All Stories

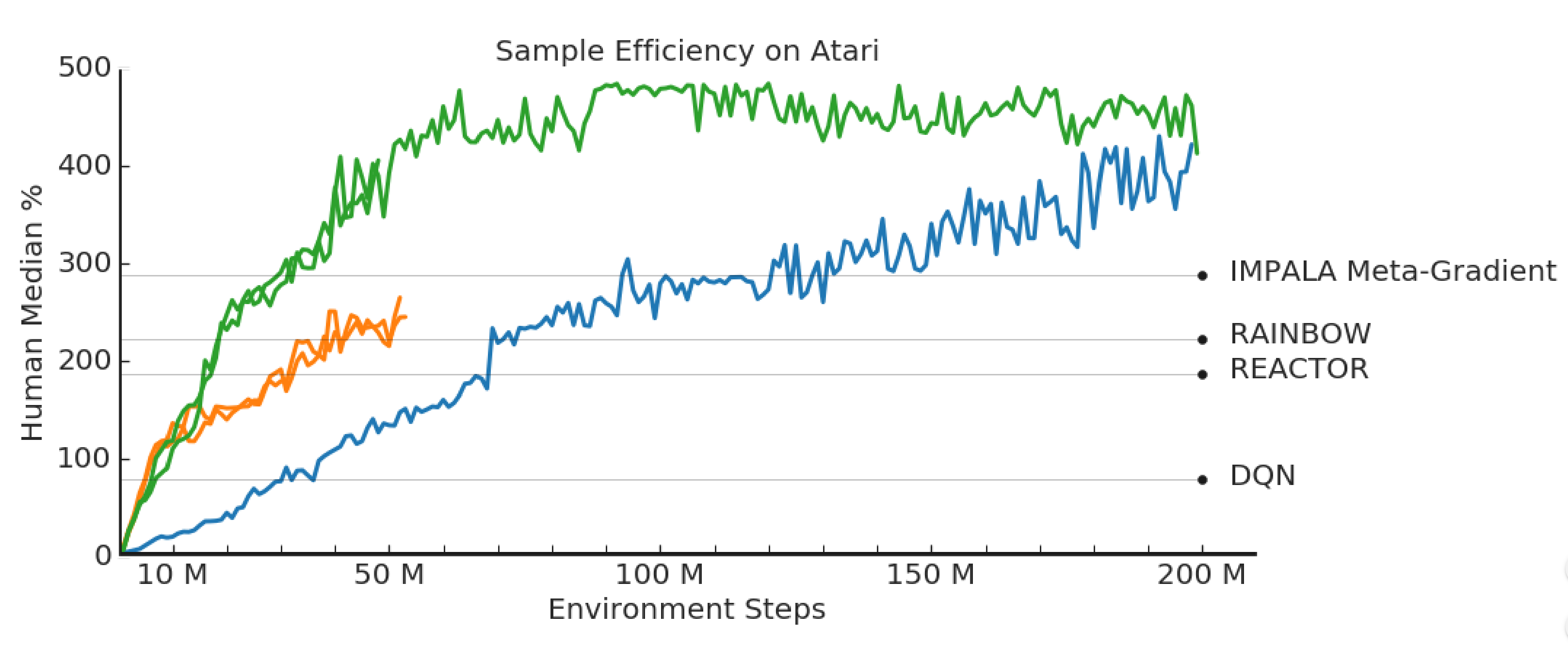
RL Weekly 37: Observational Overfitting, Hindsight Credit Assignment, and Procedurally Generated Environment Suite
In this issue, we look at Google and MIT's study on the observational overfitting phenomenon and how overparametrization helps generalization, a new family of algorithms...

RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
In this issue, we look at MuZero, DeepMind's new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves...
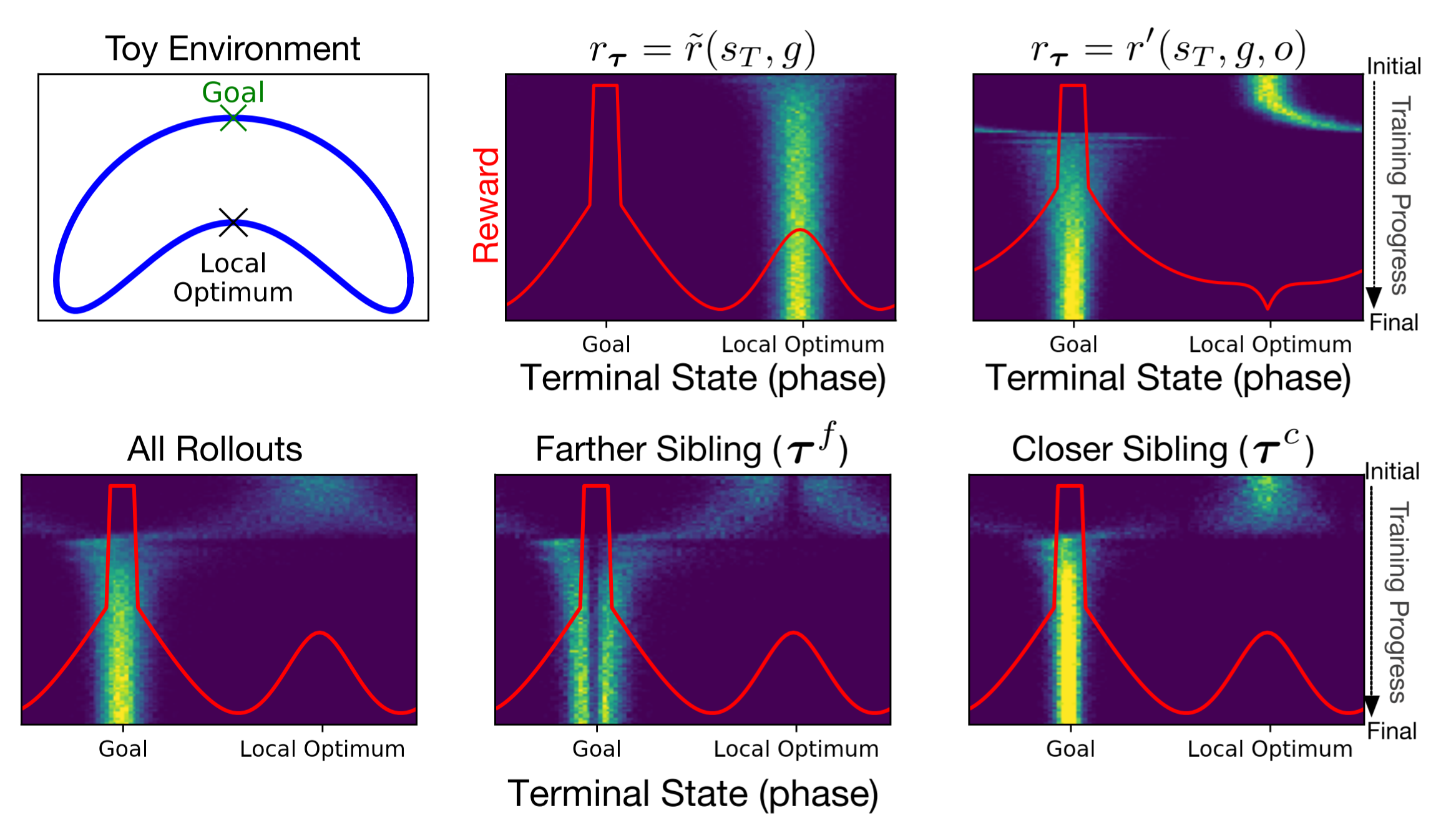
RL Weekly 35: Escaping Local Optimas in Distance-based Rewards and Choosing the Best Teacher
In this issue, we look at an algorithm that use sibling trajectories to escape local optimas in distance-based shaped rewards, and an algorithm that dynamically...

RL Weekly 34: Dexterous Manipulation of the Rubik's Cube and Human-Agent Collaboration in Overcooked
In this issue, we look at a robot hand manipulating and "solving" the Rubik's Cube. We also look at comparative performances of human-agnostic and human-aware...
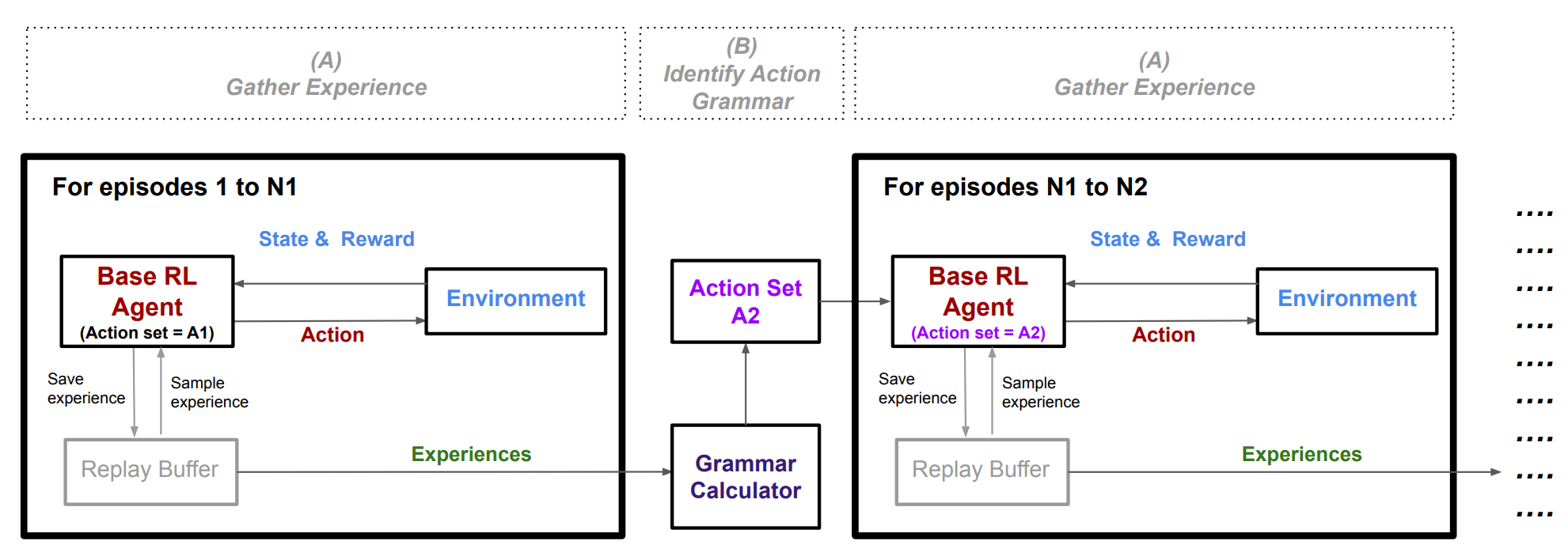
RL Weekly 33: Action Grammar, the Squashing Exploration Problem, and Task-relevant GAIL
In this issue, we look at Action Grammar RL, a hierarchical RL framework that adds new macro-actions, improving performance of DDQN and SAC in Atari...