All Stories
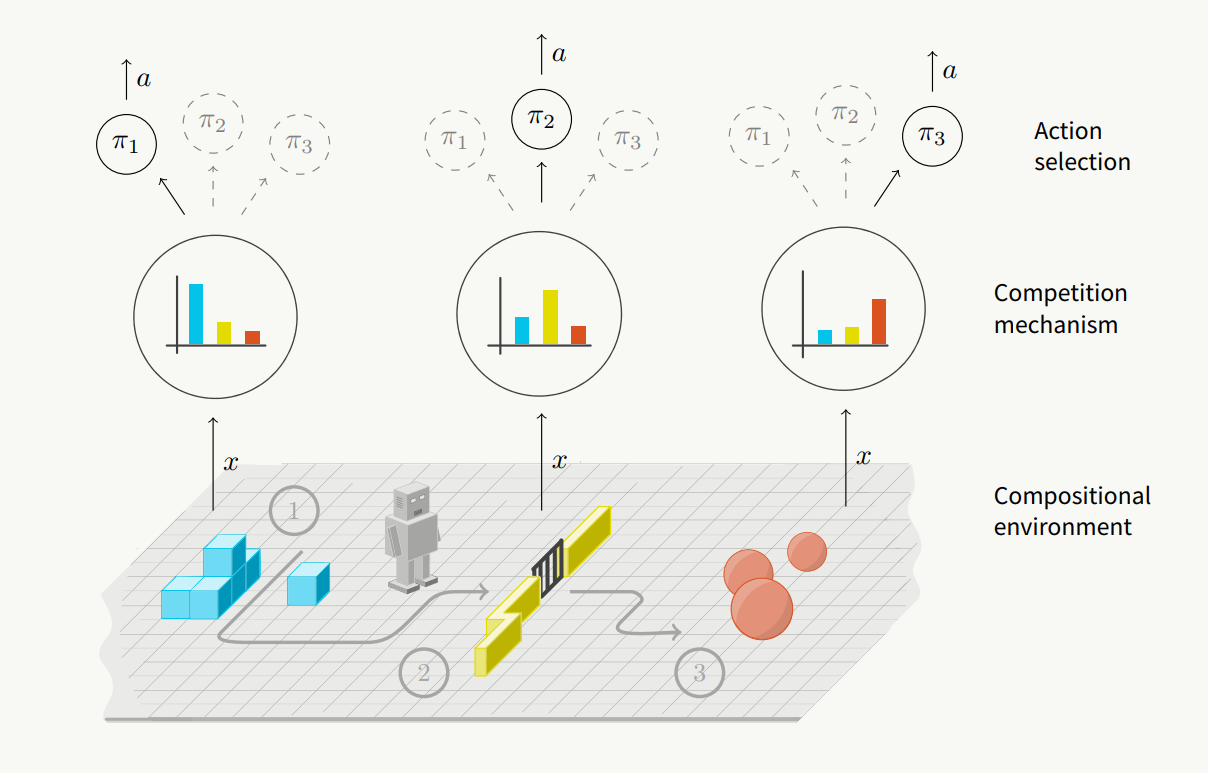
RL Weekly 27: Diverse Trajectory-conditioned Self Imitation Learning and Environment Probing Interaction Policies
This week, we look at a self imitation learning method that imitates diverse past experience for better exploration. We also summarize an environment probing policy...
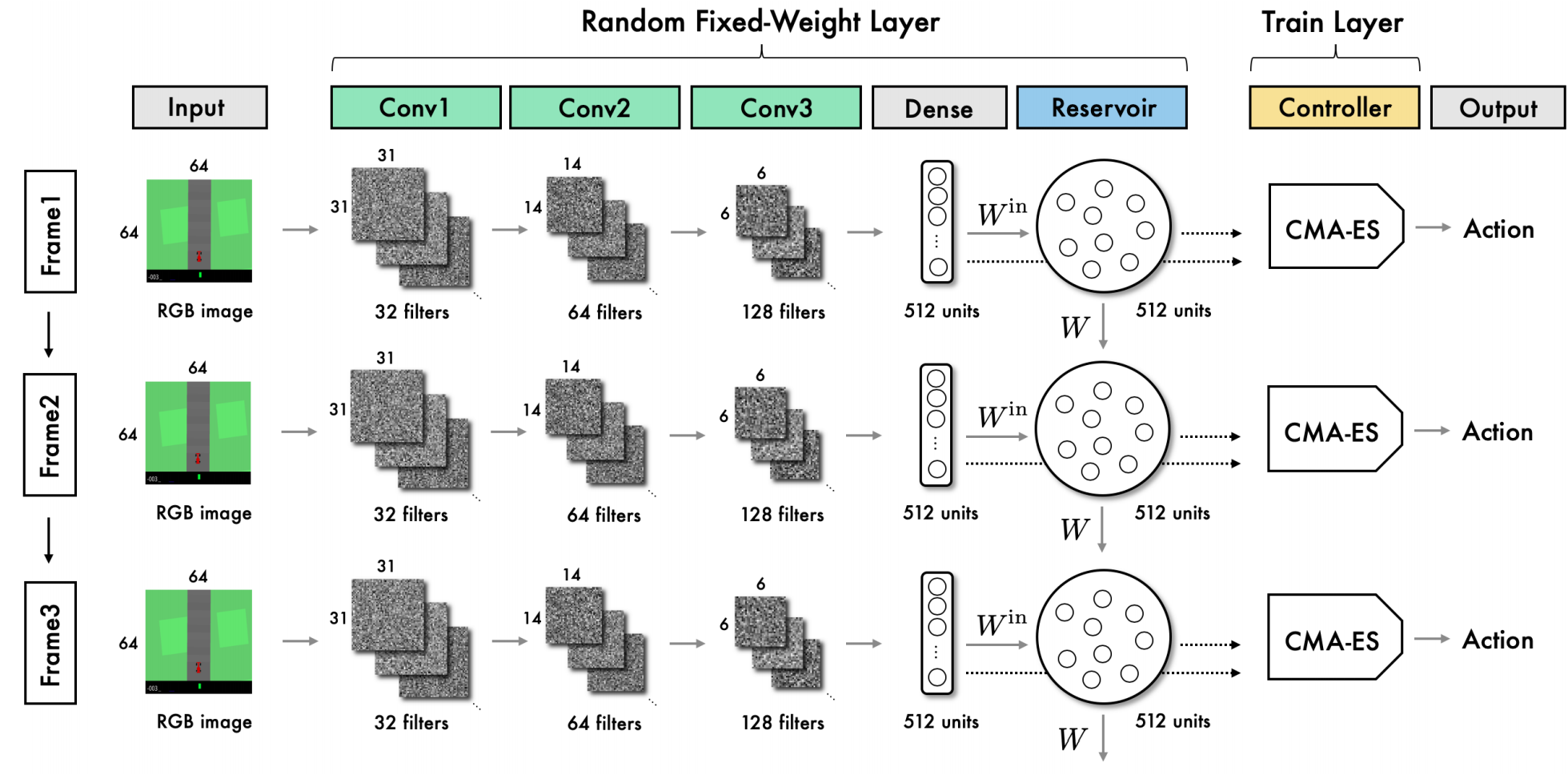
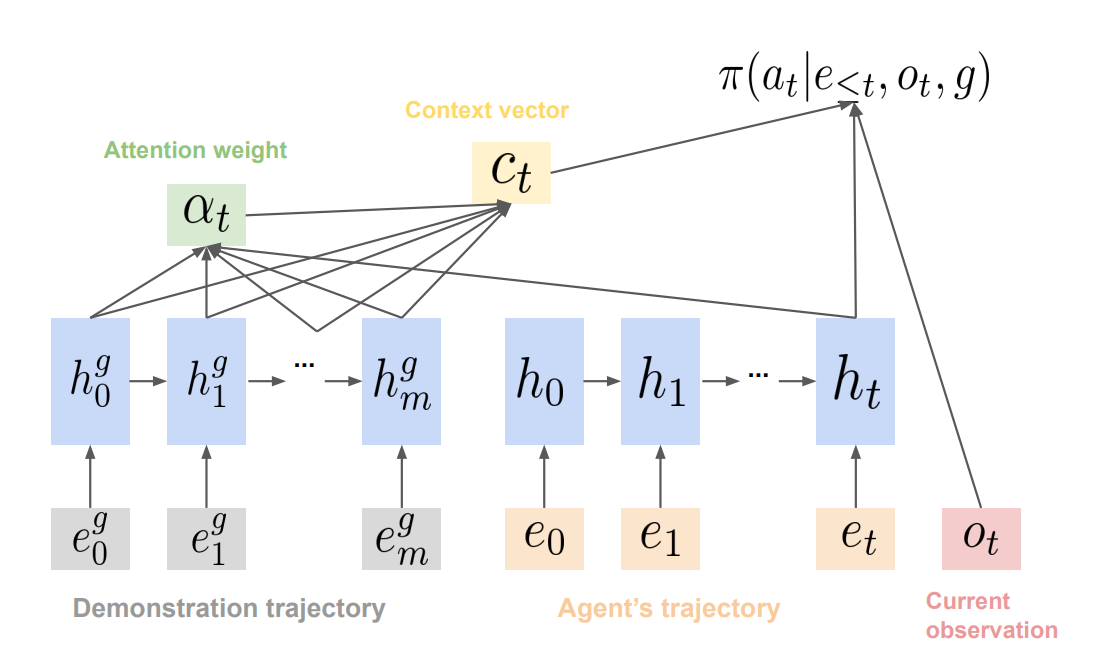
RL Weekly 26: Transfer RL with Credit Assignment and Convolutional Reservoir Computing for World Models
This week, we summarize a new transfer learning method using the Transformer reward model, and a world model controller that does not require training the...
Setting up code-server on GCP: VSCode on Browser for Remote Work!
Visual Studio Code (VS Code) is a great code editor, but it cannot be used remotely... or can it? Code-server is VS Code running on...
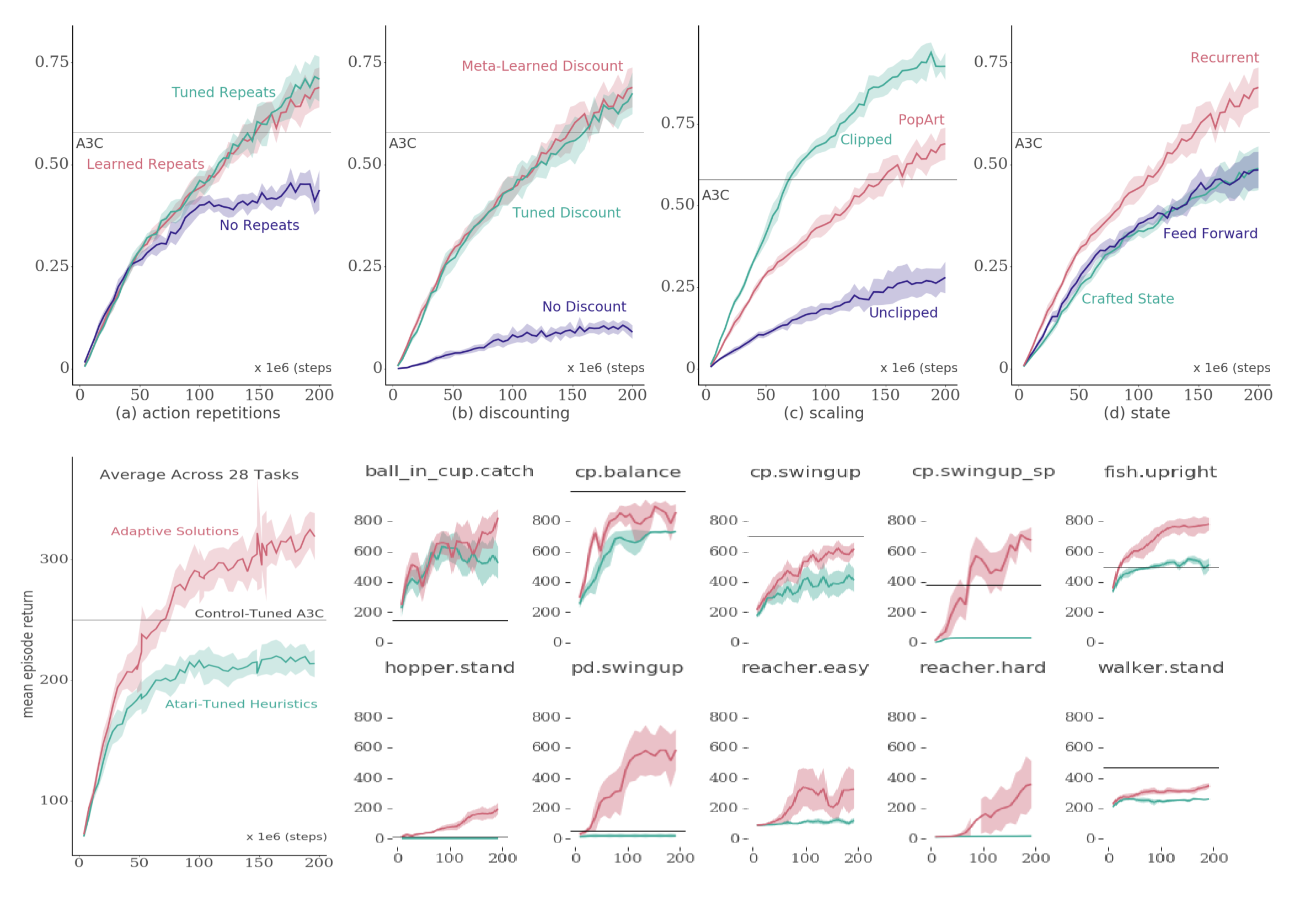
RL Weekly 25: Replacing Bias with Adaptive Methods, Batch Off-policy Learning, and Learning Shared Model for Multi-task RL
In this issue, we focus on replacing inductive bias with adaptive solutions (DeepMind), learning off-policy from expert experience (Google Brain), and learning a shared model...
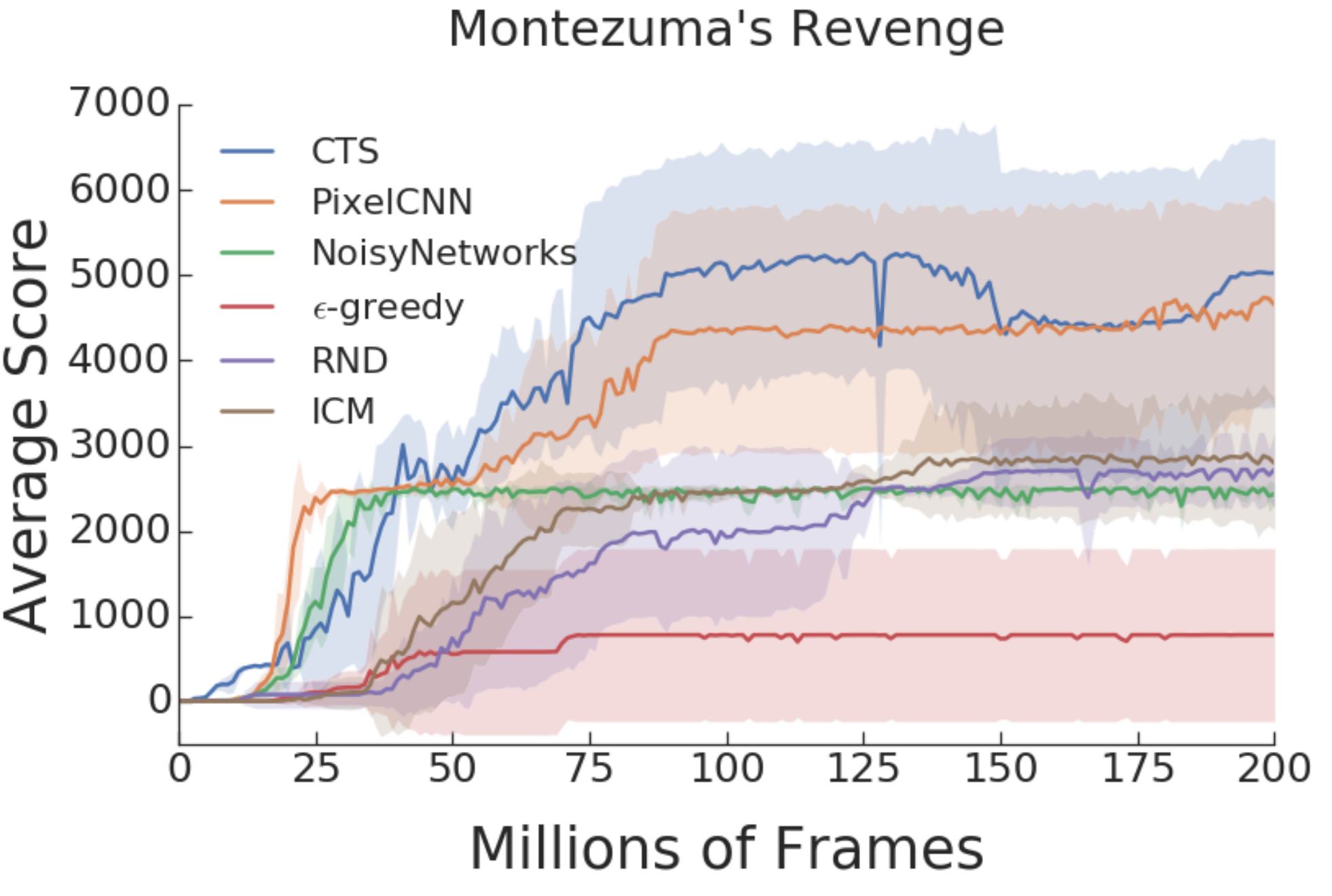
RL Weekly 24: Benchmarks for Model-based RL and Bonus-based Exploration Methods
This week, we summarize two benchmark papers. The first paper benchmarks 11 model-based RL algorithms in 18 continuous control environments, and the second paper benchmarks...