All Stories
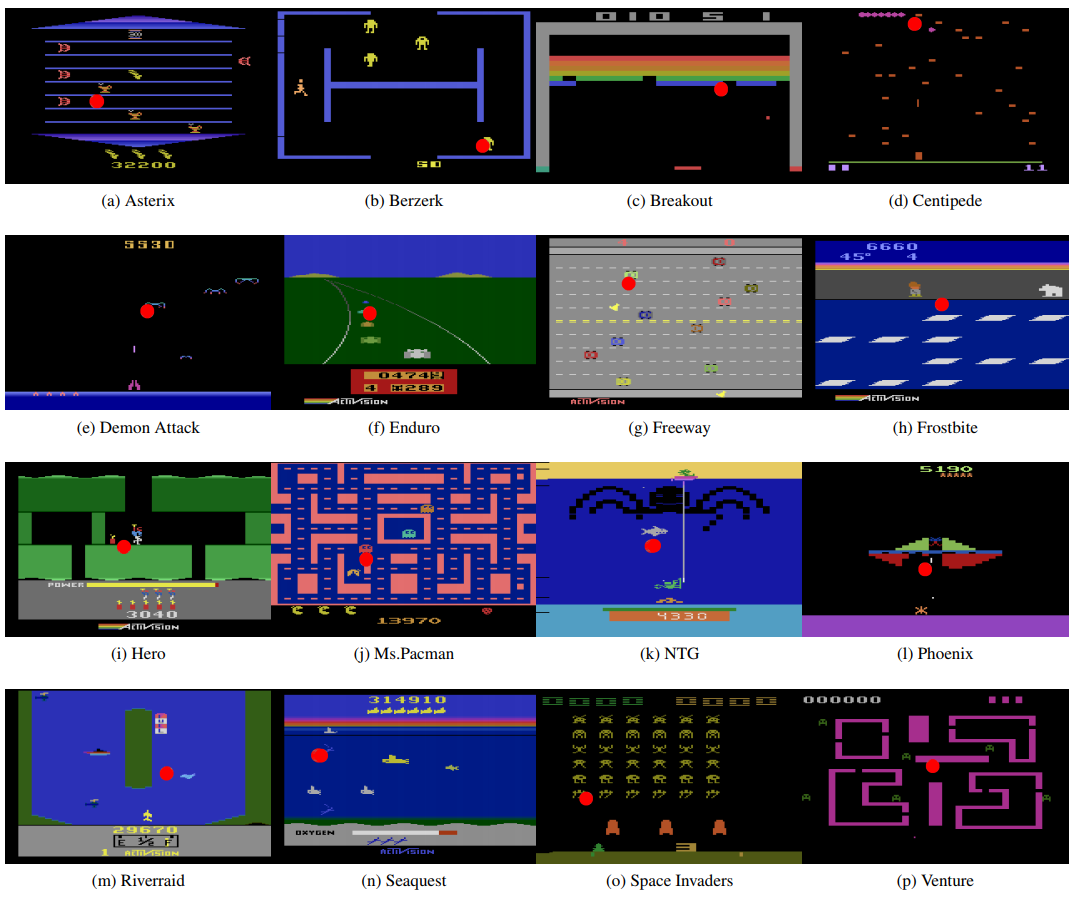
RL Weekly 12: Atari Demos with Human Gaze Labels, New SOTA in Meta-RL, and a Hierarchical Take on Intrinsic Rewards
This week, we look at a new demo dataset of Atari games that include trajectories and human gaze. We also look at PEARL, a new...
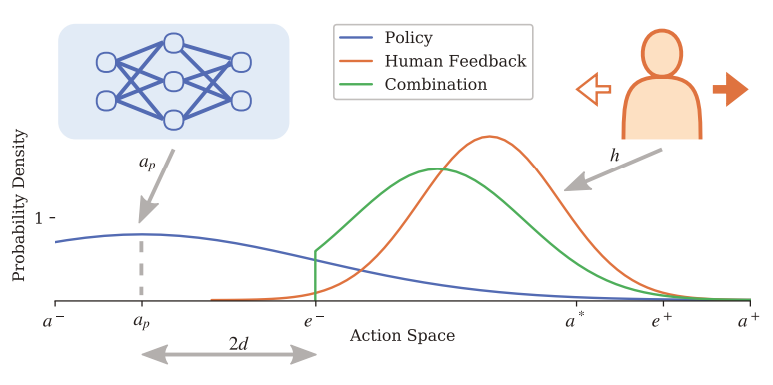
RL Weekly 11: The Bitter Lesson by Richard Sutton, the Promise of Hierarchical RL, and Exploration with Human Feedback
In this issue, we first look at a diary entry by Richard S. Sutton (DeepMind, UAlberta) on Compute versus Clever. Then, we look at a...

RL Weekly 10: Learning from Playing, Understanding Multi-agent Intelligence, and Navigating in Google Street View
In this issue, we look at Google Brain's algorithm of learning by playing, DeepMind's thoughts on multi-agent intelligence, and DeepMind's new navigation environment using Google...
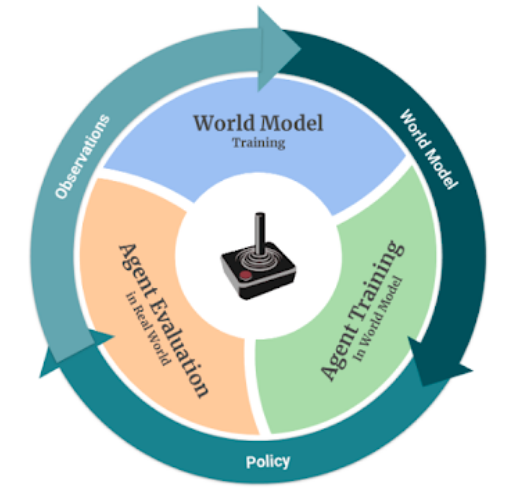
RL Weekly 9: Sample-efficient Near-SOTA Model-based RL, Neural MMO, and Bottlenecks in Deep Q-Learning
In this issue, we look at SimPLe, a model-based RL algorithm that achieves near-state-of-the-art results on Arcade Learning Environments (ALE). We also look at Neural...
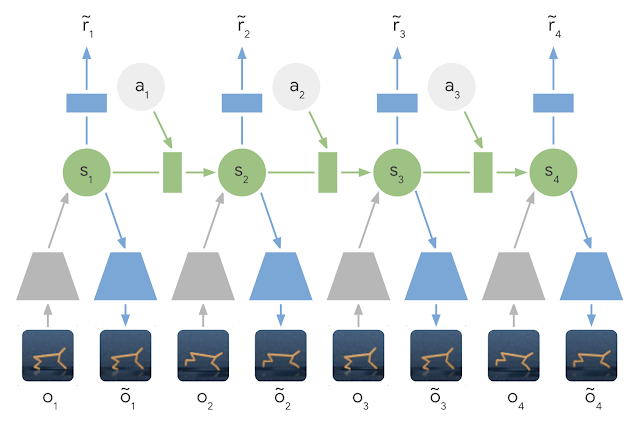
RL Weekly 8: World Discovery Models, MuJoCo Soccer Environment, and Deep Planning Network
In this issue, we introduce World Discovery Models and MuJoCo Soccer Environment from Google DeepMind, and PlaNet from Google.