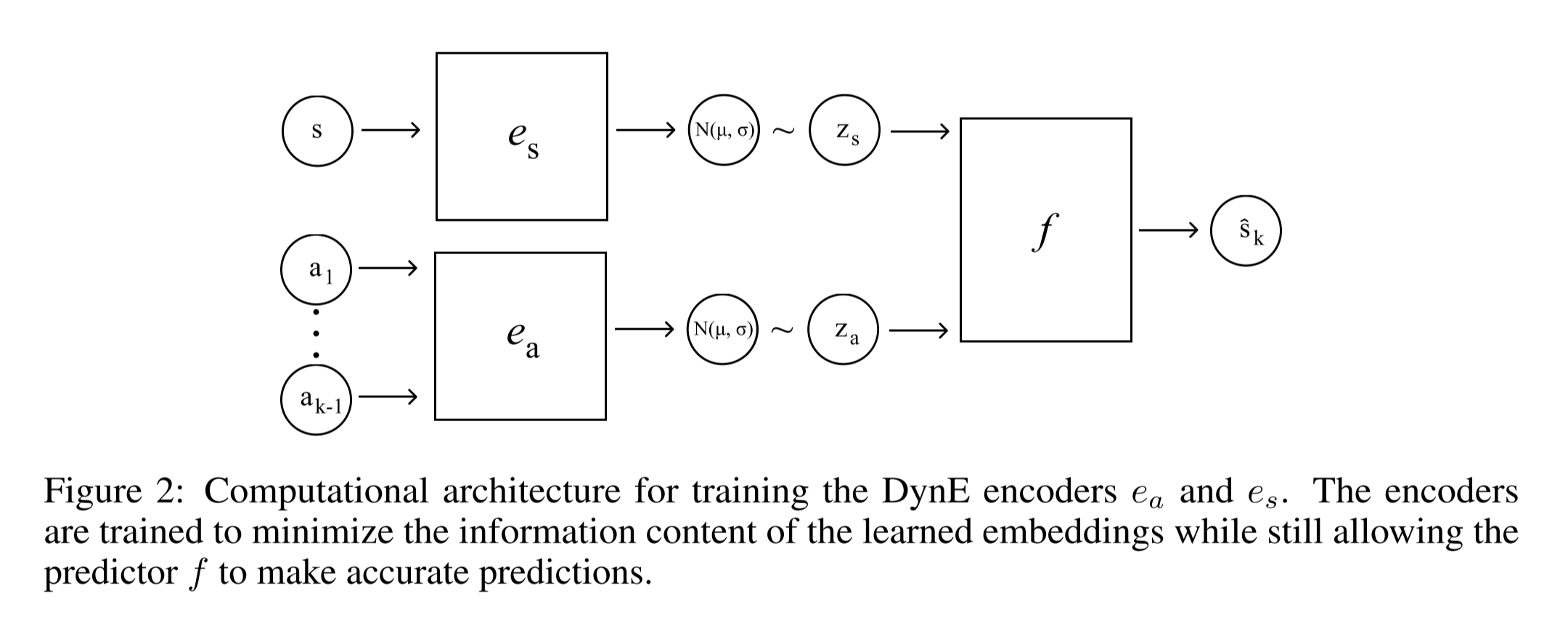
RL Weekly 30: Learning State and Action Embeddings, a New Framework for RL in Games, and an Interactive Variant of Question Answering
In this issue, we look at a representation learning method to train state and action embeddings paired with TD3. We also look at a new...

githubtocolab: Open GitHub Jupyter Notebooks in Colab!
GitHub is a great place to host jupyter notebooks, and Colab is a great place to run jupyter notebooks. Use githubtocolab.com to instantly open jupyter...
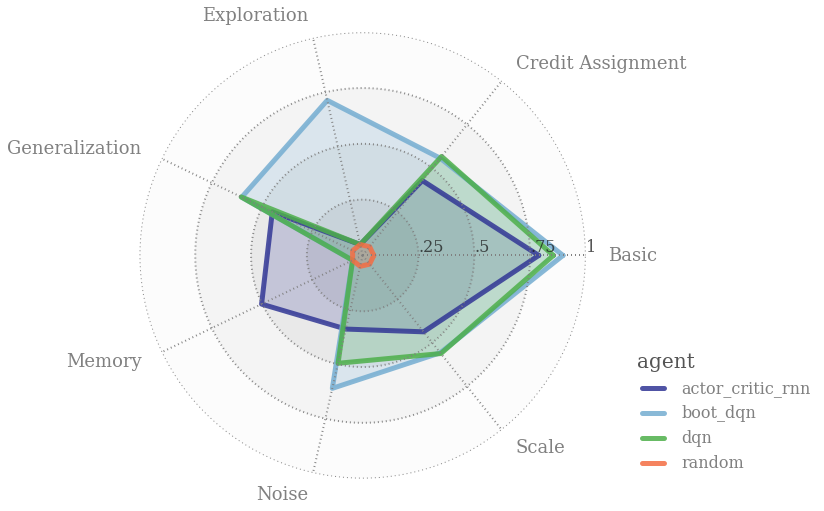
RL Weekly 29: The Behaviors and Superstitions of RL, and How Deep RL Compares with the Best Humans in Atari
In this issue, we look at reinforcement learning from a wider perspective. We look at new environments and experiments that are designed to test and...
